基于半监督的人类活动数据流检测方法
本发明属于数据流检测,特别是涉及一种基于半监督的人类活动数据流检测方法。
背景技术:
1、随着互联网在人们的生活中逐渐成为不可或缺的一部分,医疗健康、公共安全等领域随着被更多人使用以流的形式产生着各种来源的海量数据,该数据被称为数据流;其中,对人类活动数据流进行检测能够检测出数据流中的异常活动;比如摔倒、帕金森等疾病等。然而如何有用且高效的处理如此庞大的数据流仍是一个巨大的挑战。这是因为流式数据具有很多固有属性,包括连续有序到达、无限长、概念漂移、概念演化、有限标记数据等。因此,构建一个更健壮的模型来快速有效地从看似杂乱的数据中提取有意义的信息变得更为重要。
2、在人类活动数据流处理时,第一个挑战是如何在有限的时间和内存下,处理大量连续到达的在线数据,并在单次扫描中提取有用的信息或模式。第二个挑战是数据流的演化或动态性质,其中数据可能随时间而变化,会产生概念漂移或概念演化现象。因此,基于历史数据构建的学习算法可能会因为概念漂移而过时,学习算法需要对这种变化的概念具有自适应性。然而,与概念漂移等其他众所周知的问题相比,概念演化问题很少受到关注。
3、目前现有方法大多是有监督的,在标记数据稀缺的情况下,可能会导致分类性能较差,效率较低。新类的出现是概念演化的一种情况,新类在数据流中出现较晚,早期无法被学习模型识别。数据流分类中,大多数现有方法都假设类的总数是固定的,并且可以提前为模型所知。这样的假设在很多实际应用中可能不成立,在人类活动数据流检测中,将不同的异常活动视为不同的类标签,种类的数量不固定,随时可能出现完全新颖的异常活动,从而导致新异常活动无法被检测的问题。因此,解决概念演化问题具有重要意义,因为它在提高分类性能方面发挥着关键作用。然而,大多数为研究新类检测而开发的现有算法,对标记数据的可用性做出了不切实际的假设。现有技术假设所有传入数据的真实类标签都是立即可用的,或者在某些延迟之后可用,并且标记的数据可以用来定期更新学习模型。但是在实际数据流应用中,数据以极快的速度出现且数据分布随时间动态变化,这种假设是不切实际的,与事实相去甚远。人工标注所有数据既费时又费力。
4、近年来,一些针对数据流的ssl算法被提出;然而现有的方法仍存在一些局限性。首先,大多数算法都是基于固定大小的块,其分类性能主要取决于块的大小。由于块大小不均,分类器无法有效地学习当前概念。当块大小太大时,一个块可能包含多个概念,在该块上训练的分类器可能会严重降低性能。其次,大多数技术需要优化一个目标函数,这是一个耗时的过程,违反了与数据流挖掘相关的实时处理限制。
技术实现思路
1、本发明实施例的目的在于提供一种基于半监督的人类活动数据流检测方法,通过动态维护一组微集群来提出在线半监督学习,已解决现有技术分类性能较差,效率较低以及无法检测新出现的人类异常活动数据流的问题。
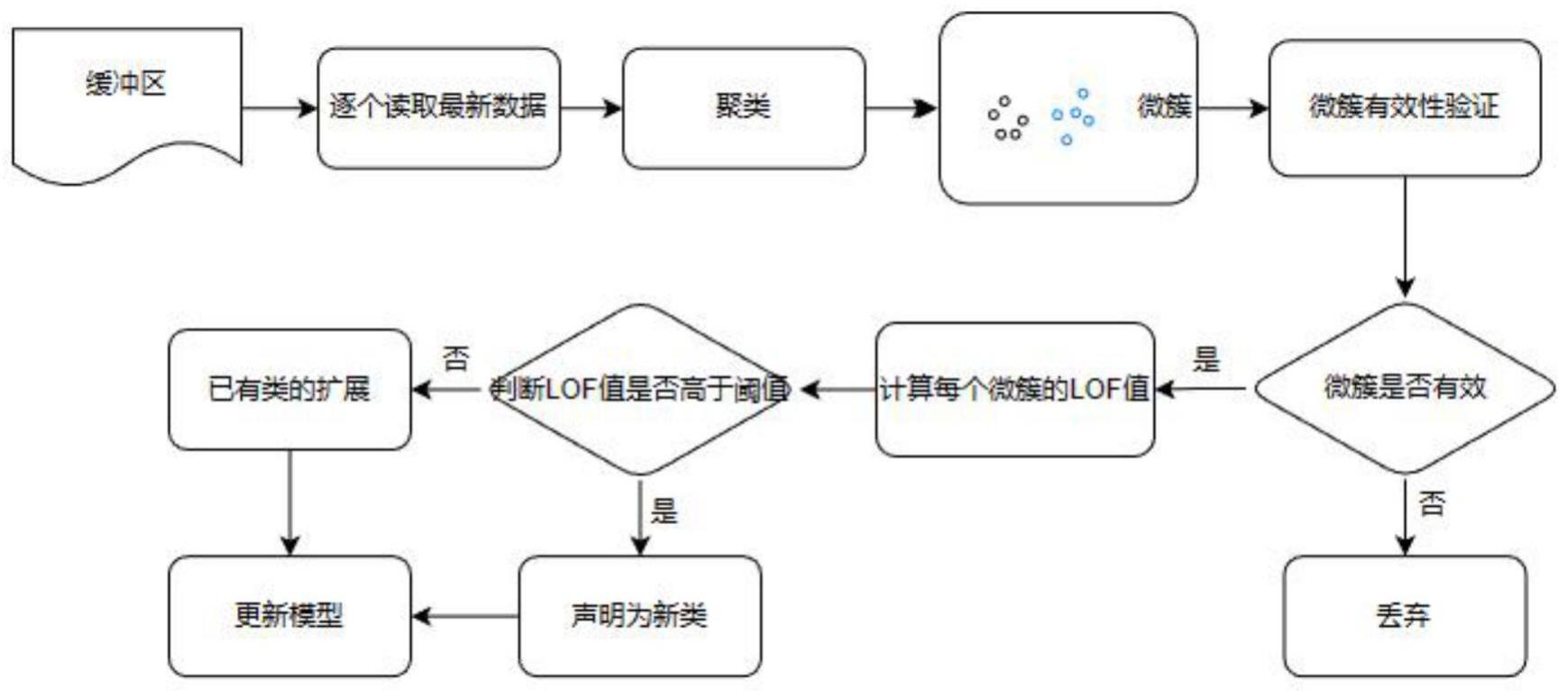
2、为解决上述技术问题,本发明所采用的技术方案是,一种基于半监督的人类活动数据流检测方法,包括以下步骤:
3、s1、构建初始模型:将人类活动数据流数据集分为互不相交的集合,使用聚类算法将每个类数据划分为k个簇;计算微簇半径rmc和中心cmc;
4、s2、新类检测:通过统计微簇中的样本数对微簇进行有效性验证,然后计算有效的微簇局部离群因子并输出新类链表;
5、s3、更新模型:插入新微簇和现有类的扩展;更新现有微簇的统计数据ls、ss、n、π、t,ls表示每个簇ci中类别标签为l的每个类别实例的线性和,ss表示每个簇ci中类别标签为l的每个类别实例的平方和,n表示簇ci中每个类别的实例总数,π存储聚类中每个有标签的类的协方差矩阵,t表示微簇被更新的时间,t的初始值设置为0。
6、进一步的,s1构建初始模型的具体步骤如下:
7、s101、将人类活动数据流数据集分为互不相交的集合,使得每个集合包含一个类的人类活动实例;
8、s102、将人类活动数据流数据样本dinit输入聚类算法,利用聚类算法对人类活动数据流数据样本dinit聚类,产生k个簇,得到一个初始模型;
9、s103、每个簇ci的聚类特征被计算并存储在微聚群mc中,微集群mc由特征ls、ss、n、π、t组成:
10、mc=(ls,ss,n,π,t);
11、s104、计算微簇中每个有标签类的簇特征ls、ss、n、π、:
12、
13、
14、其中,xj表示数据对象;
15、s105、计算微簇半径rmc和中心cmc。
16、进一步的,微簇半径rmc和中心cmc的计算方法如下:
17、微簇半径rmc为簇中数据点与质心之间距离的标准差:
18、
19、中心cmc是所有数据点的平均距离:
20、
21、进一步的,输出新类链表的具体步骤如下:
22、s201、输入人类活动数据流样本、阈值γ;
23、s202、按照类别划分数据集;
24、s203、对每个产生的微簇进行有效性验证,保留有效微簇,并对有效的微簇计算局部离群因子;
25、s204:当计算出的局部离群因子大于阈值γ时,宣布一个新类,将样本加到新类链表中,输出新类链表。
26、进一步的,验证微簇有效性的具体方法为:将活动数据样本数量和阈值进行比较,如果活动数据样本数大于等于阈值,则表明该微簇是有效的;如果活动数据样本数小于阈值,并且将其丢弃。
27、进一步的,计算局部离群因子具体步骤如下:
28、计算每个微簇的第r距离邻域内各微簇的可达距离:
29、reachdistr(x,x')=max{distr(x'),distr(x,x')}
30、distr(x')为领域微簇x'的第r距离,distr(x,x')为领域微簇x'到点x的距离,max{}表示最大值函数;
31、分别计算点x、领域微簇x'的局部第r距离邻域内局部可达密度:
32、
33、
34、ndhr(x)表示点x的第r距离邻域内微簇,包含距离小于等于distr(x)的所有人类活动实例;
35、计算每个点的第r距离邻域内局部离群因子:
36、
37、其中,lof_score表示有效微簇的计算局部离群因子。
38、进一步的,s3更新模型的具体步骤如下:
39、s301、输入当前模型m,最新人类活动数据;
40、s302、判断是否有新簇产生,当有新簇产生时,则进行s304,否则进行s303;
41、s303、把新簇和现有类的扩展加入到现有模型中,计算微簇的簇特征ls、ss、n、π、t;
42、s304、输出更新后的模型m1。
43、进一步的,模型以在线的方式更新。
44、进一步的,所述基于半监督的人类活动数据流检测应用于帕金森综合征的辅助诊断。
45、本发明与现有技术相比具有以下优点:
46、本发明的方法使用基于微簇的数据表示技术来汇总数据。所有传入的流数据都被汇总并表示为一组在线微簇,保留了原始实例的内在数据结构和本地类分布。本发明模型通过一个错误驱动的方法自动学习这些微簇的可靠性或重要性,并动态地选择短期或长期的代表性微簇来捕获不断发展的概念;能够更快地适应局部概念演化。本发明算法动态维护一个固定大小的微簇集,支持有限的内存约束,本发明模型不涉及优化目标函数的过程,且以在线的方式工作;由于有效的在线微簇维护和快速的概念漂移适应,本发明算法即使在少量标记数据的情况下也支持高分类性能。此外,本发明没有将数据集划分数据块,因此避免了现有技术分类性能取决于块大小的问题;同时本发明在标记数据稀疏的情况下,分类性能和效率较高。
- 还没有人留言评论。精彩留言会获得点赞!