一种基于深度图重构的微服务拆分方法
本发明属于微服务,尤其是涉及一种基于深度图重构的微服务拆分方法。
背景技术:
1、微服务是一种开发软件的架构和组织方法,是面向服务的体系结构(soa)架构样式的一种变体。微服务架构(msa)由许多高度内聚、松耦合、具有自治性和可独立部署的服务组成,具有强大的可维护性、可扩展性、自动化部署和技术选择灵活的特点。且微服务更适合于现在的云原生时代。
2、为了更好的拥抱云原生时代,越来越多商业企业选择将他们现有单体架构的应用拆分成微服务,这需要识别单体应用中的程序边界,合理拆分归纳代码。不正确的拆分方式会严重影响到微服务架构的性能。
3、由于图在表示非结构数据的能力,近两年涌现了一些基于深度图聚类方法的微服务拆分方法,此类方法通过图对单体应用进行建模,将单体应用中的类视为图中的节点,通过边表示程序片段之间的关系,如desai等人在论文“graph neural network to diluteoutliers for refactoring monolithapplication”中提出的cogcn,该方法使用图卷积神经网络学习单体应用中程度片段之间的调用关系,随后人工定义分区(聚类)数量,并通过神经网络方法进行聚类,从而实现微服务拆分。
4、与cogcn类似,qian等人在论文“microservice extraction using graphdeepclustering based on dual view fusion”中提出了gdc-dvf,该方法除了考虑类之间的调用关系,还考虑了类与业务之间的关系,并通过不同的图神经网络学习图中的不同关系,通过语义级别的注意力机制进行多种关系的聚合。随后也需要定义分区数量(即微服务的数量),并引入了fcm聚类方法将单体应用中的类进行分组,从而实现微服务拆分。
5、相比一些传统方法,上述通过引入图神经网络进行单体应用中类与类之间关系的学习以进行微服务拆分的方法取得了可观的效果,但由于神经网络优化过程的限制,上述基于深度图聚类的方法在具体实践过程中需要人工定义分区数量(即微服务的数量)。这不仅影响了微服务拆分过程的自动化程度,还会因为错误的分区数量初始化影响所得出的微服务架构的综合性能。这种情况在大规模的单体应用中更加普遍。错误的分区数量还会导致极端分布(即多个微服务中仅包含一个类)的问题。
技术实现思路
1、本发明提供了一种基于深度图重构的微服务拆分方法,在利用图神经网络充分学习单体应用中的不同关系的同时,可自动确定最优分区数量;在保证微服务拆分结果准确性的同时,减少人工对微服务拆分过程的干预,并避免结果中出现的极端分布情况。
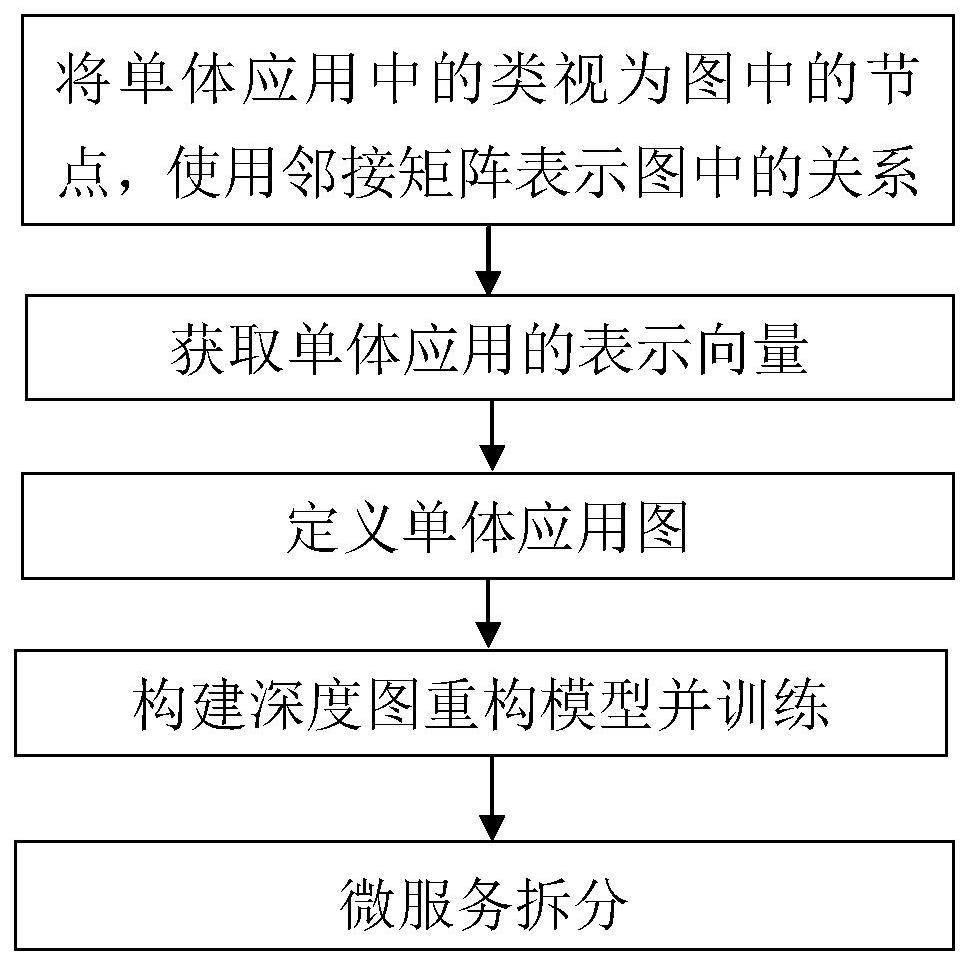
2、一种基于深度图重构的微服务拆分方法,包括以下步骤:
3、(1)将单体应用中的类视为图中的节点,记为c={c1,c2,c3,…cn},n代表单体应用c中类的数量,ci表示其中的第i个类;
4、使用四个邻接矩阵ac、ai、ab、ad表示图中类的关系,其中,ac表示类与类之间的调用关系,ai表示类与类之间的继承关系,ab表示类与业务之间的对应关系,ad表示类与外部资源的对应关系;
5、(2)将单体应用中的类嵌入成表示向量,使得彼此调用频繁的类之间在向量空间中接近;并将所有类的表示向量按顺序进行拼接,作为表示目标单体应用的特征向量v;
6、(3)定义单体应用的图为:g=(v,ac,ai,ab,ad);
7、(4)构建深度图重构模型并进行训练,其中深度图重构模型的结构如下:
8、引入门控图神经网络来进行图g中多种不同关系的学习,分别获得四种关系ac、ai、ab、ad经过门控图神经网络后所对应的结果向量表示;采用语义级注意力机制对四种关系的结果向量进行聚合,获取最终的融合学习多种关系的向量vfinal;并通过多层感知机mlp将vfinal转换为图重构后的邻接矩阵are;
9、(5)对于待拆分的单体应用,收集深度图重构模型所输出重构图的邻接矩阵are,并基于此识别和划定目标单体应用中的功能边界,拆分得到多个微服务。
10、本发明提高了微服务拆分过程中的自动化程度,使得可以在不依赖外部专家知识指导拆分过程和定义拆分数量的前提下进行微服务的拆分,并获得综合表现更好的微服务拆分结果。
11、步骤(1)中,使用四个邻接矩阵ac、ai、ab、ad表示图中类的关系具体包括:
12、ac表示目标单体应用中类和类之间的调用关系,当第i个类ci和第j个类cj之间存在调用关系时,令ac[i][j]=ac[j][i]=1,否则ac[i][j]=ac[j][i]=0;
13、ai表示目标单体应用中类和类之间的继承关系,当ci和cj之间存在继承关系时,令ai[i][j]=ai[j][i]=1,否则ai[i][j]=ai[j][i]=0;
14、ab表示类与业务之间的对应关系,当ci和cj属于同一个业务时,令ab[i][j]=ab[j][i]=1,否则ab[i][j]=ab[j][i]=0;
15、ad表示类与外部资源的对应关系,当ci和cj访问了同一个外部资源,令ad[i][j]=ad[j][i]=1,否则ad[i][j]=ad[j][i]=0。
16、其中,ac、ai、ab、ad均属于{0,1}n*n,即值为0或1的n*n大小的矩阵。
17、步骤(2)的具体过程为:
18、首先通过神经网络随机为每一个类生成一个嵌入表示向量,即{v1,v2,v3,…vn},其中vi为第i个类ci的嵌入向量表示,vi∈rd,代表vi为d维的实数向量;
19、在进行v的优化时,对于目标单体应用中任意两个类ci和cj,首先计算ci和cj在空间n*n中的联合概率分布p1(ci,cj),随后,计算空间n*n中的经验概率分布
20、通过最小化联合概率分布p1(ci,cj)和经验概率分布之间的差距以进行嵌入表示向量v的优化,使得彼此之间调用频繁的两个类之间的嵌入向量尽量相似;随后根据所计算的损失,通过反向传播进行表示向量的自动训练和更新;
21、当训练至收敛后,将所有类的表示向量按顺序进行拼接,记为v,其中v∈rn×d,即v为n*d维度的实数向量,作为表示目标单体应用的特征向量。
22、步骤(4)中,定义门控图神经网络的操作为:
23、v(k+1)=ggnn(a,v(k),w,u)
24、
25、其中
26、式中,v(k)为输入的图的特征向量,w、u均为随优化过程进行学习的参数,⊙代表逐元素乘法操作,σ是sigmoid函数;为邻接矩阵a经过拉普拉斯标准化后的结果,φ为非线性的激活函数;
27、根据上式的定义,分别获得ac、ai、ab、ad四种关系经过门控图神经网络后所对应的向量表示:其中,l为对于每一种关系,所设置的门控图神经网络的层数。
28、采用语义级注意力机制对四种关系的结果向量进行聚合的具体过程为:
29、首先根据每种结果的重要程度而获得其对应的注意力权重,如下所示:
30、eij=at([(kvi+b)‖(kvj+b)])
31、
32、
33、其中,k是权重矩阵,b是噪声向量,a是语义级别的注意力机制,ωij为第i个向量和第j个向量之间的注意力权重;通过使用学习到的权重作为系数,将结果的嵌入向量融合起来,得到最终的嵌入vfinal,具体如下所示:
34、
35、多层感知机mlp通过一系列的线性变换和非线性激活函数来实现对输入数据的非线性映射,将vfinal转换为图重构后的邻接矩阵are。
36、深度图重构模型进行训练的过程如下:
37、分别获取按业务集中程度最优进行拆分的结果,记为best_bcp、按通信成本最低时的拆分结果,记为best_icp、按内聚程度最优时的拆分结果,记为best_coh、按耦合程度最优时的微服务拆分结果,记为best_cou;
38、将上述的微服务拆分结果转换为图,将对应的图转换为邻接矩阵,记为abest_bcp,abest_icp,abest_coh,abest_cou;据此对输出重构图的邻接矩阵are进行交叉监督,以计算损失;计算完成损失后,根据损失进行反向传播,进行神经网络中参数的更新,直至损失收敛,获得训练好的模型。
39、步骤(5)中,识别和划定目标单体应用中的功能边界,拆分得到多个微服务具体过程为:
40、首先将图中每个节点初始化为一个独立的分区,然后通过迭代优化来合并分区,直到达到最优的模块度,其中,模块度被定义为:
41、
42、式中,gi代表类ci所属的分区,gj代表cj所属的分区,当u=v时,δ(u,v)等于1,否则等于0;
43、在每一次迭代中,尝试将当前节点的分区标签更新成邻居节点的分区标签,以计算当前节点与其邻居节点合并后的模块度增益,然后选择具有最大模块度增益的节点进行合并;
44、通过这种方式,将目标单体应用中关系紧密的类将逐渐聚集在同一个分区中,而松散类的节点则形成独立的分区,据此形成最优的微服务拆分方式。
45、与现有技术相比,本发明具有以下有益效果:
46、1、本发明解决了在使用图神经网络进行微服务拆分时需要手动定义分区数量(即微服务数量)的问题,在提高微服务拆分结果质量的同时提高了微服务拆分过程的自动化程度。
47、2、在进行模型的优化时,提出了将不同关注点最优时所对应的微服务拆分方案转换为矩阵,并据此对模型进行交叉监督的方法,通过该方法,可使得模型能够更好的关注到微服务拆分过程不同的关注点,获得综合能力更强的微服务拆分结果。
- 还没有人留言评论。精彩留言会获得点赞!