一种基于科技政策的资源分类筛选方法和系统与流程
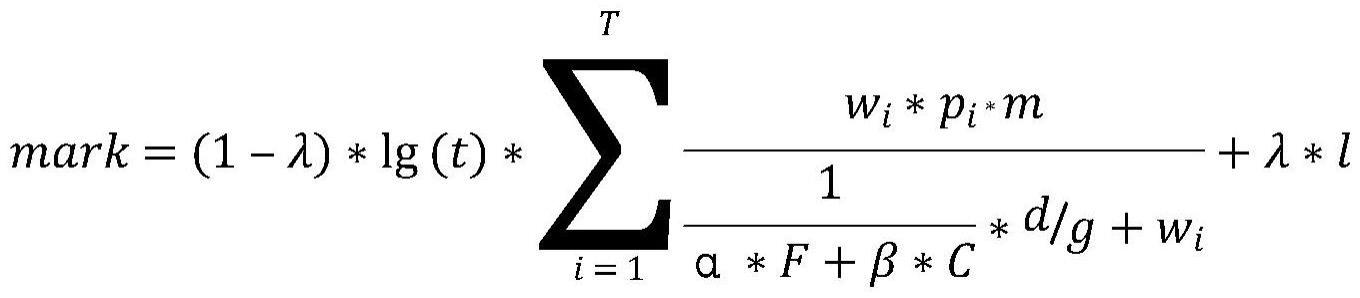
本发明提出了一种基于科技政策的资源分类筛选方法和系统,属于自然语言处理。
背景技术:
1、科技政策是由国家或地方政府机构为促进经济社会发展,基于社会需求在不同阶段制定颁布的,一系列用于规制和激励全社会从事知识发现、积累,以及应用于技术创新行为的政策集合,包括规划计划、法规条例、决定、办法、措施,以及相应的实施细则、意见建议等。
2、而政府发布的科技政策往往能够反映出当前市场和行业的发展趋势。及时了解和掌握这些政策,可以帮助企业把握市场机遇,做出更为明智的决策。随着人工智能技术的发展,将人工智能与科技领域相结合成为了当前研究的热点。
3、当前网络平台搜索科技政策得到的内容冗余,有时内容直接来自个体发布者,不具有权威性,不能很好地服务于使用者,本发明通过爬取权威的政策服务平台,并且在处理数据的过程中多次清洗数据,筛选掉重复的内容,并且根据文本长度,文档向量和查询向量等因素设计模型,使比较重要的政策出现在检索页面比较靠前的位置,能更好地服务于使用者。
技术实现思路
1、本发明提供了一种基于科技政策的资源分类筛选方法及系统,用以解决上述提到的问题。
2、本发明提出的一种基于科技政策的资源分类筛选方法,所述方法包括:
3、获取待处理科技政策内容文本;
4、确定分类维度后,提供所述待处理科技政策内容文本的人工标注接口,再对经过人工标注的科技政策文本进行清洗,得到精简的科学政策文本;
5、对所述精简的科技政策文本进行关键词提取,将提取到的所述关键词拼接在所述精简的科技政策文本标题后面作为训练文本形成数据集;
6、将所述数据集划分为训练集和测试集,使用所述训练集对bert模型训练,然后使用所述测试集对训练好的模型进行测试,计算模型的分类准确度、精度和召回率,并根据实验结果对模型进行优化和改进,根据优化后的模型提供用户检索界面。
7、进一步的,获取待处理科技政策内容文本,包括:
8、获取源科技政策内容文本;
9、基于正则表达式匹配规则生成待处理科技政策内容文本,所述待处理科技政策内容文本包括政策文本、政策标题、政策链接、发布时间、发布单位和扶持类型信息。
10、进一步的,确定分类维度后,提供所述科技政策文本人工标注接口,再对经过人工标注的科技政策文本进行清洗,得到精简的科学政策文本,包括:
11、对所述待处理科技政策清洗,去除内容重复的科学政策文本;
12、确定分类维度为主题领域、政策目标和政策来源,提供将所述科技政策文本分为上述三个维度的人工标注接口;
13、对经过人工标注的科技政策文本再次数据清洗,去除html标记和特殊字符、停用词、拼写错误、多余空格和换行符,获得所述精简的科学政策文本。
14、进一步的,对所述精简的科技政策文本进行关键词提取,将提取到的关键词拼接在所述精简的科技政策文本标题后面作为训练文本形成数据集,包括:
15、将精简的科技政策文本进行分词处理,采用jieba将每个句子切分为一个个的单词或短语,采用关键词提取算法tf-idf对分词后的文本进行关键词提取;
16、对提取出的关键词进行去重和筛选,将筛选好的关键词与原始标题拼接在一起,构成新的训练文本,将所有拼接好的训练文本整合成一个数据集并进行格式化处理。
17、进一步的,将所述数据集划分为训练集和测试集,使用所述训练集对bert模型训练,然后使用所述测试集对训练好的模型进行测试,根据实验结果对模型进行优化和改进,提供用户检索界面,包括:
18、将原始的数据集按照一定的比例划分为训练集和测试集,采用75%的数据作为训练集,剩余的数据用于测试集;
19、使用所述训练集对bert模型进行训练,并通过交叉验证的方式选择最佳的模型参数和超参数;
20、使用所述测试集对训练好的模型进行测试,计算模型的分类准确度、精度和召回率,评估模型的性能和效果,根据评估结果对模型进行优化和改进;
21、基于经过训练和优化的bert模型,提供用户检索界面,当用户输入文本检索时,检索到的科技政策文本依据以下模型算出排序指标,按照排序指标的高低呈现给用户,指标越高越靠前,其中,科技政策文本依据模型如下:
22、
23、其中,mark表示该篇文档排序指标,λ是控制关键词和相似度两个部分对评分的影响权重的参数,
24、
25、其中,t表示该篇科技政策文本命中的关键词总数,s表示该篇科技政策文本所有关键词总数,t表示该篇科技政策文本发布时间,wi表示关键词权重,pi表示关键词位置权重,d表示本文档长度,g表示平均文档长度,l表示文档向量和查询向量之间的余弦相似度得分,α是可调节参数,用于控制词频对文档排序指标的影响,α的取值范围在[0.5,2]之间,f表示文档频率,β是可调节参数,用于控制逆文档频率对文档排序指标的影响,β的取值范围在[0,log(m/y)]之间,m是检索到的文档总数,y是包含查询中某个关键词的文档数量,c表示逆文档频率,
26、
27、其中,f表示关键词在文档中出现的次数,w表示文档总词数,
28、
29、其中,d表示检索到的文档总数,v表示包含该单词的文档数。
30、l=(dv*qv)/(||dv||*||qv||)
31、其中,*表示向量的点积,||.||表示向量长度,dv表示输入文档的向量表示,qv表示查询文本的向量表示,
32、
33、其中,e是输入文本第i个单词的权重,f是输入文本第i个单词的向量表示,
34、
35、其中,h是检索到的文本中第i个单词的权重,j是检索到的文本中第i个单词的向量表示。
36、本发明提出的一种基于科技政策的资源分类筛选系统,所述系统包括:
37、获取初始文本模块,用于获取待处理科技政策内容文本;
38、人工标注并清洗模块,确定分类维度后,提供所述科技政策文本人工标注接口,再对经过人工标注的科技政策文本进行清洗,得到精简的科学政策文本;
39、形成数据集模块,对所述精简的科技政策文本进行关键词提取,将提取到的关键词拼接在所述精简的科技政策文本标题后面作为训练文本形成数据集;
40、模型训练模块,将所述数据集划分为训练集和测试集,使用所述训练集对bert模型训练,然后使用所述测试集对训练好的模型进行测试,计算模型的分类准确度、精度和召回率指标,并根据实验结果对模型进行优化和改进,再提供用户检索界面。
41、进一步的,所述获取待处理科技政策文本模块包括:
42、去噪模块,用于获取源科技政策内容文本;
43、生成待处理政策文本模块,用于基于正则表达式匹配规则生成待处理科技政策内容文本,所述待处理科技政策内容文本包括政策文本、政策标题、政策链接、发布时间、发布单位和扶持类型信息。
44、进一步的,所述人工标注并清洗模块包括:
45、数据清洗模块,用于对数据清洗,去除内容重复的科学政策文本;
46、人工标注接口模块,确定分类维度为主题领域、政策目标和政策来源,提供将所述科技政策文本分为上述三个维度的人工标注接口;
47、数据再清洗模块,用于对经过人工标注的科技政策文本再次数据清洗,去除html标记和特殊字符、停用词、拼写错误、多余空格和换行符。
48、进一步的,所述形成数据集模块包括:
49、关键词提取模块,将精简的科技政策文本进行分词处理,采用jieba将每个句子切分为一个个单词或短语,采用关键词提取算法tf-idf对分词后的文本进行关键词提取;
50、标题拼接关键词模块,用于对提取出的关键词进行去重和筛选,将筛选好的关键词与原始标题拼接在一起,构成新的训练文本,将所有拼接好的训练文本整合成一个数据集并进行格式化处理。
51、进一步的,所述模型训练模块包括:
52、数据集划分模块,用于将原始的数据集按照一定的比例划分为训练集和测试集,采用75%的数据作为训练集,剩余的数据用于测试集;
53、交叉验证模块,用于使用所述训练集对bert模型进行训练,并通过交叉验证的方式选择最佳的模型参数和超参数;
54、优化模型模块,用于使用所述测试集对训练好的模型进行测试,计算模型的分类准确度、精度和召回率,评估模型的性能和效果,根据评估结果对模型进行优化和改进;
55、检索排序模块,用于基于经过训练和优化的bert模型,提供用户检索界面,当用户输入文本检索时,检索到的科技政策文本依据以下模型算出排序指标,按照排序指标的高低呈现给用户,指标越高越靠前,其中,科技政策文本依据模型如下:
56、
57、其中,mark表示该篇文档排序指标,λ是控制关键词和相似度两个部分对指标的影响权重的参数,
58、
59、其中,t表示该篇科技政策文本命中的关键词总数,s表示该篇科技政策文本所有关键词总数,t表示该篇科技政策文本发布时间,wi表示关键词权重,pi表示关键词位置权重,d表示本文档长度,g表示平均文档长度,l表示文档向量和查询向量之间的余弦相似度得分,α是可调节参数,用于控制词频对文档排序指标的影响,α的取值范围在[0.5,2]之间,f表示文档频率,β是可调节参数,用于控制逆文档频率对文档排序指标的影响,β的取值范围在[0,log(m/y)]之间,m是检索到的文档总数,y是包含查询中某个关键词的文档数量,c表示逆文档频率,
60、
61、其中,f表示关键词在文档中出现的次数,w表示文档总词数,
62、
63、其中,d表示检索到的文档总数,v表示包含该单词的文档数。
64、l=(dv*qv)/(||dv||*||qv||)
65、其中,*表示向量的点积,||.||表示向量长度,dv表示输入文档的向量表示,qv表示查询文本的向量表示,
66、
67、其中,e是输入文本第i个单词的权重,f是输入文本第i个单词的向量表示,
68、
69、其中,h是检索到的文本中第i个单词的权重,j是检索到的文本中第i个单词的向量表示。
70、本发明有益效果:通过使用bert模型对科技政策文本进行分类,可以自动化地实现文本分类,提高处理效率和准确度,节省人力成本;通过对精简的科技政策文本进行关键词提取,可以将重要信息提炼出来,缩短阅读时间,提高工作效率;根据模型的分类准确度、精度和召回率指标进行优化和改进,可以逐步提高模型的性能,使其更加准确和可靠;通过将优化后的bert模型嵌入到用户检索界面中,并根据模型将检索到的页面根据得分排序,将匹配度更高的呈现在检索页面前面,可以实现快速、准确的科技政策检索,为用户提供更好的服务体验。
- 还没有人留言评论。精彩留言会获得点赞!