一种基于点框架的高精度人群计数方法
本发明涉及人群计数,尤其是指一种基于点框架的高精度人群计数方法。
背景技术:
1、人群计数在计算机视觉领域扮演着越来越重要的角色,其主要任务是输出图像或视频中人群的个体数量。该技术广泛应用于商场客流量统计、公共场所的安全监控、活动现场管理、应急管理、城市交通管理等多个领域。随着深度学习的发展,许多卓越的人群计数模型被提出,人群计数技术的速度和鲁棒性也大幅提升。然而,绝大多数模型处理高密度的场景的结果并不理想。因此,对高密度人群的高精度计数算法迫在眉睫。
2、目前常用的一种高精度的人群密度检测网络,在多个数据集上取得了不错的结果,但因其使用resnet50的结构,对于高密度场景中存在的人群遮挡问题、远景人像模糊问题的预测效果较差,不能准确还原图像。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术在高密度场景处理过程中针对人群遮挡、远景人像模糊,预测结果不理想的问题。
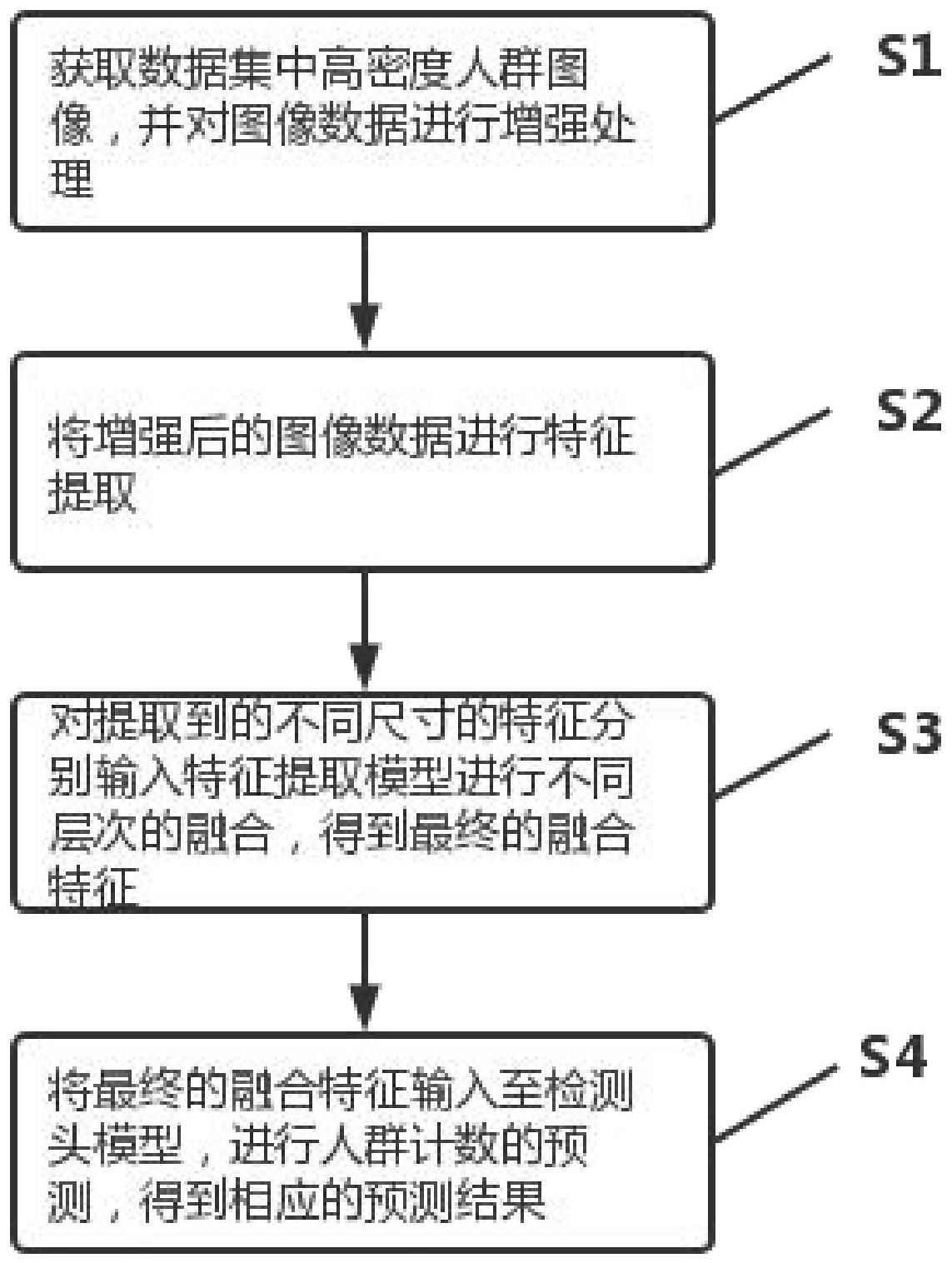
2、为解决上述技术问题,本发明提供了一种基于点框架的高精度人群计数方法,包括:
3、步骤1:获取高密度人群图像,对输入的高密度人群图像数据进行增强处理;将增强处理后的图像数据输入训练完成的高精度人群计数模型中进行计数;
4、所述高精度人群计数模型包括fasternet模型、特征提取模型、检测头模型;其中特征提取模型包括evc模块、第一csplayer模块、第二csplayer模块和cbam模块;
5、步骤2:采用具有4层结构的fasternet模型对增强后的图像数据进行特征的提取;将增强后的图像数据输入所述fasternet模型中,将fasternet模型中第4层、第3层、第2层提取到的特征图分别作为输入,进行特征融合;
6、步骤3:将上述第4层提取到的特征图输入evc模块进行融合;将融合后的新特征通过二倍上采样后与第3层提取到的特征进行拼接;将拼接后的特征输入第一csplayer模块中进行融合;将融合后的新特征通过二倍上采样后与第2层提取到的特征进行拼接;将拼接后的特征输入第二csplayer模块进行融合;将融合后的特征图输入至cbam模块进行融合;cbam输出的结果即为特征融合后的结果;
7、步骤4:将特征融合后的数据输入检测头模型,由检测头输出所预测的图像中待测人群的目标位置,根据目标位置得出人群计数的结果。
8、在本发明的一个实施例中,对于所述高精度人群计数模型进行训练过程包括:
9、获取高密度人群图像训练数据集,定义数据集为标签为表示,n为数据集中图片的数量;
10、其中,xi为数据集中第i张高密度人群图像,大小为m×n,pi为数据集中第i张高密度人群图像的标签,n′为pi中的标记点个数,(xj,yj)表示图像中第j个标记点的横坐标与纵坐标;
11、对训练数据集中的高密度人群图像及标签进行增强处理;将处理后的图像样本输入高精度人群计数模型,得到图像样本的预测点及置信度,使用匈牙利算法将预测点与groundtruth点进行匹配,得到匹配结果,根据匹配结果和置信度定义损失函数,训练模型,直至损失函数收敛。
12、在本发明的一个实施例中,所述对训练数据集中的高密度人群及标签进行增强处理包括:读入高密度人群图像xi后,以0.7至1.3的比例对图像进行随机缩放,再进行128×128大小的随机剪裁,最后用0.5的概率对图像进行水平翻转;
13、对图像标签pi进行点回归,首先对pi进行0.7至1.3比例的缩放,其次选择剪裁出图像中对应的坐标的pi,最后与图像同步翻转。
14、在本发明的一个实施例中,所述使用匈牙利算法将预测点与groundtruth点进行匹配,得到匹配结果包括:
15、高精度人群计数模型输出的预测点的个数为m,groundtruth点的个数为n′,m>n′,用ξ表示算法的匹配结果:
16、
17、其中,pi为ground truth点,为预测点,为匹配后的预测点,表示匹配为正样本的个数,表示匹配为负样本的个数。
18、在本发明的一个实施例中,所述高精度人群计数模型的损失函数包括分类损失、回归损失以及目标数量损失;分类损失为加权的ce损失函数,回归损失为smooth l1损失函数,目标数量损失为focal l1损失函数;
19、加权的ce损失函数表达式为:
20、
21、回归损失函数表达式为:
22、
23、
24、focal l1损失函数表达式为:
25、
26、总体损失函数表达式为:
27、l=λ1lcls+λ2lloc+λ3lnum;
28、其中,为第i个预测点的置信度,α为正样本的权值,ε>0为防止分母为0的非零项,λ1,λ2,λ3分别为加权损失函数、回归损失函数和目标数量损失函数的融合权重系数。
29、在本发明的一个实施例中,所述evc模块包括轻量级mlp与可学习视觉中心机制即lvc两个并行的模块;evc模块读入所述步骤2的输出,将轻量级mlp与lvc两个模块的结果特征映射沿着通道维度连接在一起,作为evc模块的输出。
30、在本发明的一个实施例中,所述第一csplayer模块包括一个baseconv块,其中baseconv块包括一个1×1的卷积层、一个bn层以及一个silu激活函数;
31、第二csplayer模块包括一个baseconv模块和若干个bottleneck块,其中bottleneck包括一个baseconv块和depthwise conv;depthwise conv包括两个baseconv块,其中第一个baseconv块groups为输入特征图通道数。
32、在本发明的一个实施例中,所述cbam模块包括cam与sam两部分;cam模块包括全局平均池化和全连接层,首先通过全局平均池化将输入的特征图在通道维度上进行池化,得到每个通道的全局池化值,然后将所述全局池化值通过全连接层进行处理,得到每个通道的权重向量;所述权重向量用于对输入的特征图的通道维度进行加权。
33、在本发明的一个实施例中,所述cbam模块中,sam模块包括一个压缩-激励操作和一个空间门控操作;压缩-激励操作利用全局平均池化和全连接层的方式,将输入的特征图在通道维度上进行压缩,得到一个通道的激励向量;将所述激励向量与sam模块的输入特征图进行点乘,通过sigmoid函数将结果转化为0到1之间的概率值,表征每个位置的重要程度;通过将输入的特征图乘以重要程度,即通过空间门控操作,强化每个位置的特征响应。
34、在本发明的一个实施例中,所述检测头模型包括回归检测头和分类检测头;回归检测头与分类检测头都包括三个padding为1的3×3卷积层和一个relu激活函数;其中第一卷积的输出通道为回归检测头中设置的featuresize,第二卷积层的输出通道数也为feature size;在分类检测头中,第三卷积层的输出通道数为锚框数量乘以类别数量;在回归检测头中,三卷积层的输出通道数为二倍的锚框数量。
35、本发明的上述技术方案相比现有技术具有以下优点:
36、本发明在对输入的高密度人群图像进行特征提取时,将不同尺度的提取结果均作为输出,对输出的不同尺度的特征图进行特征融合,采用带有注意力的中心化特征金字塔结构,从深层特征层中提取信息对浅层特征进行调整,从而实现对图像中人群密集处存在的相互遮挡部分的特征以及远景处人像模糊的特征达到较好的提取效果,使图像预测的结果更具有准确性,对于高密度人群的预测达到更好的效果。另外,本发明提出的将分类损失、回归损失与目标数量损失结合形成的新的损失函数,能够有效减轻数据标注过程中噪音带来的影响,提高模型的鲁棒性,使得图像预测的结果有较高的准确度。
- 还没有人留言评论。精彩留言会获得点赞!