一种提取文本中关键信息的方法、装置及电子设备与流程
本技术涉及语言处理,尤其涉及一种提取文本中关键信息的方法、装置及电子设备。
背景技术:
1、所谓“数据质量决定了数据挖掘的上限,而算法仅仅是逼近这个上限”。在与自然语言处理相关的深度学习任务中,例如文本生成、机器翻译等,为提升任务完成度,提升处理对象:提升数据的质量是一项重要的课题。例如在涉及对象类词、特性词、或表示词等数据元对标方面的文本处理过程中,数据质量对于文本处理效果同样存在重要的影响。此处文本处理中的数据元对标具体是指针对待对标数据元与数据库中的数据元进行一种相似度的计算,从数据库中召回相似度最高的数据元作为待对标数据元所对标的数据元。可见,数据元对标这类任务的本质为文本匹配。而是否能高质量地完成文本处理以及数据元对标的重点在于,是否能够高质量地完成文本向量表示。即文本以向量表示的效果越好,其最终的处理效果也就越好。
2、然而,在文本向量化过程中,首先需要处理的是字段原始注释,这些原始注释是为了读者便于理解而对字段设置的说明和解释。尽管字段的原始注释有助于文本匹配;但是,因原始注释是为了方便读者理解而人为添加的注解,所以其中往往包括带有修辞手法、类比等的冗余信息。当文本以及文本中各字段的原始注释一并进入语言处理模型接受处理时,往往带来大量的噪声,致使语言处理模型输出结果的准确度难以提升。
3、为此,现有技术中设置语言处理模型,使之可以在原始文本中识别出重要片段并提取以降低噪声。然后,再对这些文本片段及其原始注释进行处理以完成对标。但,通过上述方式并不能每次都将重要片段识别出,并提取。也即大量冗余信息仍然导致语言处理模型处理过程中所面临的大的噪声压力,这导致语言处理模型的结果不可控:难以准确、高精度的在原始文本中识别出重要片段,进而导致得到的关键信息准确度低。
技术实现思路
1、本技术提供了一种提取文本中关键信息的方法、装置及电子设备,用以提升在文本中提取所得的关键信息的准确度。
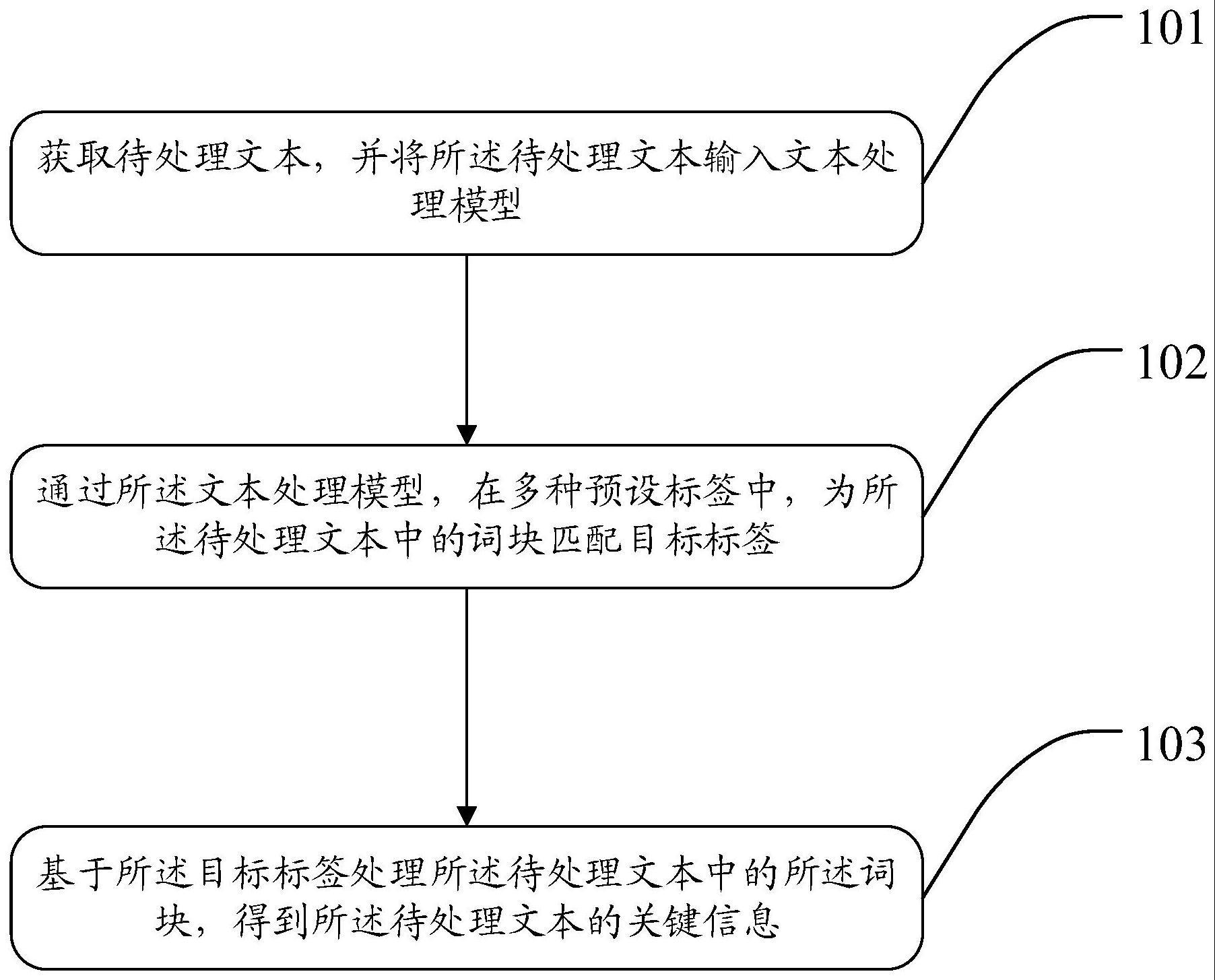
2、第一方面,本技术实施例提供一种提取文本中关键信息的方法,包括:
3、获取待处理文本,并将所述待处理文本输入文本处理模型;
4、通过所述文本处理模型,在多种预设标签中,为所述待处理文本中的词块匹配目标标签;其中,所述目标标签指示所述词块所对应的待执行编辑动作;
5、基于所述目标标签处理所述待处理文本中的所述词块,得到所述待处理文本的关键信息。
6、一种可能的实施方式,所述预设标签的种类包括删除、保留、替换和添加;其中,所述替换包括待替换对象,所述添加包括待添加对象。
7、一种可能的实施方式,所述通过所述文本处理模型,在多种预设标签中,为所述待处理文本中的词块匹配目标标签,包括:
8、将所述待处理文本划分为词块,并为所述词块添加位置标记;其中,所述位置标记指示所述词块与所述待处理文本中其它词块之间的相对位置关系;
9、基于所述词块和所述词块的位置标记,对所述词块进行自注意力编码计算,得到对应于所述词块的词块矩阵;其中,所述词块矩阵中行向量的数量与所述自注意力编码计算中隐藏层的数量相等;
10、基于所述词块矩阵,在所述预设标签中为所述词块匹配所述目标标签。
11、一种可能的实施方式,所述基于所述词块和所述词块的位置标记,对所述词块进行自注意力编码计算,得到对应于所述词块的词块矩阵,包括:
12、在所述文本处理模型中的隐藏层中对所述词块进行自注意力编码计算,分别在每一所述隐藏层得到对应于所述词块的子矩阵;
13、将每一所述词块的子矩阵输入所述文本处理模型中的卷积神经网络,得到对应于每一所述词块的词块矩阵。
14、一种可能的实施方式,所述将所述待处理文本输入文本处理模型之前,还包括:
15、利用待训练文本处理模型,划分获取到的训练文本,得到训练词块;其中,所述训练文本包括预设词块与标准标签之间的对应关系,所述标准标签指示所述词块所对应的待执行编辑动作;
16、为所述训练词块添加位置标记,并在所述预设标签中为所述训练文本中的所述训练词块匹配训练标签;
17、基于所述训练词块与所述预设词块之间的第一误差,及所述训练标签与所述标准标签之间的第二误差,调整所述待训练文本处理模型中的参数,直到所述待训练文本模型输出的所述训练词块的准确率大于第一设定阈值,且所述训练标签的准确率大于第二设定阈值,得到文本处理模型。
18、一种可能的实施方式,所述在预设标签中为所述训练文本中训练词块匹配训练标签,包括:
19、对所述训练词块进行自注意力编码计算,在每一所述隐藏层分别得到对应于所述训练词块的子矩阵;
20、提取对应于同一所述训练词块的子矩阵中的特征信息并融合,得到对应于每一所述训练词块的特征矩阵;
21、基于所述特征矩阵,在所述预设标签中为所述训练词块匹配所述训练标签。
22、第二方面,本技术实施例提供一种提取文本中关键信息的装置,包括:
23、输入单元,用于获取待处理文本,并将所述待处理文本属于文本处理模型;
24、匹配单元,用于通过所述文本处理模型,在多种预设标签中,为所述待处理文本中的词块匹配目标标签;其中,所述目标标签指示所述词块所对应的待执行编辑动作;
25、信息单元,用于基于所述目标标签处理所述待处理文本中的所述词块,得到所述待处理文本的关键信息。
26、一种可能的实施方式,所述预设标签的种类包括删除、保留、替换和添加;其中,所述替换包括待替换对象,所述添加包括待添加对象。
27、一种可能的实施方式,所述匹配单元具体用于将所述待处理文本划分为词块,并为所述词块添加位置标记;其中,所述位置标记指示所述词块与所述待处理文本中其它词块之间的相对位置关系;基于所述词块和所述词块的位置标记,对所述词块进行自注意力编码计算,得到对应于所述词块的词块矩阵;基于所述词块矩阵,在所述预设标签中为所述词块匹配所述目标标签。
28、一种可能的实施方式,所述匹配单元具体用于在所述文本处理模型中的隐藏层中对所述词块进行自注意力编码计算,分别在每一所述隐藏层得到对应于所述词块的子矩阵;将每一所述词块的子矩阵属于所述文本处理模型中的卷积神经网络矩阵,得到对应于每一所述词块的词块矩阵。
29、一种可能的实施方式,所述装置还包括训练单元,所述训练单元具体用于利用待训练文本处理模型,划分获取到的训练文本,得到训练词块;其中,所述训练文本包括预设词块与标准标签之间的对应关系,所述标准标签指示所述词块所对应的待执行编辑动作;为所述训练词块添加位置标记,并在所述预设标签中为所述训练文本中的所述训练词块匹配训练标签;基于所述训练词块与所述预设词块之间的第一误差,及所述训练标签与所述标准标签之间的第二误差,调整所述待训练文本处理模型中的参数,直到所述待训练文本模型输出的所述训练词块的准确率大于第一设定阈值,且所述训练标签的准确率大于第二设定阈值,得到文本处理模型。
30、一种可能的实施方式,所述训练单元具体用于对所述训练词块进行自注意力编码计算,在每一所述隐藏层中分别得到对应于所述训练词块的子矩阵;提取对应于同一所述训练词块的特征矩阵;基于所述特征矩阵,在所述预设标签中为所述训练词块匹配所述训练标签。
31、第三方面,本技术实施例提供一种可读存储介质,包括,
32、存储器,
33、所述存储器用于存储计算机程序,当所述计算机程序被处理器执行时,使得包括所述可读存储介质的装置完成如第一方面及任一种可能的实施方式所述的方法。
34、第四方面,本技术实施例还提供一种电子设备,包括:
35、存储器,用于存放计算机程序;
36、处理器,用于执行所述存储器上所存放的计算机程序时,以实现如第一方面及任一种可能的实施方式所述的方法。
37、本发明实施例中所提供的一个或多个技术方案,至少具有以下技术效果:
38、通过为文本中token(即上述词块)添加指示编辑动作的目标标签,及时将文本中口语化表达、错误编辑或遗漏的表示改写,使文本处理模型在处理待处理文本时的噪音得以有效减少,且待处理文本中的错误信息也通过匹配到的目标标签能够得到纠正,从而提升最终得到的关键信息的准确度。同时,将关键信息的提取转化为token的分类的文本改写式任务,有效减少了文本处理模型在接收到待处理文本后所处理的数据量,避免了将词块与词典中所有字、词逐一配对,确定是否匹配导致的模型收敛速度慢的问题,使得本技术实施例所提供的文本处理模型能够更为高效的确定对应于待处理文本的关键信息。基于此,本技术实施例所提供的文本处理模型的训练效率也得以有效提升,使得文本处理模型的训练及使用压力得以有效缓解。
- 还没有人留言评论。精彩留言会获得点赞!