地铁车门机械部件差异工况下的磨损程度预测方法和系统与流程
本发明涉及轨道交通安全,尤其涉及一种地铁车门机械部件差异工况下的磨损程度预测方法和系统。
背景技术:
1、随着轨道交通行业的发展,城市轨道车辆门运行的安全性、可靠性受到广泛重视。目前,企业的主要维修策略仍是“传统的”基于时间的维修(简称tbm),tbm是指完全根据设备/部件使用时间制定的预防性维修,其连续维修间隔一般为固定值。通过该种策略,只需根据设备/部件的运行时间制定维护计划,容易实现。但是,如果在进行预防性维修时设备/部件仍然处于良好的健康状态,则会造成维修资源的不必要浪费;而如果机器的损坏速度比预期的要快,则设备/部件可能在下一次预防性维修执行前就已经发生故障停机。
2、由于监视、存储和数据分析等技术的发展,基于状态的维修(简称cbm)策略已逐渐成为企业优化生产管理的重要手段。cbm是指在设备/部件出现了明显的劣化后实施的维修,而状态的劣化是由被监测的机器状态参数变化反映出来的。cbm策略执行的前提是可靠地预测设备/部件当前时刻的剩余使用寿命,从而为管理者精准地制定生产和维修计划提供有价值的信息。车门系统关键机械磨损部件的磨损程度能够很好的反映其性能和寿命,对其直径进行准确的预测,有利于cbm策略的执行。
3、车门系统关键机械磨损部件的磨损程度预测从方法上可归纳为基于模型的预测方法和基于数据的预测方法两大类。其中基于模型的预测方法又可分为基于解析模型的预测方法和基于物理模型的预测方法。基于模型的预测通常会应用一些经验退化模型或物理分析模型作为系统的退化模型。车门系统中存在多个部件的运动耦合、磨损机理复杂,所以构建物理模型较为困难。基于数据的预测方法又可分为基于传统机器学习的预测方法、基于深度学习的预测方法和基于统计学的预测方法三类,其中主流的是基于机器学习的方法,基于深度学习的方法是一种特殊的机器学习方法,其具有更加优秀和灵活的性能。
4、轨道车辆门系统由于其应用场景的特殊性,其电机输出曲线多变、运行工况复杂、干扰因素众多、特征隐蔽微弱,因此对于车门系统关键机械部件的磨损程度预测研究较少。现在主要的研究集中在故障诊断和亚健康状态诊断,研究的思想是针对监测车门运动的电机输出曲线,个性化的提取相关时域特征,然后使用聚类、分类等机器学习方法,完成对应的预测目标。然而,车门在运行过程中由于部件之间,部件与环境之间的相互作用会导致车门进入到不同的工况当中,不同工况下,车门上采集的数据会有所差别,通常将出现变化的车门工况认作是异常工况,不做调整的认作是正常工况。异常工况的数据量少,如果只使用一种工况下的数据来建立预测模型,会导致其无法对其他工况的数据进行准确地预测。在实际应用中,车门系统关键机械部件很难有运行到寿命中止还没有更换的情况,这意味着建立模型所使用的数据集是一个不完整的数据集,即为右删失数据集。因此实现对差异工况下特别是严重磨损状态的预测是亟需解决的问题。
技术实现思路
1、发明目的:本发明旨在提供一种能够有效反应严重磨损实际情况、提高模型预测准确率的地铁车门机械部件差异工况下的磨损程度预测方法和系统。
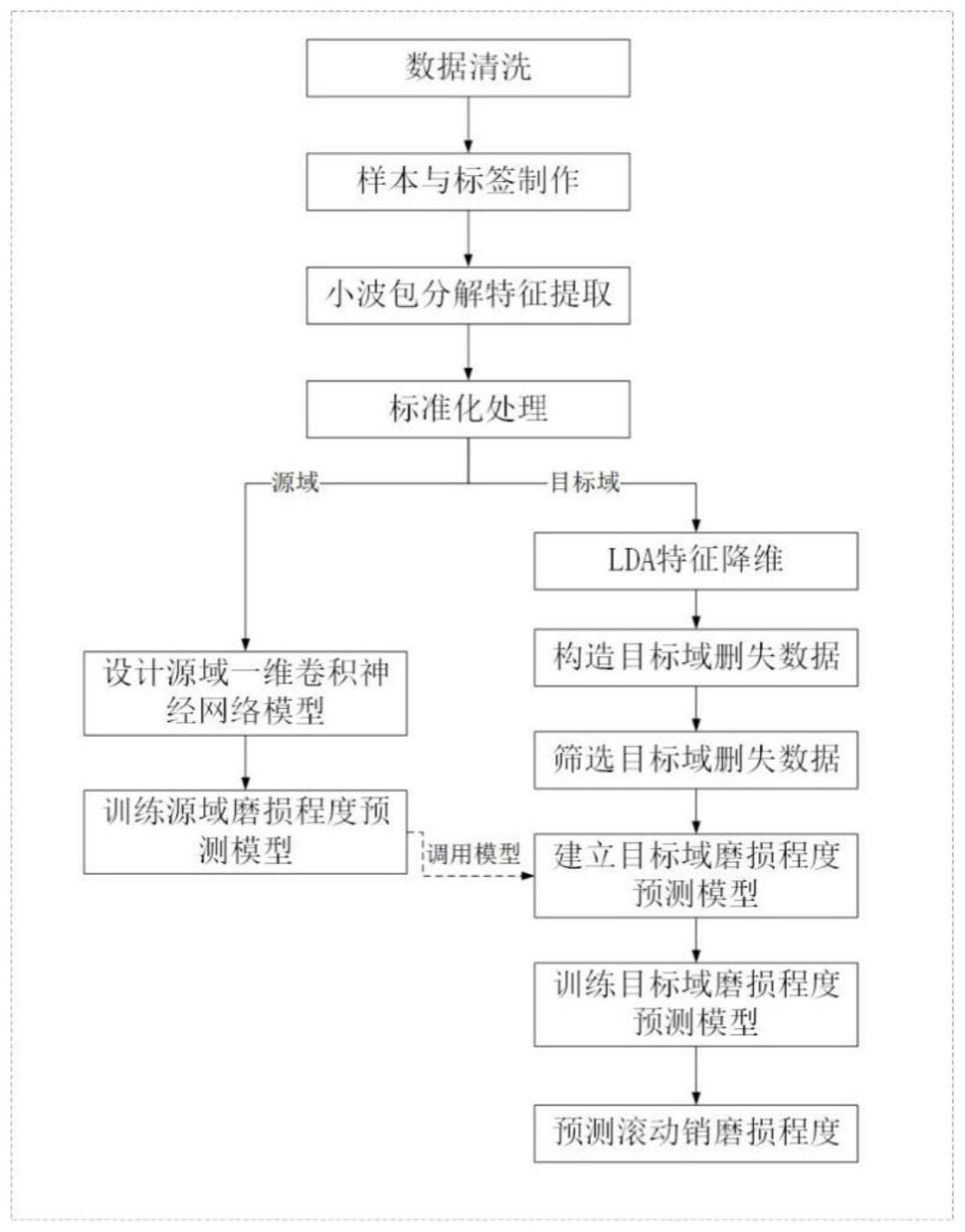
2、技术方案:本发明所述的一种地铁车门机械部件差异工况下的磨损程度预测方法,包括以下步骤:
3、(1)采集不同磨损状态车门机械部件运动数据曲线,并进行预处理;
4、(2)获取不同工况不同机械部件磨损状态下的运动数据构造样本,以磨损状态进行标签标记;
5、(3)特征提取并进行标准化处理;
6、(4)特征降维并进行聚类处理,确定不同标签的特征数据中心点;
7、(5)目标域删失数据的构造和筛选;
8、(6)建立迁移学习预测模型进行机械部件磨损程度预测。
9、优选地,所述步骤(1)中不同磨损状态包括健康、轻度磨损、中度磨损和严重磨损状态。
10、优选地,所述步骤(2)中不同工况包括正常工况和异常工况,正常工况下的样本为源域,异常工况下的样本为目标域,目标域样本数据为右删失数据。
11、优选地,所述步骤(3)中特征提取采用小波包分解方法,将时域数据进行小波包分解,提取分解后子频带信号的能量占比和能量熵特征。
12、优选地,所述步骤(4)中特征降维采用线性判别分析方法。
13、优选地,所述步骤(4)中确定不同标签的特征数据中心点采用基于密度的聚类方法。
14、优选地,所述步骤(5)包括:
15、(5.1)根据已有的目标域不同标签的特征数据中心点,确定右删失特征数据可能存在的中心点,围绕右删失特征数据中心点构造低维的删失数据并映射到高维;
16、(5.2)采用已有的目标域不同标签的特征数据训练线性回归模型对构造的删失数据进行预测,筛选出预测结果与预设值差值不大于阈值的删失数据;
17、(5.3)根据步骤(5.2)所获得数据的中心点,在其周围继续执行步骤(5.1);构造出数据后继续执行步骤(5.2),选出预测结果最接近所需标签的数据,将其加入到目标域特征数据集中。
18、优选地,所述步骤(5.1)包括:
19、首先,根据目标域特征数据集中已有的健康、轻度磨损和中度磨损状态的特征数据的中心点位置及其走向趋势,确定重度磨损状态的特征数据中心点可能存在的区域;
20、其次,定义从轻度磨损到中度磨损状态的特征数据之间的特征距离为r’,则重度磨损状态的特征数据可能存在的中心点位于以下区域:以轻度磨损状态的特征数据中心点为圆心,以r’和2r’为半径的扇环区域,以及以中度磨损状态的特征数据中心点为圆心,以2r’为半径的扇形区域;
21、最后,在上述步骤确定的重度磨损状态下的特征数据中心点可能存在的区域中均匀选取若干个点,分别以这些点为圆心,以已有的健康、轻度磨损和中度磨损状态的特征数据的平均半径r为半径,构造低维的删失数据并映射到高维。
22、优选地,所述步骤(6)中建立迁移学习预测模型包括建立源域模型和目标域模型,所述源域模型为卷积神经网络模型,目标域模型与源域模型相同,在训练时冻结目标域模型卷积层和池化层的参数,不进行参数更新。
23、优选地,所述步骤(6)中机械部件磨损程度预测包括:将源域特征数据集中的特征与标签输入源域模型当中,对源域模型结构参数进行训练;调用已经训练好的源域模型,并冻结全部卷积层和池化层的参数,形成目标域模型;将目标域特征集划分为训练集和测试集,然后将目标域特征集中的训练集输入到目标域模型中对全连接层参数进行二次训练;最后将目标域特征集中的测试集输入到训练好的目标域模型中,得到预测结果。
24、本发明所述的一种地铁车门机械部件差异工况下的磨损程度预测系统,包括:
25、样本与标签制作模块,用于利用预处理后的不同工况不同机械部件在不同磨损状态下的运动数据构造样本,并以磨损状态进行标签标记;
26、特征处理模块,用于将样本数据进行特征提取,构成源域特征数据集和目标域特征数据集;将目标域特征数据进行降维并确定不同标签的特征数据中心点和半径;
27、删失数据构造筛选模块,用于根据已有的目标域不同标签的特征数据中心点和半径,构造删失数据并通过线性回归模型进行筛选;
28、建模预测模块,用于建立迁移学习预测模型进行机械部件磨损程度预测。
29、有益效果:与现有技术相比,本发明具有如下显著优点:1、针对监测数据多为右删失数据的问题,采用线性判别分析降维的方法,基于右删失数据在低维度构造删失数据并通过线性回归模型进行筛选;该删失特征数据构造方法更具有导向性与目标性,通过降维后的特征数据根据标签磨损程度的二维空间位置推算严重磨损位置,能够初步约束构造数据中心的区域并通过数据聚集半径约束数据聚集范围,使得构造的删失数据能够有效反应严重磨损数据实际情况,为后续模型的建立提供有效的数据源进行训练,进而提高模型预测准确率,解决了数据缺失带来的模型训练的困难问题;2、针对门状态不同对机械部件磨损程度预测存在影响,且异常工况数据量较少的问题,采用迁移学习的方法,将数据完整的正常工况数据做为源域,数据缺失的异常工况数据做为目标域进行模型训练,使用目标域数据对源域模型进行调整,该方法能够针对不同的工况训练出对应的模型。
- 还没有人留言评论。精彩留言会获得点赞!