一种基于知识生成的视觉问答方法、装置及存储介质
本发明涉及视觉问答领域,尤其涉及一种基于知识生成的视觉问答方法、装置及存储介质。
背景技术:
1、当前基于知识的视觉问答研究通常将问题文本和图像的物体标签作为检索关键词,在知识库中(如conceptnet 和 wikipedia)进行知识检索,并且将检索到的知识用于答案推理。由于现有的静态知识库通常是人工标注的,无法覆盖多样的关系类型,这也导致实体间关系类型比较局限。由于人工标注的静态知识库所构建的知识体系覆盖面较少,且其关系类型也较为局限,因此难以在开放场景下应用于知识视觉问答任务。
技术实现思路
1、为至少一定程度上解决现有技术中存在的技术问题之一,本发明的目的在于提供一种基于知识生成的视觉问答方法、装置及存储介质。
2、本发明所采用的技术方案是:
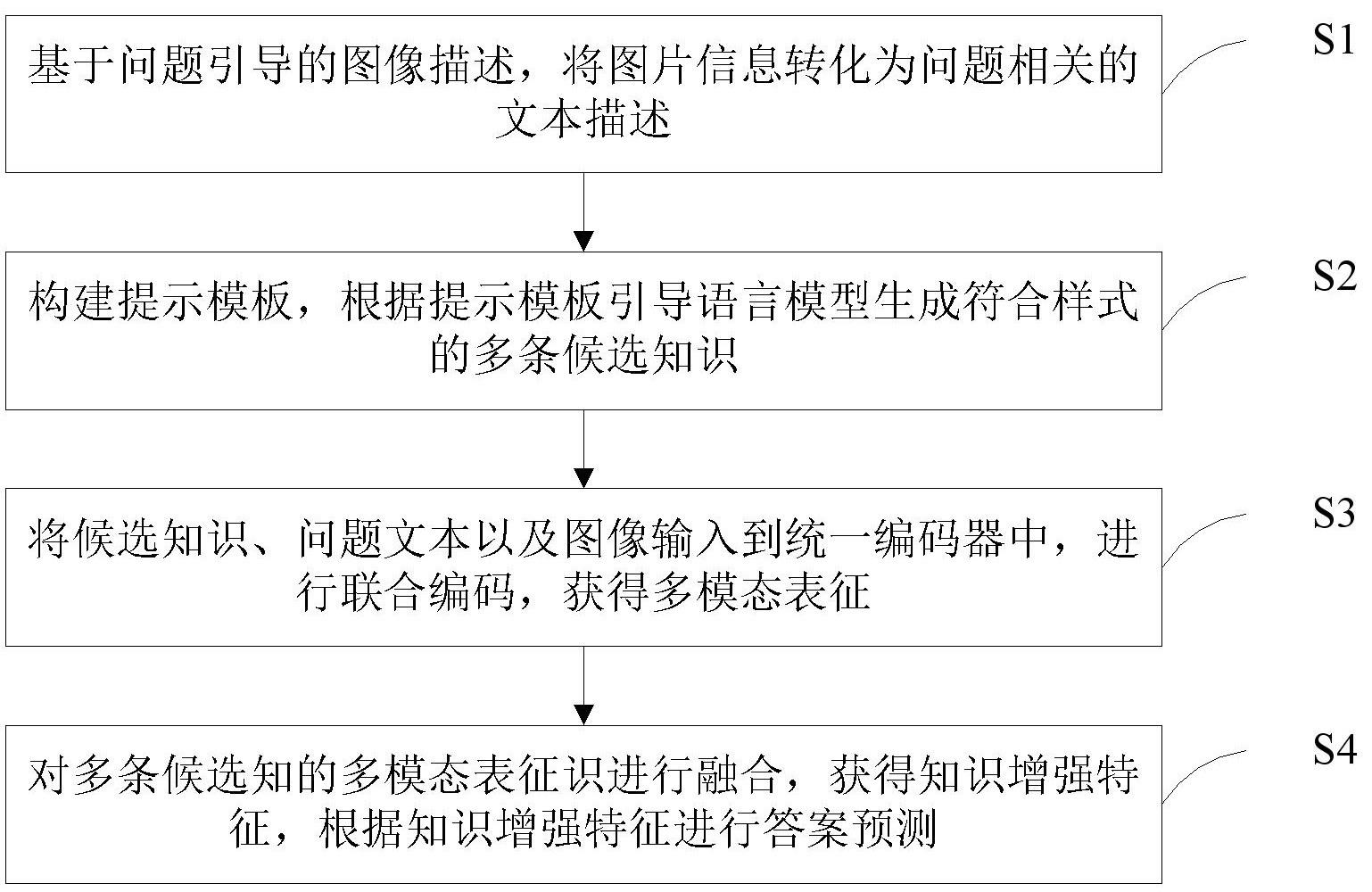
3、一种基于知识生成的视觉问答方法,包括以下步骤:
4、基于问题引导的图像描述,将图片信息转化为问题相关的文本描述;
5、构建提示模板,根据提示模板引导语言模型生成符合样式的多条候选知识;
6、将所述候选知识、问题文本以及图像输入到统一编码器中,进行联合编码,获得知识感知的多模态表征;
7、对多条候选知的多模态表征识进行融合,获得知识增强特征,根据知识增强特征进行答案预测。
8、进一步地,所述基于问题引导的图像描述,将图片信息转化为问题相关的文本描述,包括:
9、计算场景图区域与问题文本的相关性,根据所述相关性提取top-k个图像区域,输入到预设的图像描述生成模型,将场景图转化为文本描述,以便语言模型理解视觉内容。
10、进一步地,所述场景图区域与问题文本的相关性通过以下方式计算获得:
11、记场景图区域为视觉对象,计算问题文本与视觉对象的相似度分数:
12、(1)
13、(2)
14、其中,和是视觉问答模型的可学习参数,是问题文本特征,表示转置,是问题句子长度,是场景图特征,是视觉对象个数;是问题文本和视觉对象的相似度矩阵,表示问题文本中第个单词与第个视觉对象之间的相似度分数;
15、根据公式(2),得到第个视觉对象的在问题引导下的注意力得分,对注意力得分进行归一化处理,得到每个视觉对象和问题文本的相关性,计算方式如下:
16、
17、其中,是温度系数,是超参数,是第个视觉对象和问题文本的相关性。
18、进一步地,所述构建提示模板,根据提示模板引导语言模型生成符合样式的多条候选知识,包括:
19、构建提示模板;所述提示模板由任务指令和情境示例组成,每个情境示例由该情境示例对应的图像描述和问题文本以及标注的知识组成;
20、当为新问题生成知识时,向语言模型输入所述提示模板,并拼接上新问题及该新问题对应的图像描述,同时输入一个占位符,引导语言模型从占位符后生成符合样式的文本;
21、根据生成的文本获取多条候选知识。
22、进一步地,所述语言模型为gpt-3等超大规模预训练语言模型。
23、进一步地,所述提示模板包括任务提示头和个情境示例(),表达式如下:
24、
25、设新问题为,假设生成的文本y由多个时间步的输入组成,即,因此,解码时间步的输出可表示为:
26、
27、其中,表示语言模型。
28、进一步地,所述统一编码器为多层transformer编码器;
29、所述将所述候选知识、问题文本以及图像输入到统一编码器中,进行联合编码,获得知识感知的多模态表征,包括:
30、将候选知识和问题文本进行拼接,获得文本序列:
31、
32、其中,表示拼接操作,指示序列的开始,表示分割符号,表示问题文本,表示为生成的知识语句;
33、将文本序列输入统一编码器的词嵌入层,得到对应的文本特征;
34、根据图像获取图像特征,图像特征经过线性变换后投影到与文本特征相同的特征空间中,获得视觉特征;
35、将文本特征和视觉特征拼接,得到输入特征;
36、引入位置嵌入和模态嵌入,将输入特征位置嵌入和模态嵌入进行相加,得到词嵌入层输出特征;
37、多层transformer编码器对词嵌入层输出特征处理,获得;表示第层transformer的输出特征;
38、采取[cls]位置的特征作为问题-知识-图像的全局联合表征,获得最终的多模态表征:
39、
40、其中,为可学习参数,表示第层中[cls]位置对应的特征;
41、对于条候选知识,分别将条候选知识和问题文本进行拼接,再与图像一起编码,得到个知识增强的多模态特征。
42、进一步地,所述对多条候选知的多模态表征识进行融合,获得知识增强特征,包括:
43、将每个多模态特征和图像的视觉知识特征进行拼接,并输入知识推理模块中,输出,具体表达式如下:
44、
45、
46、
47、
48、根据知识推理模块的输出,通过求平均的操作获得全局的知识增强特征:
49、
50、其中,是第层的输出,表示拼接操作,表示多头注意力机制层,表示层标准化,表示前馈子层,表示求平均。
51、进一步地,所述根据知识增强特征进行答案预测,包括:
52、以全局的知识增强特征作为输入,构建多层感知器分类器来预测答案,具体表达式如下:
53、
54、
55、其中,是答案集合上的计算得分;q是输入的问题,是输入的图像,是生成的候选知识,是预测答案。
56、进一步地,所述知识推理模块和多层感知器分类器组成推理模型;
57、采用以下方式对推理模型进行训练:
58、将问题、场景图与生成的候选知识记为正样本,即;随机抽取非该问题和场景图生成的知识作为负样本,即;
59、将正负样本分别输入到知识推理模块中进行答案预测的过程中,采用的损失函数如下:
60、
61、采用负对数似然损失来学习多层感知器分类器:
62、
63、最终推理模型学习的损失函数为:
64、
65、其中,是标注的正确答案,是整个数据集,是数据集的期望,是损失函数的权重系数。
66、本发明所采用的另一技术方案是:
67、一种基于知识生成的视觉问答装置,包括:
68、至少一个处理器;
69、至少一个存储器,用于存储至少一个程序;
70、当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如上所述方法。
71、本发明所采用的另一技术方案是:
72、一种计算机可读存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行如上所述方法。
73、本发明的有益效果是:本发明通过知识生成,只需少量的学习样本即可将预训练模型的积累的知识迁移到新的下游任务中,可广泛应用于开放场景下的知识视觉问答。
- 还没有人留言评论。精彩留言会获得点赞!