一种基于斯塔克伯格博弈的设备调度方法
本发明涉及bs和移动设备的联邦学习,特别是一种基于斯塔克伯格博弈的设备调度方法。
背景技术:
1、得益于智能(internet of things,物联网)设备数量的爆炸性增长以及移动设备计算能力的快速发展,机器学习在大量研究领域取得显著的成功,随着越来越多的移动设备接入互联网,无线网络中的训练数据可能会被各种设备收集。传统的机器学习方法将所有客户端产生的数据集中传输到一个计算中心进行模型训练,这个过程可能导致客户端隐私数据的泄露,并造成数据滥用的恶劣效果。因此,为了满足隐私保护的需求,充分利用有限的通信资源,安全高效的提高联合建模性能,一种特殊形式的分布式机器学习方法被提出,即联邦学习,其允许移动设备利用私有数据训练本地模型后,将更新后的模型上传到基站(base station,bs)进行全局聚合,并将产生的全局模型下发给移动设备用于下一阶段的本地更新,从而实现移动设备在不暴露其原始数据的情况下协同训练机器学习模型。
2、联邦学习是一项极富前景的机器学习方法,但是移动设备参与到联邦学习的过程中将会消耗大量的私有资源,比如计算能力、带宽和珍贵数据等等,考虑到移动设备的自私性,在没有奖励的情况下不愿无偿牺牲自己的资源来协助联邦学习,这些约束使得联邦学习在移动网络和边缘计算(mobile edge computing,mec)等场景中受到限制。在基于多个bs和多个移动设备的多对多联邦学习架构中,需要通过优化两者之间的关联关系最大化系统总效益,其中bs的效益函数定义为全局模型带来的收益和给予移动设备总奖励的加权和,移动设备的效益函数定义为bs给予的奖励和自身参与联邦学习的总能耗的加权和。因此,一个高效合理的激励机制是十分必要的。
技术实现思路
1、本发明所要解决的技术问题是首先提出了一个bs和移动设备之间的联邦学习框架,通过基于斯塔克伯格博弈的多对多联邦学习激励机制来进行bs和移动设备间的选择调度,旨在通过求得博弈双方的均衡解来达到理想的使得特定移动设备集合服务特定bs的分簇效果,即确定bs和设备集合之间的关联情况,从而达到最大化双方效益的效果。
2、为达到上述目的,本发明采用的技术方案是:
3、一种基于斯塔克伯格博弈的设备调度方法,由m个任务发布者bs,集合为和n个移动设备,集合为组成,具体步骤如下:
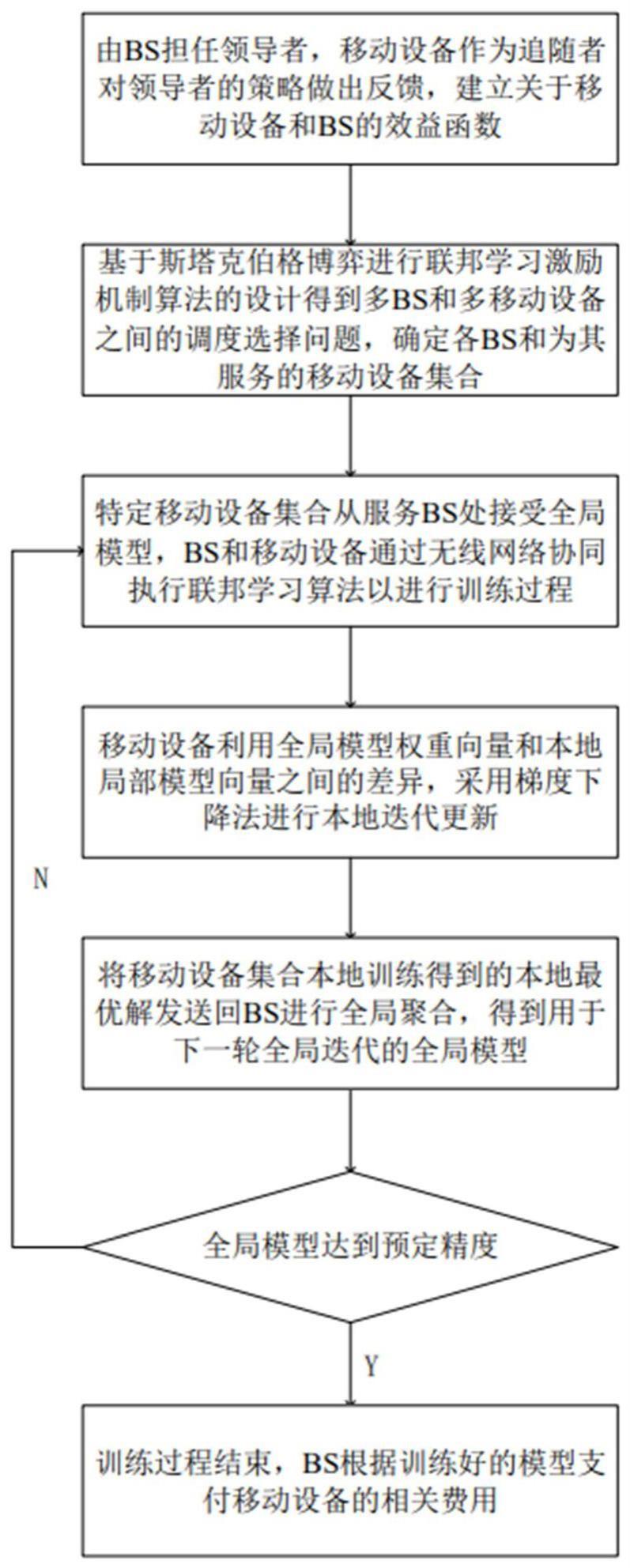
4、步骤一、由bs担任领导者,移动设备作为追随者对领导者的策略做出反馈,建立关于移动设备和的设备选择效益函数;
5、步骤二、移动设备集合选择从处接受全局模型wt,bsm的全局迭代轮数其中为bsm全局迭代总轮数,bs和移动设备通过无线网络协同执行联邦学习算法,找到满足bs集合的最小化全局损失函数的全局模型权重向量;
6、步骤三、进行bs和移动设备之间的交互,利用来自bsm的全局模型权重向量和移动设备n的本地模型权重向量之间的差异φnm,采用梯度下降法进行本地迭代更新,直到达到本地精度阈值为止;
7、步骤四、将每个移动设备经过本地迭代更新后得到的本地权重差异最优解上传到bsm进行全局聚合完成后,向参与t+1轮全局迭代的移动设备集合广播全局模型wt+1,用于下一轮联邦学习训练,直到全局模型达到预定精度为止,bs根据训练好的模型给予移动设备集合相关奖励。
8、进一步的,步骤一中,建立移动设备和bs的关于设备选择的效益函数,通过以下步骤实现:
9、步骤1-1):在斯塔克伯格博弈的第一阶段,移动设备n根据bs给出的全局迭代次数iglobal和奖励q确定自己的策略εn,最大化自身效益un,即
10、
11、
12、其中表示移动设备n服务于bsm的所得效益,εn表示移动设备n关于bs集合的本地精度集合,xnm表示移动设备n为bsm提供联邦学习服务的概率,qnm表示移动设备n为bsm提供联邦学习服务得到的报酬,εnm表示移动设备n为bsm提供联邦学习服务的本地精度,β是单位能量的成本,表示bsm全局迭代次数,表示移动设备n在与bsm的单次全局迭代中的通信能耗,是正数,为移动设备n的本地训练能耗;
13、步骤1-2):在第二阶段,根据第一阶段的均衡解来确定bsm的策略,最大化自身效益um,即
14、
15、s.t.q>0.
16、其中表示bsm被移动设备n服务所得效益,γ表示bsm的收益,y(dn,θn)表示移动设备n为bsm提供联邦学习服务时模型的预期精度,是与移动设备n数据集的总体大小dn和平均emdθn有关的拟合函数,即
17、
18、其中a(θn)、b和c为该拟合函数的拟合系数。
19、进一步的,bs和移动设备之间的斯塔克伯格博弈过程通过以下步骤实现:
20、步骤2-1):解决第一阶段的子博弈中移动设备最优解分析,找到移动设备n对bsm的最佳策略,对移动设备n关于bsm的效益函数中的εnm取偏分,即
21、
22、在εnm∈(0,1]间存在唯一解,在处存在最大值;任何移动设备n在给定bsm所给奖励qnm的情况下,确定自己对bsm唯一的策略下层存在唯一均衡解,解得
23、
24、步骤2-2):将移动设备n的均衡解代入即将最优解代入移动设备n和bsm之间的上层子博弈进行bs最优解分析,则有
25、
26、在不损失函数关系准确性的情况下,对上述公式进行简单化处理,即
27、
28、解决上层子博弈的最佳策略,对上式中的qnm取偏分,即
29、
30、在qnm∈(0,+∞)之间存在唯一解,在处存在最大值;给定移动设备n对bsm唯一的策略的条件下,bsm对移动设备n达到其唯一的均衡解令有
31、
32、最终得到移动设备n和bsm之间子博弈的唯一均衡解
33、步骤2-3):移动设备n和bsm之间子博弈的唯一均衡解代入优化公式p1、p2,简化为
34、
35、其中以及
36、
37、其中
38、进一步的,步骤二中,最小化bsm的全局损失函数fm(w)定义如下
39、
40、其中本地损失函数定义损失函数f(w,xnl,ynl)来描述模型w在输入矢量xnl和输出标签ynl上的性能,是移动设备n的第l个输入向量,ynl是对应的标签。
41、进一步的,步骤三中,给定bs m的全局损失函数梯度其中表示移动设备n从bsm处接受全局模型wt进行本地更新的损失函数梯度,移动设备n使用本地数据集进行本地训练的目标函数为
42、
43、其中wt+φnm为移动设备n的本地模型向量参数,ln(wt+φnm)表示目标函数,fn(wt+φnm)为移动设备n基于本地模型向量参数更新的本地损失函数,φnm表示bsm的全局模型权重向量和移动设备n的本地模型权重向量之间的差异,ζ为常数;
44、使用梯度下降法求解本地更新优化目标
45、
46、其中λ是给定的步长,是移动设备n在第t次全局迭代中第i次本地迭代中φnm的值;
47、给定本地优化目标的最优解重复本地迭代更新过程,直到满足以下条件
48、
49、其中分别是移动设备n在第t次全局迭代中第i次本地迭代、达到最优解情况下的、以及初始情况下的公式化后的本地训练目标函数,参数εnm是移动设备n的本地精度。
50、进一步的,步骤四中,bsm全局聚合定义如下
51、
52、其中表示移动设备n的本地最优解;训练停止的条件满足下式
53、fm(wt)-fm(w*)≤η(fm(w0)-fm(w*))
54、其中fm(wt)、fm(w*)、fm(w0)分别是bsm在第t次全局迭代时、达到最优解情况下的、以及初始情况下的全局损失函数,w*表示最小化全局损失函数的最优解,η为全局精度。
55、进一步的,步骤四中,bsm的全局迭代次数的下限为:
56、
57、其中是常数,εm是移动设备的本地精度集合,η是全局精度;实现关于移动设备n的本地精度εnm所需的本地迭代次数的下限为
58、
59、其中是正数,根据移动设备之间的不同εnm值,全局迭代次数重写为
60、
61、本发明所达到的有益效果:
62、本发明方法与之前大部分研究中考虑到的单bs多移动设备的联邦学习框架不同,考虑到无线网络和传输的复杂性,重点考虑了多bs和多移动设备的学习架构。
63、本发明方法考虑到设备的自私性,通过考虑激励机制评估每个移动设备的贡献,并根据贡献获得奖励,获得更多的、分配更合理的移动设备的接入,减少资源消耗,同时可避免恶意移动设备传播低质量的本地模型,更具有公平性。
64、本发明方法通过充分考虑全局迭代次数和全局、本地训练精度之间的训练作用效果,在每次全局迭代中,移动设备和bs之间都有交互,为效益函数的建立和激励关联调度作理论铺垫。
- 还没有人留言评论。精彩留言会获得点赞!