一种基于张量处理的LSTM加速器计算单元的硬件结构
本发明公开了一种基于张量处理的lstm加速器计算单元的硬件结构实现,在具有大量矩阵向量乘法计算的lstm神经网络模型的推理过程中具有更低的延迟和功耗。lstm网络模型的计算过程主要分为矩阵向量乘法模块、element-wise计算模块以及激活函数模块,其中激活函数模块中分为sigmoid函数模块和tanh函数模块。本发明根据不同模块计算特点进行针对性硬件设计。lstm神经网络中有着大量矩阵向量乘法的需求,因此矩阵向量乘法模块采用一种新型脉动阵列结构,对一般的脉动阵列中的乘法和累加单元(mac)进行改进,将乘法器与加法器分开。不同于传统脉动阵列中乘法器与加法器组合在一个统一的mac阵列中的方式,新型脉动阵列结构将乘法器以树形拓扑连接。element-wise计算模块采用时分复用的方式来提高性能。通过将element-wise模块划分为三种不同的状态,element-wise模块中的计算单元可以在不同的状态下进行复用,所以element-wise计算模块只需要一个sigmoid、一个tanh、一个加法器和一个乘法器,有效地节省了资源。激活函数模块分别是sigmoid激活函数和tanh激活函数,sigmoid和tanh激活函数模块可以通过分段线性函数逼近的方法,即线性分割后使用查找表来实现。通过两个ram来存储ai和bi的值,然后通过乘法器和加法器实现激活函数。sigmoid激活函数和tanh激活函数仅在ai和bi的取值上不同。分段线性函数逼近的方法有效解决了直接基于查找表计算而消耗大量内存的问题,以及基于曲线拟合计算存在的计算复杂度高的缺点。
背景技术:
1、在近年来的新型大数据和人工智能应用中,神经网络已成为一个热门研究领域,也成为开发新架构的重要驱动因素。随着对精度、功耗和计算时间的要求越来越高,越来越多的学者热衷于设计和实现适合神经网络的加速器。
2、循环神经网络的代表lstm在语音识别上取得了重大成就,随着网络模型深度的增加,对硬件算力的需求也在增加,而嵌入式设备无法满足如此大需求的算力。因此需要在不影响准确性的前提下,对网络模型进行参数压缩,并针对压缩后的模型进行加速器硬件设计,从而加速lstm神经网络模型的推理。
3、lstm网络模型通过增加门控单元控制节点间的信息流,虽然避免了传统rnn网络的梯度消失和爆炸问题,但每个门结构都带有不同的权值矩阵,大量的权值矩阵与输入向量xt和上一时刻的输出ht-1相乘则带来了大量的、复杂的矩阵向量乘法运算。
4、因此,lstm网络模型硬件加速器的关键在于设计合适的张量计算单元。
5、本发明针对lstm神经网络模型具有大量矩阵向量乘法计算的特点,创新性地提出了基于张量处理的加速器计算单元硬件电路。
技术实现思路
1、本发明的技术目的是:
2、为了加速lstm神经网络模型的推理过程,提供一种基于张量处理的加速器计算单元硬件电路,用以处理lstm神经网络模型中存在的大量矩阵向量乘法计算,进而提高计算速度,加快推理过程。
3、本发明实现的技术方案:
4、本发明设计的基于张量处理的lstm加速器计算单元硬件结构的优化主要包括以下三个部分。第一种部分是矩阵向量乘法模块优化,采用新型脉动阵列结构,对传统脉动阵列中的乘法和累加单元(mac)进行进一步的改进,将乘法器与加法器分开,乘法器以树形拓扑连接,而不是将它们组合在一个统一的mac阵列中。第二种部分是element-wise计算模块优化,通过将element-wise计算模块划分为三种不同的状态,模块中的计算单元在不同的状态下进行复用,从而提高性能。第三部分是激活函数模块优化。sigmoid和tanh激活函数均采用分段线性函数逼近的方法可以有效降低计算复杂度和内存消耗。
5、本发明的矩阵向量乘法计算模块如图1所示。矩阵向量乘法模块采用脉动阵列结构,由一组相互连接的处理单元(pe)组成,每个pe均包含两个输入寄存器r1和r2、一个输出寄存器r3,以及一个乘法器,并且每一行都连接到一个加法器树。所有乘法器在每个时间步长都处于激活状态。具有流数据的r1在阵列中连接成一行,每循环一次,数据都会向右移动一列。数据可以以流水线方式在单元格之间直接流动,脉动阵列与外界的通信只发生在边界单元。
6、本发明的element-wise计算模块的结构如图2所示。element-wise模块划分为三种不同的状态,不同的计算单元在不同的状态下进行复用。在第一个状态s1下,两个输入数据通过sigmoid和tanh运算单元得到输出i和g,然后i与g相乘。第一个状态s1需要用到的计算单元是sigmoid、tanh和一个乘法器。在第二个状态s2下,第三个输入通过sigmoid运算得到输出f,然后f与上一个细胞状态的值ct-1相乘,最后将f*ct-1和i*g相加。在s2状态下需要用到的计算单元是sigmoid、一个加法器和一个乘法器。在第三个状态s3下,第四个输入通过sigmoid运算输出o,ct通过tanh运算得到输出tanh(ct),再将tanh(ct)与g相乘,最终得到输出结果ht。这一状态下需要用到的计算单元是sigmoid、tanh和一个乘法器。由于采用时分复用的方式,所以element-wise计算模块只需要一个sigmoid、一个tanh、一个加法器和一个乘法器。
7、本发明的激活函数模块的结构如图3所示。sigmoid和tanh激活函数模块通过线性分割后使用查找表来实现,一共采用22段分段线性函数来近似逼近,分段函数的公式为f(x)=aix+bi,x∈[xi,xi+1]。硬件上使用两个ram来存储ai和bi的值,不同输入x的值对应不同的ai和bi的值,x与ram a中对应的ai值经过乘法器相乘得到ai*x,然后ai*x与ram b中对应的bi值经过加法器相加得到f(x)=ai*x+bi,最终实现激活函数的近似。
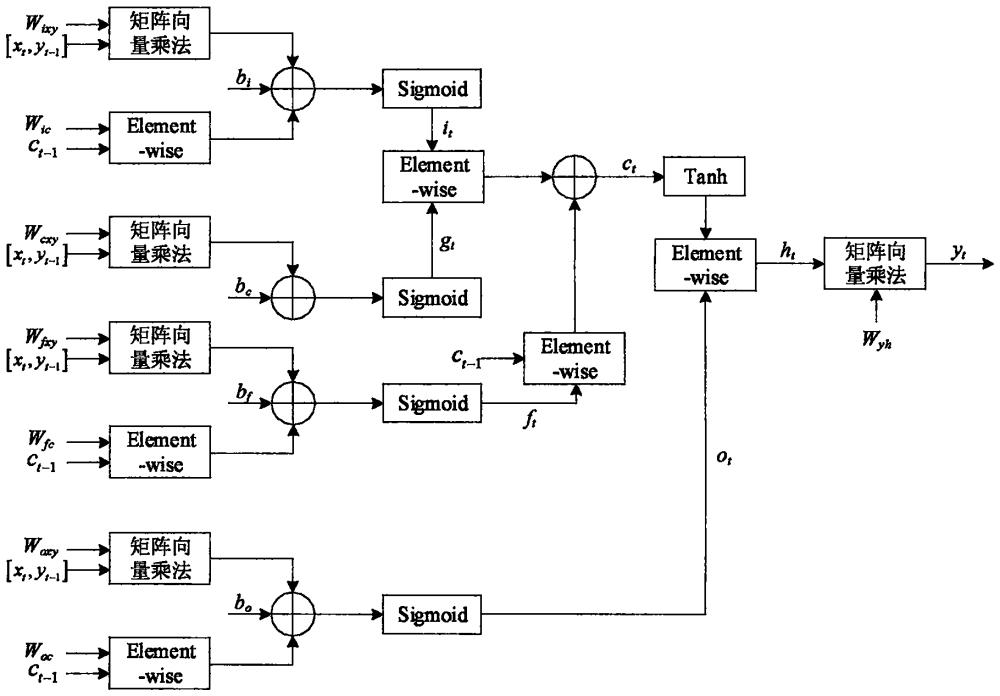
8、本发明的lstm加速器计算单元整体架构如图4所示。lstm模型中不同的算子之间存在严格的数据依赖性,以输入门为例,输入向量xi与上一个输出yt-1组成向量组,与权值矩阵wix共同输入矩阵向量乘法算子,旧细胞状态ct-1与权值矩阵wic共同输入element-wise算子,矩阵向量乘法算子与element-wise算子的输出再与偏置bi共同输入加法器,加法器输出经过sigmoid激活函数算子得到it。同理,遗忘门、输出门经过类似过程得到ft和ot。gt则是输入向量组与权值矩阵共同经过矩阵向量乘法算子之后与偏执bc相加再经过sigmoid激活函数算子得到。it和gt共同输入element-wise算子,旧细胞状态ct-1与ft共同输入element-wise算子,两个element-wise算子的输出再经过加法器得到新细胞状态ct。ct经过tanh激活函数算子与ot共同输入element-wise算子得到ht。ht与权值矩阵wyh经过矩阵向量乘法算子得到输出yt。
9、相比于传统的lstm网络模型加速器计算单元硬件电路,本发明有以下优点:
10、1.降低了lstm中矩阵乘法运算的计算延迟。采用新型脉动阵列结构,对传统的脉动阵列中的乘法和累加单元(mac)进行改进。将乘法器与加法器分开,乘法器以树形拓扑方式连接,而不是组合在一个统一的mac阵列中,有效降低了延迟。
11、2.降低了lstm中element-wise计算模块和激活函数模块的硬件开销。element-wise计算模块采用时分复用的方式,将计算模块划分为三种不同的状态,模块中的计算单元可以在不同的状态下进行复用,所以element-wise计算模块只需要一个sigmoid、一个tanh、一个加法器和一个乘法器。此外,sigmoid和tanh激活函数模块均采用分段线性函数逼近的方法实现。相比曲线拟合或直接查找表的方式,有效降低了计算复杂度和内存消耗。
- 还没有人留言评论。精彩留言会获得点赞!