一种基于三重词频方案的Ad-hoc信息检索模型
本发明属于信息,具体是一种基于三重词频方案的ad-hoc信息检索模型。
背景技术:
1、现代文档检索模型,如向量空间模型或概率模型,核心是使用一种文档排名函数。给定任何查询文档,利用排名函数计算其数值分数。因此,给定集合中的所有文档就可以正确排名。这些排名函数中几乎都采用启发式方法,解决词频(term-frequency,tf)、文档频率(document-frequency,df)和文档长度(document-length,dl)等因素之间的关系,其中tf通常在这些函数中起到核心作用。
2、基于向量空间的检索模型和概率检索模型中,文档长度直接应用于规范化tf。在本发明中这样的模型称为文档长度规范化的词项频率(document length normalizedterm frequency,ltf)模型。在这些模型的排名函数中引入一个参数来控制dl,从而应用归一化到tf中。然而,在语言模型中,生成文档中一个词项的概率是通过直接使用dl作为除数来确定的。关于向量空间模型,通常认为,当tf不仅被dl规范化,而且相对于文档内平均词频限制时,一个词项的显著性可以更好地被捕捉到。本发明中称这样的模型为相对文档内词项频率(relative term frequency,rtf)模型。同时,在基于bm25和语言建模的框架中引入了基于接近度的词项频率,其中两个给定词项在文档中的关联接近程度是通过测量这两个词项的共现之间的距离来定量捕获的,本发明中称之为基于接近度的词项频率(proximity-basedterm frequency,ptf)模型。
3、本质上,ltf、rtf和ptf提供了三种不同的规范化/调节tf因子的方法。ltf和rtf是词项独立的,并且更适合长查询或短查询。现有的基于向量空间框架的有效检索模型,有matf、mvd和pdm。而ptf是查询词项相关的模型,计算指定距离内的词项共现次数,用于衡量词项关联性。现有技术中,ptf已被整合进基于bm25和语言建模框架的模型中,并获得了不错的效果。在向量空间框架中,ptf与伪相关反馈机制一起使用,用于衡量反馈文档中的候选词项。
4、基于词频的加权方案广泛应用于现代信息检索模型。许多现有模型使用文档长度规范化的词项频率(document length normalized term frequency,ltf)、相对文档内词项频率(relative term frequency,rtf)或基于接近度的词项频率(proximity-basedterm frequency,ptf),来规范化/调整词项频率因素,以实现对文档的有效检索。但是并没有将ltf、rtf和ptf三种调节因子方法,组合在一起用于信息检索的检索模型。
5、如果能将ltf、rtf和ptf三种调节因子方法结合在一起,综合各个方法的特点,用于信息检索,将能够解决面对不同长度,不同特点的,不同形式的文档的有效检索问题。
技术实现思路
1、本发明的目的在于:提供一种基于三重词频方案的ad-hoc信息检索模型,本发明中的三重词频方案(triple aspects-based term frequency scheme,triatf),即线性组合ltf、rtf和ptf三种调节因子方法;本发明将ltf和rtf与查询长度因子相结合,最后再与ptf线性组合,通过词频加权的方式构建出检索模型,以实现对文档的有效检索。
2、技术内容:一种基于三重词频方案的ad-hoc信息检索模型,所述检索模型的构建包括以下步骤:
3、步骤一、计算ltf、rtf和ptf排名函数,并进行归一化处理,得到它们相应的表示函数tf1、tf2和tf3;其中,ltf表示长度正则化的词项频率;rtf表示相对文档内词项频率;ptf表示基于接近度的词项频率;
4、步骤二、对tf1、tf2和tf3函数进行线性组合,基于tf1、tf2和tf3函数线性组合结果,得到检索模型。
5、进一步的,所述步骤一中进行归一化处理时,使用的归一化函数为f(x)=x/(1+x),其中x表示ltf、rtf和ptf排名函数的其中一个,f(x)表示相应的表示函数tf1、tf2或tf3。
6、进一步的,所述步骤一中,将ltf排名函数归一化处理得到表示函数tf1,操作步骤如下:
7、ltf排名函数表示为:
8、
9、其中,ltf(t,d)表示长度正则化的词项频率;d表示文档;t表示文档d中的词项;tf(t,d)表示文档d中词汇t的频率;avdl指给定文献集合c中的平均文档长度;|d|表示文档的长度;
10、使用函数f(x)=x/(1+x)来归一化ltf(t,d),则有:
11、tf1(t,d)=ltf(t,d)/(1+ltf(t,d)) (2)
12、其中,tf1(t,d)表示规范化后的长度正则化的词项频率。
13、进一步的,所述步骤一中,将rtf排名函数归一化处理得到表示函数tf2,具体操作如下:
14、rtf排名函数表示为:
15、
16、其中,rtf(t,d)表示相对文档内词项频率;d表示文档;t表示文档d中的词项;tf(t,d)表示文档d中词汇t的频率;avgtf(d)表示文档d的平均词频;
17、使用函数f(x)=x/(1+x)来归一化rtf(t,d),则有:
18、tf2(t,d)=rtf(t,d)/(1+rtf(t,d)) (4)
19、其中,tf2(t,d)表示规范化后的相对文档内词项频率。
20、进一步的,所述步骤一中,将ptf排名函数归一化处理得到表示函数tf3,具体操作如下:
21、ptf排名函数公式为:
22、ptf(t,d)=∑q∈q,q≠t,prox(t,q,d) (5)
23、其中,q表示查询,q表示q中的一个查询词项;ptf(t,d)表示基于接近度的词项频率;d表示文档;t表示文档d中的词项;
24、prox(t,q,d)表示文档d中词项t和查询词项q之间的接近程度,公式为:
25、
26、其中,dist(t,q,d)是文档d中词项t和查询词项q之间的距离,σ是一个归一化参数;
27、使用函数f(x)=x/(1+x)来归一化ptf(t,d),则有:
28、tf3(t,d)=rtf(t,d)/(1+rtf(t,d)) (8)
29、tf3(t,d)表示规范化后的基于接近度的词项频率。
30、进一步的,通过添加查询项的idf部分对prox(t,q,d)进行优化,prox(t,q,d)优化后为;
31、
32、进一步的,所述步骤二的具体操作步骤如下:
33、步骤(1)、使用查询长度因子ω=2/[1+log2(1+|q|)]来组合tf1和tf2,得到:
34、tf(1,2)(t,d)=(1-ω)·tf1(t,d)+ω·tf2(t,d) (9)
35、其中,d表示文档;t表示文档d中的词项;ω表示查询长度因子;tf1(t,d)表示规范化后的长度正则化的词项频率;tf2(t,d)表示规范化后的相对文档内词项频率;
36、步骤(2)、然后将tf(1,2)(t,d)与tf3线性组合,生成以下结果:
37、tftri(t,d)=(1-λ)·(tf(1,2)(t,d))+λ·tf3(t,d) (10)
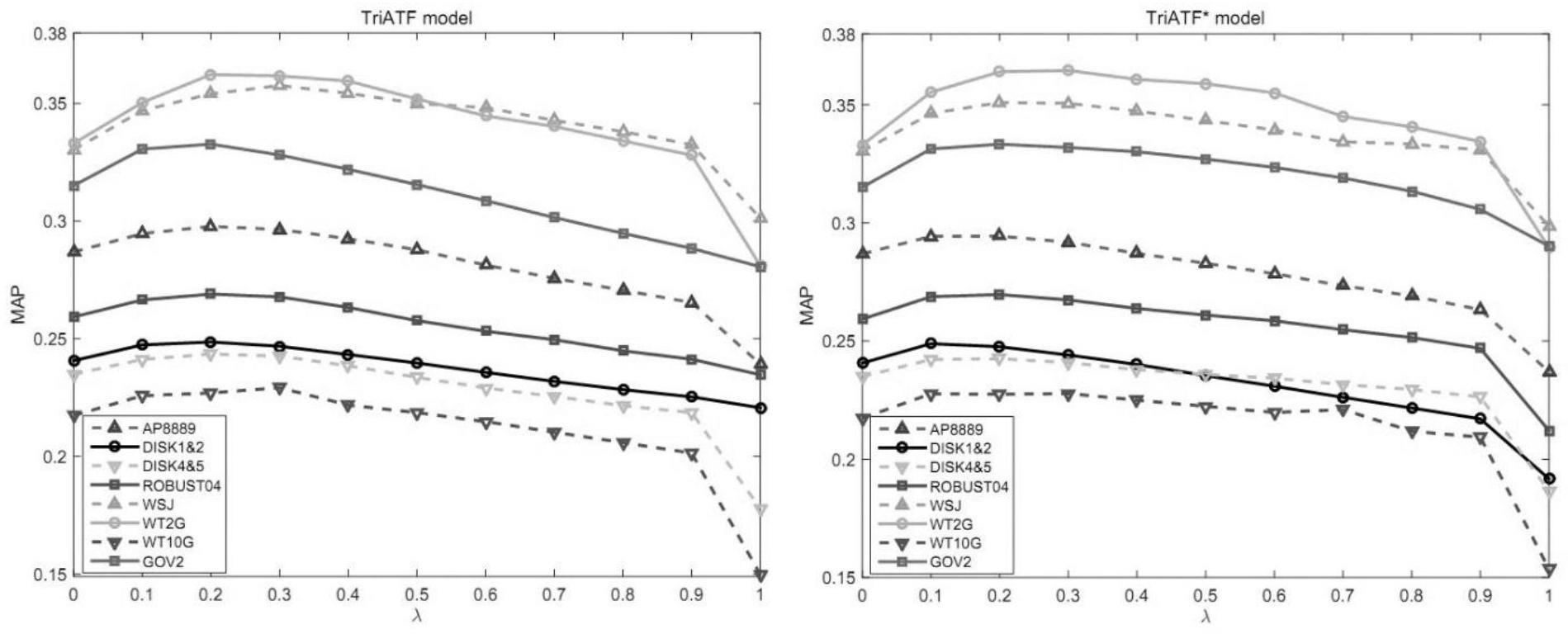
38、其中,λ表示tf(1,2)(t,d)与tf3线性组合的权重系数,取值范围[0,1];
39、步骤(3)、通过以下式对idf进行优化改进,得到tdf:
40、
41、其中,idf(t)表示逆文档频率,定义为log2[(n-n(t)+0.5)/(n(t)+0.5)],其中n是文献集合中的文档数,n(t)是包含t的文档数;ctf(t)表示t在文献集合中的频率;tdf(t)表示改进后的idf(t);
42、步骤(4)、结合tf1、tf2和tf3函数线性组合结果和优化改进后的逆文档频率,得到检索模型:
43、score(q,d)=∑t∈qtftri(t,d)·tdf(t) (12)
44、其中,score(q,d)表示得到的检索模型;tftri(t,d)表示tf(1,2)(t,d)与tf3线性组合;tdf(t)表示改进后的idf(t)。
45、与现有技术相比,本发明的有益效果在于:
46、(1)本发明构建的检索模型triatf和triatf*,将ltf、rtf和ptf线性地结合起来,充分利用这些词频的优势,实现更高效的文档检索,简单实用。
47、(2)检索模型triatf和triatf*,还可以灵活控制ltf、rtf和ptf各自对模型的贡献度,优化检索模型。通过调整ltf和rtf之间的插值参数,控制ltf和rtf相对于ptf的整体权重即应用于ptf的参数,实现控制三个词频对模型的贡献权重。
- 还没有人留言评论。精彩留言会获得点赞!