本发明涉及自主无人系统领域,具体涉及一种针对对抗场景下不确定性辅助任务的分层强化学习方法。
背景技术:
1、近年来,不同种类的自主无人系统,譬如无人机、无人车、仿生机器人等,被逐步应用到了军事、反恐、商业、救灾等各种复杂不确定环境中去执行任务,在这些任务中,除了与优化目标直接相关的“主要任务”,还存在着与优化目标有间接影响关系的“辅助任务”。其中,辅助任务的执行可以在一定程度内提升其影响范围内其它任务的执行效率(譬如,在电子对抗场景中,攻击敌方舰船是主要任务,屏蔽敌方电磁干扰是辅助任务)。因此,需要根据主要任务以及辅助任务的关联关系,为多智能体系统中的每个智能体分配对应的任务,并为其设计相应的任务执行策略,来提升任务执行的效用。
2、在实际对抗场景中,辅助任务的辅助能力是不确定的,主要体现在对其影响范围内其它任务执行效率的增益是不确定的。在这种情况下,由于以往算法缺乏对这种不确定性辅助任务的建模,会导致系统陷入局部最优解。在设计针对性算法时,存在两个挑战:首先,在为多智能体系统设计任务分配策略时,需要考虑不确定性辅助任务及其对主要任务的影响,增加了问题解的维度;其次,在考虑任务执行策略时,需要根据辅助任务的不确定性,自适应地调整智能体的任务执行顺序,使得问题的解空间变得复杂。
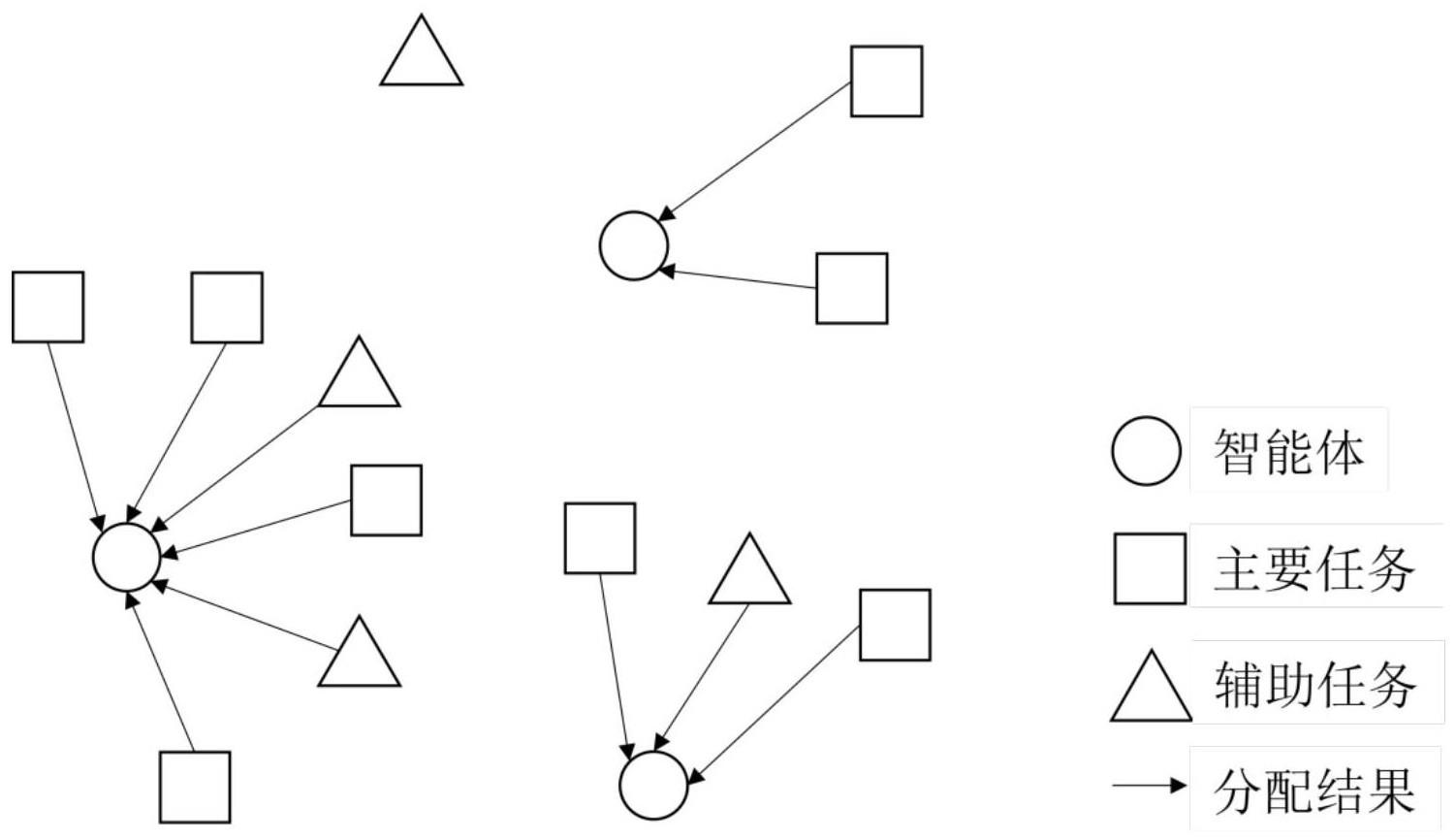
3、为了解决这个问题,本专利提出了一种分层多智能体强化学习方法,来分别解决不确定辅助任务对群体和个体的影响带来的任务分配和任务执行问题,以此降低问题的复杂度和解空间的规模。首先上层强化学习用于解决当辅助任务存在不确定性时对整个多智能体系统的影响带来的任务分配问题,如图1所示,每个智能体都会被分配到一部分任务,有的辅助任务因为辅助能力较弱而被舍弃了,该层强化学习的网络结构如图2所示,首先各智能体将环境信息嵌入到自身和任务信息中,接着从所有辅助任务中提取出对自身重要的信息,并基于此从所有主要任务中提取出重要的信息,在考虑别的智能体的信息后,智能体就会决策将哪些任务分配给自己,在采样出收益最高的分配方法后,反向传播来更新网络参数,不断迭代来最大化收益。在每个智能体得到其被分配的任务之后,它们需要根据这些任务构建出专属子环境,之后智能体都只能在其专属子环境内观测和行动,这样可以降低下层强化学习的观测空间。下层强化学习用于解决当辅助任务存在不确定性时对单个智能体的影响带来的任务执行问题,如图3所示,智能体在其子环境内自主决策出任务的执行顺序;如图4所示,智能体需要观测其周围环境的风险级别,尽量选择移动至低风险区域。
4、对抗性场景下多智能体系统的任务分配和任务执行算法是为了使系统拥有较小的智能体损失率和较低的任务完成时间,当环境中存在不确定的辅助任务时,问题会变得复杂许多。对整个多智能体系统而言,需要将辅助能力较强的辅助任务分配给合适的智能体;对于每一个智能体而言,需要先执行辅助能力较强的辅助任务,再去执行其影响范围内的其它任务。因此,我们希望通过分层强化学习的方式,将上述复杂问题分解成任务分配和任务执行两个子问题,来更好地处理辅助任务的不确定性,以此降低问题的复杂度和解空间的规模。
技术实现思路
1、技术问题:本发明的目的是提出一种针对对抗场景下不确定性辅助任务的分层强化学习方法,该方法分为两层,上层强化学习用于解决不确定辅助任务带来的任务分配问题,在该层中,系统可能会舍弃部分辅助任务,将剩下的任务分配给各个智能体;下层强化学习用于解决不确定辅助任务带来的任务执行问题,在该层中,系统会决策出执行任务的具体顺序。该方法解决了在对抗性环境下,当存在不确定的辅助任务时,直接进行任务执行会造成解空间过于复杂的问题。
2、技术方案:在对抗性环境下,多智能体系统需要执行一些任务,这其中有着辅助能力不确定的辅助任务,即辅助任务对其影响范围内其它任务执行效率的增益是不确定的。为了适应这种不确定性并最大化辅助任务的效用,智能体需要先决策出将哪些辅助任务分配给哪些智能体,再决策出执行这些任务的顺序。同时,为了降低问题的复杂性和解空间的规模,我们采用分层强化学习来将问题分解成任务分配和任务执行两个子问题,该分层强化学习方法的主要技术方案如下:
3、首先是上层强化学习,这一层是用于解决当辅助任务存在不确定性时对整个多智能体系统的影响带来的任务分配问题。对每一个智能体来说,该层的输入是自身的全部信息、所有任务的全部信息、全局环境信息,以及其它智能体的信息,输出是每一个智能体各自被分配的任务,每一个智能体都会被分配到所有任务的一部分。多智能体系统中每一个智能体先将环境信息嵌入到自身和任务信息中,再从所有辅助任务中提取出对自身重要的辅助任务信息,其中距离自身较近的辅助任务可能是重要的,然后基于此提取出重要的主要任务信息,其中距离自身和重要辅助任务较近的主要任务可能是重要的,所处位置风险较高的任务可能是不重要的,接着将其它智能体的信息融合进来,这样就能将自身和对自身重要的任务信息以及其它智能体的信息表示成一个高维向量,然后各智能体从这个高维向量中决策出要执行哪些任务。每个智能体都有一个q函数,所有智能体的q函数单调加权相加构成了整个智能体集群的q函数,也就是说,每个智能体的q函数增加时,整体q函数也会增加,当每个智能体的q函数都最优时,整个智能体集群的q函数也是最优的。每一个智能体的奖励函数与任务完成时间和智能体存活率有关,具体来说,当每个智能体完成被分配到的任务的期望时间越短,智能体的期望存活率越高,其奖励就越大。
4、然后是下层强化学习,这一层是用于解决当辅助任务存在不确定性时对单个智能体的影响带来的任务执行问题。这一层先进行子环境构建,上一层强化学习输出了每个智能体被分配到的任务集合,智能体根据这个集合构建出自己专属的子环境,在这个子环境里只包括自己和被分配到的任务,不包括别的智能体和未被分配到的任务,不同智能体的子环境会有重叠的部分,这是因为环境中可能有高风险区域,智能体可能需要绕路来走安全区域去执行任务,因此,子环境构建需要在满足不包括其它实体的条件下尽可能大,以给可能的绕路提供空间,其中智能体和任务统称为实体。通过子环境构建,可以大幅缩短下层强化学习的观测空间,提高学习效率。对每一个智能体来说,该层的输入是自身的全部信息、被分配到的任务的全部信息以及子环境内每个位置的风险指数。输出是每一个智能体的速度矢量va。该层强化学习用于让每个智能体自主决策出具体的任务执行路径。由于经过了上一步的子环境构建,现在每一个智能体在各自的子环境内互不影响,各个子环境也没有交叉的实体,因此,这一层的强化学习就转变为了单智能体强化学习问题,问题难度大幅减小。这一层的奖励函数设计和上层强化学习的类似,区别在于,上层强化学习网络每nt步更新一次,这一层1步更新一次。
5、有益效果:
6、(1)提升多智能体系统对辅助任务不确定性的适应程度:在上层强化学习中,各智能体首先提取出对自身重要的辅助任务信息,并基于此提取出重要的主要任务信息,这样能在分配阶段舍弃成本大于效用的辅助任务,还能将辅助任务和其辅助范围内的其它任务表示在一起。在下层强化学习中,智能体在执行任务的过程中会实时观测不确定的辅助任务,尽量选择在其辅助能力大的时候再去执行,这样能在执行阶段最大化辅助任务的效用。
7、(2)减少多智能体系统完成任务的总时间:首先上层强化学习会为每一个智能体分配相应的任务,在分配的过程中会考虑到每一个智能体完成任务的期望时间,保证它们的期望任务完成时间接近,这样就对多智能体系统的任务完成时间做出第一重优化。在下层强化学习中,智能体会通过不断地训练掌握其在子环境中完成任务的最优路线,以尽量缩短完成任务的具体时间,这是第二重优化。通过这两重优化,便能有效地减少多智能体系统完成任务的总时间。
8、(3)降低多智能体系统损失率:首先上层强化学习会为每一个智能体分配一个任务集合,在分配的过程中会考虑到每个智能体在之后执行任务时可能遇到的风险,即保证它们在执行任务时所遭遇的期望风险接近,这样就能对多智能体系统损失率做出第一重优化。在下层强化学习中,智能体会通过不断地训练掌握其在子环境中完成任务的最优路线,尽量避开高风险区域来降低其损失率,这是第二重优化。通过这两重优化,便能有效地降低多智能体系统损失率。