基于深度学习构建肾透明细胞癌分级模型的方法
本发明属于图像处理,具体涉及基于深度学习构建肾透明细胞癌分级模型的方法。
背景技术:
1、肾细胞癌(renalcellcarcinoma,rcc)是泌尿系统中恶性度较高的肿瘤,也是最常见的肿瘤之一,占肾恶性肿瘤的80%~90%。rcc发病机制主要是由肾脏的上皮系统引起的,在我国的肿瘤类型中,它的发病率排名第二,占成人恶性肿瘤的比例为2%~3%且随社会经济发展在全球发病率逐年上升。肾透明细胞癌(clearcellrenalcellcarcinoma,ccrcc)是最常见的rcc亚型,占肾恶性肿瘤的10%~15%。在进行肾部分切除术之前,必须对肾部恶性肿瘤进行全面的评估和分析。fuhrman分级被广泛认可,它不仅可以作为肾癌的诊断依据,而且还可以作为评估肾癌患者预后的重要参考,其根据癌细胞的大小,形状和核仁分为四个等级(i,ii,iii,iv),其中包括分化良好,中分化和低分化(未分化)的分类标准,病理等级越高,病情越严重,复发风险越高。
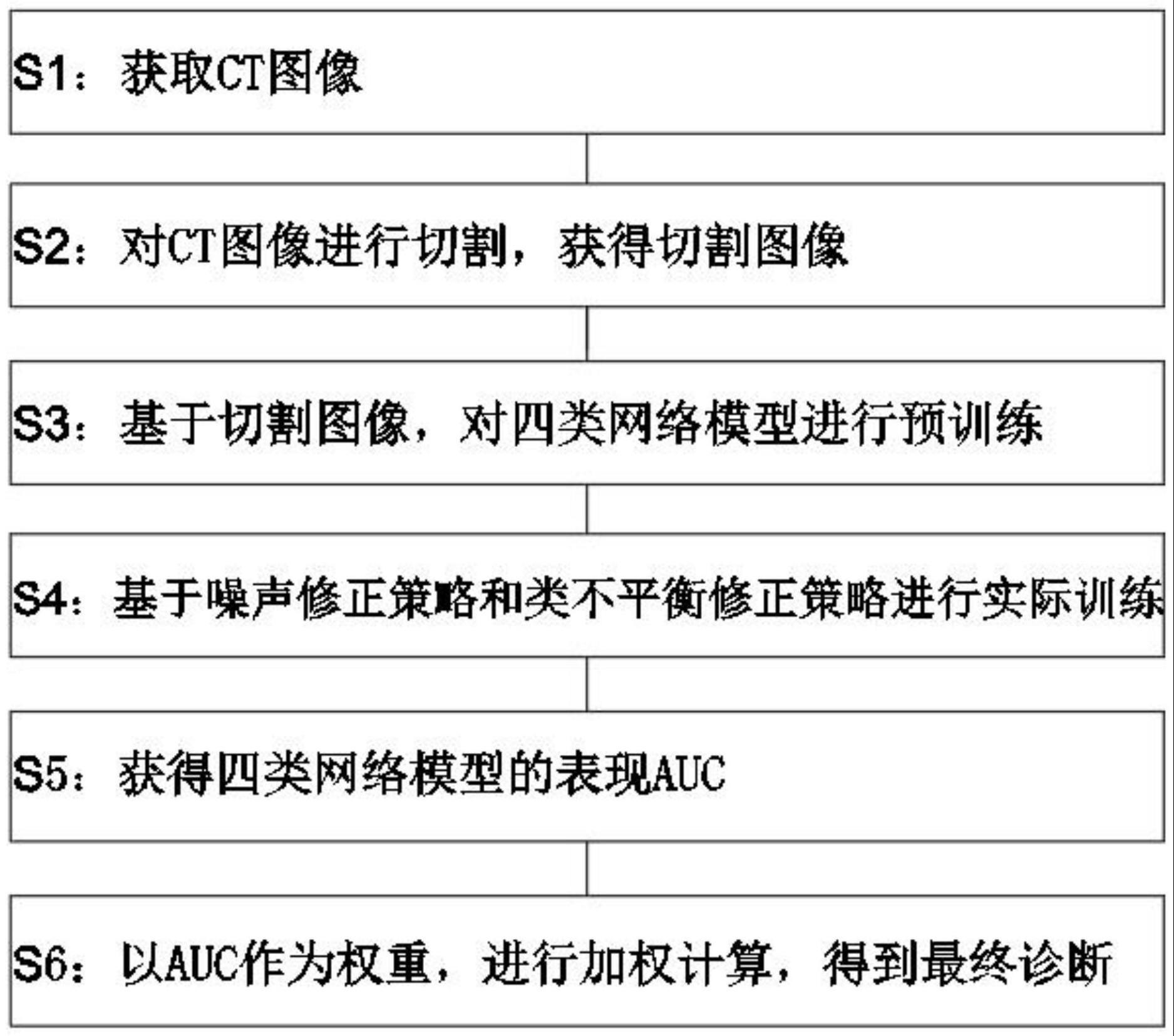
2、活体组织检查(活检)是指根据诊断和治疗需要,通过切取、钳取或穿刺等操作,从患者体内取出病变组织,从而进行病理学检查的技术。活检是检测肿瘤患者病理状态最常见方法,但是活检存在如出血、感染,肿瘤破裂等风险。相对于活检,肾脏ct是一种常规的临床无创检查,常用于肾脏占位的检测、定位、形态学表征、肾血供及肿瘤分期。从患者的ct图像中挖掘相关的组织病理学信息已成为医学图像数据挖掘和分析中的一个有价值的问题。
3、近年来,深度学习模型在多个计算机视觉领域表现优异,它能够很好地捕捉图像中的纹理信息,并加以综合分析,作为识别图像特征的关键。如果投入足够多的高质量数据,深度学习模型的性能将是令人满意的,而医学图像刚好具有海量、多模态的特点,因此越来越多的研究集中在利用深度学习处理医学图像上。
4、数据依赖是深度学习中常见的问题之一。相对于传统的机器学习方法,深度学习对于数据集的数量有着较高的要求,因为它需要通过大量的数据训练来建模数据潜在的结构。通常而言,模型的规模几乎与所需的数据量成线性关系,这是因为在特定问题之下,模型必须要由足够大的表达空间,才能够建模数据的模式。网络模型的前序层通常用于识别训练数据集的高级特征,后续层则是对高级特征进行分析,从而为决策信息提供相应的帮助。在特定的问题中,训练数据不够充足往往是无法避免的问题。在构建数据集的过程中,数据的收集既复杂又昂贵,故构建一个多数量的、高质量的带标签的数据集是充满难度的,比如,医学数据集中的每个样本的背后往往代表着一次临床试验或一个被病痛折磨的患者。此外,即使研究者付出了大量的人力物力财力获得了所需要的数据集,也很容易因为过时而变得不具有代表性,从而使得其无法应用于新的任务。
5、迁移学习使得训练数据与测试数据可以不用严格遵守独立同分布假设,从而吸引了大量的研究者用其来解决训练数据集不足的问题。在迁移学习中,不用对训练数据进行额外的处理,也不需要针对特定任务重新训练网络模型,能够明显降低对于特定任务的训练时间。特别地,医学图像的确具有数据量大,模式多样的特点,但对于分类任务而言,图像被赋予正确标签的要求在医学图像领域无法完全满足,这是由于医学图像的人工识别往往需要专业的医生,而对海量的数据进行人工标注通常而言是不可行的。深度学习模型如果没有足够的数据进行训练,无法达到准确的测试效果。对于这个问题,许多深度学习研究者通过迁移学习的方法来解决。研究者们会将模型放在如imagenet这样的大数据集上进行预训练,再在经过人工标注的数据集上进行实际训练。这样的预训练方法通常是有效的,能够在一定程度上弥补数据集本身数据量小的缺陷,但也存在一定的问题。预训练的意义是使得模型在实际训练之前具有一定的特征提取能力,而如果预训练任务与实际训练任务差距过大,预训练的增益效果无法得到最大体现。以医学图像中常见的ct图像为例,它与imagenet数据中的图像内容差异过大,预训练任务与实际训练任务存在较大割裂性,以至于达不到有效增强网络的特征提取能力的效果。
6、噪声标签医学数据集乃至现实数据集中常见的问题。在监督学习过程中,大量的准确标注的样本对于网络模型的训练至关重要,在实际应用过程中,对数据进行高质量标注往往需要耗费大量的人力物力财力。此外,标注的数据质量某种程度上还受到人为主观因素的影响,导致实际获取的标注样本时常含有不定比例的噪声标签。实验发现在深度学习模型训练过程中,网络模型总是会学到噪声标签中的信息,对网络的性能带来干扰。为此,如何能够对噪声标签样本进行合理训练避免噪声标签对网络模型的训练带来干扰是近几年的热门研究话题。
7、类不平衡问题同样是深度学习中常见的问题,其是指深度学习任务中不同类别的数据样本在数量上存在较大的差别。对于网络模型训练而言,由于不同类别的数据样本在数据量上差异过大,其训练过程会建模数据集中的数据分布,从而导致网络模型的偏差,即网络在训练过程中,网络模型的训练是以损失函数为导向的,将所有预测样本都判为样本数量大的类别可以实现较低的损失值,所以不采取相应的解决方法,网络模型总会偏向将样本预测为占比更大的类别。然而,带有偏向的模型对于实际应用而言是没有价值的,因为它很难识别到偏向类以外的其他类别。
8、在深度学习研究中,研究者们希望通过训练得到在各个方面都表现优异的网络,但事实往往并非人愿,有时候只能获得带有不同偏向的网络模型。对于训练后的深度学习模型而言,模型集成是提升网络泛化能力,提高结果可靠性的常用手段之一,它被经常使用在各种深度学习研究中,比如图像分割、分类、检测等领域。模型集成方法主要应用于多个模型差异性较大,相关性较小的情况,以有效提升集成模型的性能。从现实情况来看这是容易理解的,比如对于病人的病情进行诊断以及治疗的安排,病患们往往会寻求多个医生的意见,以获得最准确的病情诊断和最佳的治疗方案。在实际操作过程中,研究者们还会以不同的权重来对各个模型进行集成。
9、现有技术中存在以下缺点:
10、1、肾透明细胞癌患者ct图像的数据集不足。
11、2、传统方法应用于医学领域图像处理,特别是ct图像处理,以imagenet为预训练数据集存在预训练任务与实际训练任务关联性小的问题,从而使得预训练方法无法很好地帮助网络模型提升其特征提取能力。
12、3、传统网络模型在训练过程中会受到噪声数据带来的影响。
13、4、数据集中存在的类不平衡问题。
14、5、传统的模型集成方法中,不同网络模型的权重会十分相近,几乎等同于平均加权法,无法体现出不同网络性能的差异,从而进行有效地集成。
技术实现思路
1、为解决上述背景技术中提出的问题,本发明提供基于深度学习构建肾透明细胞癌分级模型的方法,以解决现有技术中ct图像的数据集不足、无法很好地帮助网络模型提升其特征提取能力、受到噪声数据带来的影响、存在的类不平衡问题和网络模型的权重会十分相近的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、基于深度学习构建肾透明细胞癌分级模型的方法,包括以下步骤:
4、s1:获取肾透明癌细胞患者的ct图像;
5、s2:基于vgg网络模型对ct图像进行切割,聚焦肿瘤区域,统一图像规格,获得切割图像;
6、s3:进入预训练阶段,对切割图像进行旋转生成操作并标注,基于regnety400mf、regnety800mf、se-resnet50和resnet101四类网络模型,以普通交叉熵为损失函数,使用旋转后的切割图像对四类网络模型进行预训练;
7、s4:进入实际训练阶段,在普通的交叉熵中加入噪声修正策略为损失函数,对经过预训练的四类网络模型进行实际训练;
8、s5:进入测试阶段,实际训练完成后的四类网络输出ct图像,对患者的病理进行诊断,并获得四类网络模型的表现auc;
9、s6:进入集成阶段,以四类网络模型的表现auc作为其权重,对患者的最终诊断进行加权计算,得到其最终诊断。
10、优选地,s3中,旋转生成操作一共包括四种:
11、第一种:原图不旋转;
12、第二种:原图顺时针旋转90°;
13、第三种:原图顺时针旋转180°;
14、第四种:原图顺时针旋转270°;
15、每一张旋转后的图像都设置标签,对应为原图顺时针旋转90°的次数,即:
16、原图标签为0;
17、旋转90°的图像标签为1;
18、旋转180°的图像的标签为2;
19、旋转270°的图像的标签为3。
20、优选地,s2中,定义预训练任务为判定ct图像顺时针旋转了多少次90°,训练伦次至少为60轮;
21、s3中,针对实际训练任务,定义标签为0与1分别对应病例等级为轻度患者和重度患者。
22、优选地,噪声修正策略具体为:
23、设已经标注了标签的数据集记为:
24、其中xi为患者的ct图像,yi为对应ct图像的标签,n为数据集中所有ct图像的总数量;
25、在深度学习网络模型的训练过程中,普通的交叉熵损失函数如下:
26、
27、其中,如果yi=j,则lij=1,否则,lij=0;
28、pij是第i个样本属于第j类的网络输出概率;
29、在网络训练过程中加入lce_2,在网络模型的训练过程中,设噪声率为α,0≤α≤1,损失函数ltotal如下:
30、
31、
32、
33、若yi=0,则li0=1,否则,li0=0,pi0是第i个样本属于第0类轻度患者的网络输出概率。
34、优选地,加权方法具体为:
35、设经过噪声问题处理后0类样本对应的ct图像总数量为n0;
36、经过噪声问题处理后1类(重度患者)样本对应ct图像总数量为n1;
37、所有ct图像的样本数量为nmax;
38、样本赋权方法以对应类别中ct图像数量的反比作为加权依据,样本权重为另一类样本数量占总量的比值,则:
39、0类在损失函数的计算时对应的权重为
40、1类在损失函数中对应的权重为
41、交叉熵e(·,·),对于训练样本(xi,yi),网络模型对其的输出概率为则加权的交叉熵损失函数如下:
42、
43、新的总损失函数如下:
44、
45、优选地,s6集成阶段具体为:
46、设四类不同网络模型通过计算得到的集成权重分别为γ1,γ2,γ3,γ4;
47、且对于第i位病患四类网络模型的预测结果分别位gi1,gi2gi3gi4;
48、则对于该患者的最终综合预测结果fi为:
49、
50、与现有技术相比,本发明的有益效果是:
51、1、本发明构建了肾透明细胞癌患者ct图像的数据集,为提高数据集图像质量,聚焦肾透明癌细胞研究,本发明以vgg网络模型为主干网络,对ct图像进行了肾脏肿瘤区域的检测与分割,使得网络模型在训练过程中能够更好地专注于肿瘤特征的提取,从而提高网络模型的性能。
52、2、本发明提出了基于自监督的预训练方法,让网络模型在预训练任务中判断ct图像进行的旋转生成操作,在实际任务中判断ct图像对应患者的病理等级,从而使得网络模型在预训练任务与实际训练任务中使用相同的ct图像,且不泄露数据的原始语义,能够有效地增强预训练任务与实际训练任务的关联性,提升网络模型的特征提取能力,提高预测模型的准确度。
53、3、针对数据集中存在的噪声问题,本发明首先对噪声数据进行了分布的建模,并基于噪声数据分布准确的分析,通过在网络模型训练过程中加入噪声修正项,纠正网络模型在训练过程中噪声数据带来的影响,提升了网络模型的性能,提高了预测模型的准确度。
54、4、针对数据集中存在的类不平衡问题,本发明结合对于噪声问题处理的方法,在普通的交叉熵中加入噪声修正策略作为损失函数,提升了模型的性能。
55、5、本发明提出了一种针对模型性能表现接近情况下的加权模型集成方法,实现了更有效的模型集成,达到了更好的最终预测准确度。
- 还没有人留言评论。精彩留言会获得点赞!