一种基于混合证据的事实验证方法、系统及存储介质
本发明属于人工智能模型,具体是涉及到一种基于混合证据的事实验证方法、系统及存储介质。
背景技术:
1、近来,随着科技的发展使得信息的传播越来越便利,为了减少大规模虚假信息的传播,就需要人工智能模型来区分真相和不断增加的误导信息。通过人工智能模型可以收集和分析足够的文本证据来验证给定主张或声明的事实验证任务。为了更接近现实场景,事实验证在证据的格式上已经并不局限于文本,传统的文本事实验证已逐渐发展为在开放域设定中基于混合文本和表格证据的验证任务。为了验证给定的主张,需要ai模型对多个句子和单元格证据的组合同时进行语言和符号推理,以生成最终判决。
2、混合证据事实验证任务旨在根据检索到的文本和表格证据验证声明。现有的方法主要集中在证据格式的转换和统一策略上,以便将输入的格式调整为与预训练文本或表格模型的语料库相似的输入。然而,这些模型未能从语言模型中挖掘任务特定知识,以学习输入声明证据对和输出预测判断之间的关系。
3、现有工作通常遵循证据检索和判决预测两步流程来处理这种混合事实验证任务。具体地说,证据检索模块首先提取大量的混合证据,然后判决预测模块诉诸于语言模型来捕获关于输入声明-证据对的上下文关系。为了将来自不同资源的证据进行组合,这些方法通常侧重于通过句子到表格或表格(单元格)到句子的转换实现证据的格式统一。尽管取得了进展,但昂贵的证据预处理时间和有限的性能增益并不能使证据格式统一成为一个有效的解决方案。
4、为了更好地利用语言模型,可以使用自然语言提示来从语言模型中引出输入和输出标签分布之间的语义关系。通常需要在原始输入的末尾添加一些示例(也称为任务演示),然后将其输入到语言模型中,这在多个小样本或非参数学习任务上表现出色。然而,当将这种范式转移到监督学习任务时,性能增益是有限的。在监督学习任务中,当附加语义上相似的例子作为任务演示时,在准确性方面只能实现0.46%的提高,而添加随机的演示甚至会损害语言模型的性能。
技术实现思路
1、本发明提供一种基于混合证据的事实验证方法、系统及存储介质,以解决监督学习任务中语言模型事实验证能力较差的问题。
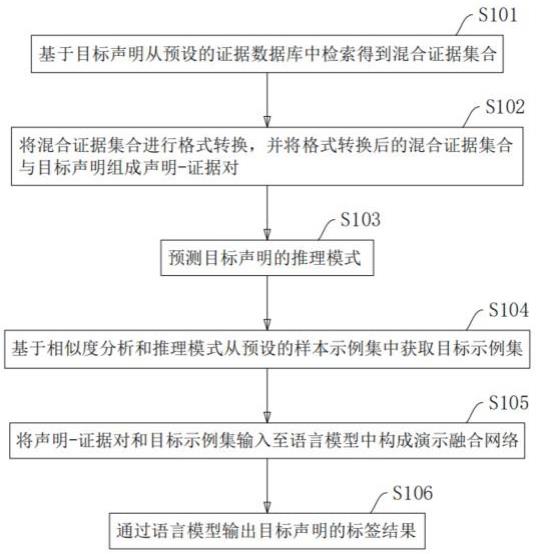
2、第一方面,本发明提供一种基于混合证据的事实验证方法,该方法包括如下步骤:
3、基于目标声明从预设的证据数据库中检索得到混合证据集合;
4、将所述混合证据集合进行格式转换,并将格式转换后的所述混合证据集合与所述目标声明组成声明-证据对;
5、预测所述目标声明的推理模式;
6、基于相似度分析和所述推理模式从预设的样本示例集中获取目标示例集;
7、将所述声明-证据对和所述目标示例集输入至语言模型中构成演示融合网络;
8、通过所述语言模型输出所述目标声明的标签结果。
9、可选的,所述基于目标声明从预设的证据数据库中检索得到混合证据集合包括如下步骤:
10、基于目标声明并通过实体匹配方式从预设的证据数据库中检索得到多个初选证据;
11、将所述初选证据中的表格证据线性化为自然句子格式;
12、计算所有所述初选证据与所述目标声明之间的相似性分数;
13、将所述相似性分数大于预设分数阈值的所述初选证据标记为混合证据;
14、组合所有所述混合证据得到混合证据集合。
15、可选的,在所述组合所有所述混合证据得到混合证据集合之前还包括如下步骤:
16、利用基于roberta的二元序列标注模型筛除所述混合证据中所述表格数据的不相关单元格。
17、可选的,所述基于相似度分析和所述推理模式从预设的样本示例集中获取目标示例集包括如下步骤:
18、通过语义相似度模型计算所述声明-证据对与预设的样本示例集中各个样本示例之间的语义相似度;
19、分别判断各个所述语义相似度是否超出预设的相似度阈值;
20、若所述语义相似度超出所述相似度阈值,则将对应的所述样本示例标记为目标示例;
21、若所述语义相似度未超出所述相似度阈值,则将对应的所述样本示例标记为备选示例;
22、统计所述目标示例的示例数量;
23、判断所述示例数量是否小于预设的数量阈值;
24、若所述示例数量大于等于所述数量阈值,则将所有所述目标示例组成目标示例集;
25、若所述示例数量小于所述数量阈值,则从所有所述备选示例中,依次选取所述语义相似度最高且所述推理模式与所述目标声明相同的所述备选示例作为所述目标示例,直至所述示例数量等于所述数量阈值;
26、将所有所述目标示例组成目标示例集。
27、可选的,所述将所述声明-证据对和所述目标示例集输入至语言模型中构成演示融合网络包括如下步骤:
28、将所述声明-证据对分别与所述目标示例集中的各个目标示例构造增强示例;
29、将所述声明-证据对和所述增强示例均输入至语言模型中,得到句子嵌入向量和单词嵌入向量;
30、基于所述句子嵌入向量并通过交叉注意力机制获得句子级任务演示;
31、将所有单词嵌入向量连接为标准矩阵;
32、基于所述标准矩阵并通过所述交叉注意力机制获得单词级任务演示;
33、连接所述声明-证据对、所述句子级任务演示和所述单词级任务演示以构成演示融合网络。
34、可选的,所述句子嵌入向量和所述单词嵌入向量的表达式如下:
35、
36、...
37、,式中:lm表示所述语言模型,表示所述声明-证据对中第i个单词的单词嵌入向量,表示所述增强示例第j个单词的单词嵌入向量,k表示所述增强示例的数量,表示所述句子嵌入向量,,...,表示不同的所述增强示例中第j个词的向量,,...,表示不同的所述增强示例的句子向量,表示所述声明-证据对的句子向量,c表示示例,,...,表示不同所述示例与黄金证据之间的串联关系,表示第一个所述示例的预测概率值,表示示例空间中的示例数量,表示所述示例空间中最后一个所述示例的所述预测概率值,表示用来调整输入的示例的模板。
38、可选的,所述基于所述句子嵌入向量并通过交叉注意力机制获得句子级任务演示包括如下步骤:
39、将所述增强示例和所述声明-证据对的所述句子嵌入向量独立通过单个线性层馈送;
40、计算所述增强示例的所述句子嵌入向量与所述声明-证据对的所述句子嵌入向量之间的向量相似度;
41、将所述向量相似度归一化为注意力权重,所述注意力权重的表达式为:
42、,式中:表示所述注意力权重,和均表示线性层,表示所述句子嵌入向量,t表示转置符号,表示第j个所述增强示例的句子向量;
43、将所有所述增强示例的所述句子嵌入向量与对应的所述注意力权重相乘,得到句子级任务演示,所述句子级任务演示表达式为:
44、,式中:k表示所述增强示例的数量。
45、可选的,所述标准矩阵的大小为(k*n)*h,h为所述语言模型中隐藏层的维度,所述基于所述标准矩阵并通过所述交叉注意力机制获得单词级任务演示包括如下步骤:
46、对所述标准矩阵中对齐的所述单词嵌入向量进行平均池化,得到单词级任务演示,所述单词级任务演示表达式为:
47、,式中:
48、,其中,表示所述声明-证据对中第i个词和所述增强示例中第j个词的注意力权重,kn表示所述增强示例的长度,所述增强示例中第j个词的向量。
49、第二方面,本发明还提供一种基于混合证据的事实验证系统,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如第一方面中所述的方法。
50、第三方面,本发明还提供一种计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的方法的步骤。
51、本发明的有益效果是:
52、本发明所提供的基于混合证据的事实验证方法具体包括如下步骤:基于目标声明从预设的证据数据库中检索得到混合证据集合;将所述混合证据集合进行格式转换,并将格式转换后的所述混合证据集合与所述目标声明组成声明-证据对;预测所述目标声明的推理模式;基于相似度分析和所述推理模式从预设的样本示例集中获取目标示例集;将所述声明-证据对和所述目标示例集输入至语言模型中构成演示融合网络;通过所述语言模型输出所述目标声明的标签结果。该方法利用了一种新颖的演示融合机制来聚合具有与输入演示相同推理模式的大量示例,并改进了演示检索策略,需要先预测目标声明的推理模式,然后根据推理模式选择具有高相似度的示例,避免了语义相关但内容无关的演示。同时构建了演示融合网络,通过该网络首先将声明-证据对以及每个目标示例输入到语言模型中以获得各自的表示,然后通过注意力机制聚合连接的特征,从而最终提高语言模型在监督学习任务中对事实验证的理解能力。
- 还没有人留言评论。精彩留言会获得点赞!