跨语言代码搜索方法、终端设备及存储介质
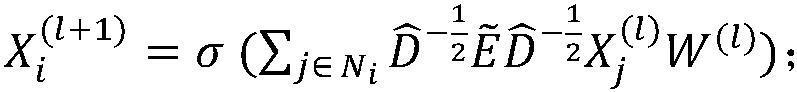
本发明涉及跨语言代码搜索技术,特别是一种基于对比学习的跨语言代码搜索方法、终端设备及存储介质。
背景技术:
1、在跨语言代码搜索任务中,开发人员以某种编程语言的代码片段作为查询意图。该任务是根据用户输入的代码片段,从代码库中搜索到与其功能相似的相同及不同编程语言的代码片段。
2、目前,跨语言代码检索受到的关注度较低,现有的研究并不多。早期的跨语言代码搜索一般采用信息检索的方法。kim等人提出的facoy为用户输入的代码片段生成了对应的结构化查询语句,通过该查询语句搜索最相似的代码片段的问答帖子,并根据问答帖子中的额外信息来搜索最佳代码片段。luan等人首先对用户输入的代码片段提取结构特征,并通过比较特征的重叠程度返回一系列代码片段,之后通过重排序和聚类算法,获得高质量的搜索结果。mathew等人使用了代码片段的序列信息、结构信息和行为信息,并结合了代码片段的静态和动态分析,以返回目标代码片段。上述方法的实现都较为复杂,并且人工设计的匹配特征和排序算法存在局限性,不易进行扩展。此外,这些方法大多是针对一种编程语言的,在跨语言代码搜索上表现不佳。
3、随着深度学习在基于自然语言的代码搜索上的成功,越来越多研究人员开始将深度学习运用在跨语言代码搜索中。最近,bui等人提出了bi-nn框架来学习两种不同编程语言的代码语义,它使用两个相同的网络结构来训练两个用于不同编程语言的代码编码器。虽然该方法可以提取跨语言代码表示,但是该方法相当于要为每一种编程语言都要训练一个代码编码器,可扩展性不强。bui等人提出的infercode通过自监督学习的方法自动提取出从ast中提取的子树作为标签,通过tbcnn模型来训练代码片段编码器,将代码片段编码成向量,进一步实现跨语言的代码检索。然而,该方法没有考虑到不同编程语言之间ast的差异,因此很难获取不同编程语言代码片段之间的共性。chen等人使用自编码器结构并结合用户反馈,提出了交互式的跨语言代码搜索模型。lin等人以基于elmo增强的变分自编码器为基础,为每种编程语言训练出一个代码表示模型,并使用知识蒸馏的方法,训练出可以支持多种编程语言的源代码编码器来实现跨语言的代码搜索。该方法的本质也是需要训练多个编程语言的表示模型,实现起来较为复杂。
4、综上所述,跨语言代码搜索任务还处于起步阶段。以信息检索为基础的方法大多存在扩展性差,仅支持单一编程语言的问题。而基于深度学习的大部分研究都是对每一种编程语言分别训练一个编码器,在实际的搜索过程中挑选出需要的编程语言对应的编码器,对查询代码片段和代码库中的代码片段分别编码。这些方法都存在模型的训练复杂,可扩展性差等问题。此外,基于深度学习的方法还是按照基于自然语言的代码搜索的思路进行研究的,直接将代码片段进行编码,而没有考虑到不同编程语言之间语法和结构的差异,导致模型对不同编程语言但是功能相同的代码片段的区分能力较差。
5、跨语言代码搜索是指用一种编程语言的代码片段,在代码库中搜索到其他语言并且功能与查询代码片段相似的代码。如图1(a)~图1(c)所示,开发人员用java语言的具有输出给定数字的阶乘功能的代码片段搜索到python和javascript语言的代码片段。在这三种编程语言的代码片段中,它们的语法和结构不同,但在语义上是相同的。因此,跨语言的代码搜索可以减少在不同编程语言中实现相同功能的时间,还能在代码复用和代码迁移上进行运用,提升开发人员的效率。
6、现有的基于自然语言的代码搜索通常是针对查询语句和目标代码片段分别训练一个编码器,而在跨语言的代码搜索中,查询意图和目标都是代码片段,我们希望用一个编码器来提取代码的语义特征。然而,高效且精确地提取代码的语义特征已经是一项挑战了,而且不同的编程语言有不同的语法结构和编码特征,提取跨语言代码语义特征,捕获不同编程语言但具有相同功能代码片段的共性就更加困难。现有的方法中,大部分都是以基于自然语言的代码搜索为基础的,它们针对不同编程语言分别训练了编码器,在实际运用的过程中根据开发人员给定的编程语言来切换编码器。然而,这种方法非常复杂,需要训练多个编码器,其扩展性较差。此外,这些方法还没有考虑到不同编程语言之间的语法和结构差异,很难提取到不同编程语言代码片段之间的共性。
7、综上所述,相比于基于自然语言的代码搜索,跨语言代码搜索主要有以下两个挑战:(1)用一个模型提取不同编程语言的代码片段的序列和结构特征是困难的;(2)用一个编码器区分不同语言但是功能相同的代码片段是困难的。
技术实现思路
1、本发明所要解决的技术问题是,针对现有技术不足,提供一种基于对比学习的跨语言代码搜索方法、终端设备及存储介质,提高模型对不同编程语言但是功能相同的代码片段的区分能力。
2、为解决上述技术问题,本发明所采用的技术方案是:一种基于对比学习的跨语言代码搜索方法,包括以下步骤:
3、s1、使用预训练的codebert获取代码的tokens表示,提取代码的序列特征矩阵按行展平,作为代码片段的序列特征其中dtok表示代码片段的序列特征的维度;
4、s2、获取每个代码片段的统一后的ast,统计所有统一后的ast中不同名称的节点的个数,构成节点集合v,并用one-hot向量表示每个ast节点vi∈v,第i个节点在one-hot向量中的第i个位置标记为1,其余位置均为0,ast中节点之间的关联关系用邻接矩阵表示,m表示不同名称的ast节点个数,e中的第i行表示节点vi和其他节点的关系,e中的第i行第j列元素ei,j=1表示节点vi和节点vj之间有关联关系,ei,j=0表示节点vi和节点vj之间没有关联关系;采用图卷积运算提取统一后的ast的特征,则节点i在第l+1层的特征表示为:其中,i为单位矩阵,表示包括节点i本身的所有邻居节点在经过第l-1层图卷积之后的特征,表示矩阵对应的度矩阵,w(l)表示第l层的权重,ni表示节点i的所有邻居节点集合,σ表示非线性变换;将图卷积运算最后一层的特征矩阵按行展平,作为代码片段的结构特征dast为代码片段的结构特征vast的维度;
5、s3、融合代码片段的序列特征vtol和代码片段的结构特征vast,得到完整的代码特征向量vcode;
6、s4、利用所述完整的代码特征向量vcode进行对比学习,使得具有相同类别的代码片段的特征向量的距离更加接近,不同类别的代码片段的特征向量的距离更远,得到跨语言代码搜索模型。
7、本发明使用预训练的codebert和gcn来分别提取不同编程语言的代码片段的序列特征和结构特征,这可以得到更为完整的代码特征。本发明提高了模型对不同编程语言但是功能相同的代码片段的区分能力。
8、步骤s3中,完整的代码特征vcode的表达式为:其中,mlp()表示多层感知机。
9、步骤s4中,对比学习的损失函数l设置为:
10、
11、其中,为锚样本xi的完整的代码特征向量,表示为xi的正样本xj的完整的代码特征向量,即xi和xj的标签相同,表示为xi的负样本xk的代码特征向量,即xi和xk的标签不同,τ代表对比学习的温度系数,sim()表示两个向量的余弦相似度。
12、锚样本为每个样本对的第一个代码片段,所述锚样本对应的第二个代码片段为该锚样本对应的正样本。
13、作为一个发明构思,本发明还提供了一种终端设备,其包括:
14、一个或多个处理器;
15、存储器,其上存储有一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现本发明上述方法的步骤。
16、作为一个发明构思,本发明还提供了一种计算机可读存储介质,其特征在于,其存储有计算机程序,所述计算机程序被处理器执行时实现本发明上述方法的步骤。
17、与现有技术相比,本发明所具有的有益效果为:
18、1.本发明使用预训练的codebert和gcn来分别提取不同编程语言的代码片段的序列特征和结构特征,这可以得到更为完整的代码特征。因此在代码特征提取上优于现有方案。;
19、2.本发明使用对比学习的方法来训练模型,这样模型就能有效区分具有相同功能的不同编程语言的代码片段,从而提升跨语言代码搜索的准确度。
- 还没有人留言评论。精彩留言会获得点赞!