一种基于模型解耦的联邦学习数据隐私保护方法及系统与流程
本发明涉及分布式机器学习领域,尤其涉及一种联邦学习数据隐私保护方法及系统。
背景技术:
1、由于隐私保护、计算资源等方面的原因造成的数据孤岛,正在阻碍着训练人工智能模型所必须的大数据使用,而分布式机器学习技术,例如联邦学习,成为一种解决数据孤岛的方法。联邦学习通过多个客户端共同训练机器学习模型,在数据不发送给他人的情况下,通过交换模型来协同训练机器学习模型,从而保护数据隐私,已在医学学习、自然语言处理和欺诈信用卡检测等广泛应用。
2、联邦学习涉及多个参与方,在此架构下,公平性被赋予了丰富的内涵:一方面,联邦学习中不同参与者参与训练所耗费资源存在差异,对模型训练的贡献可能会有很大不同,能够公平反映每个参与者贡献的奖惩激励机制是联邦学习生态可持续发展的关键;另一方面,无论发送给各个参与方的全局模型是被直接用于结果预测还是用于优化参与方的个性化模型,各个参与方所使用的模型在最终的预测性能或精准度上应该具有公平性。因此,准确计算各个参与方的贡献值是实现公平性的关键。
技术实现思路
1、为了解决上述技术问题,本发明的目的是提供一种基于模型解耦的联邦学习数据隐私保护方法及系统,通过在联邦学习中引入模型解耦和公平性激励,降低计算开销,提高模型性能,实现满足本地客户端期望的公平性。
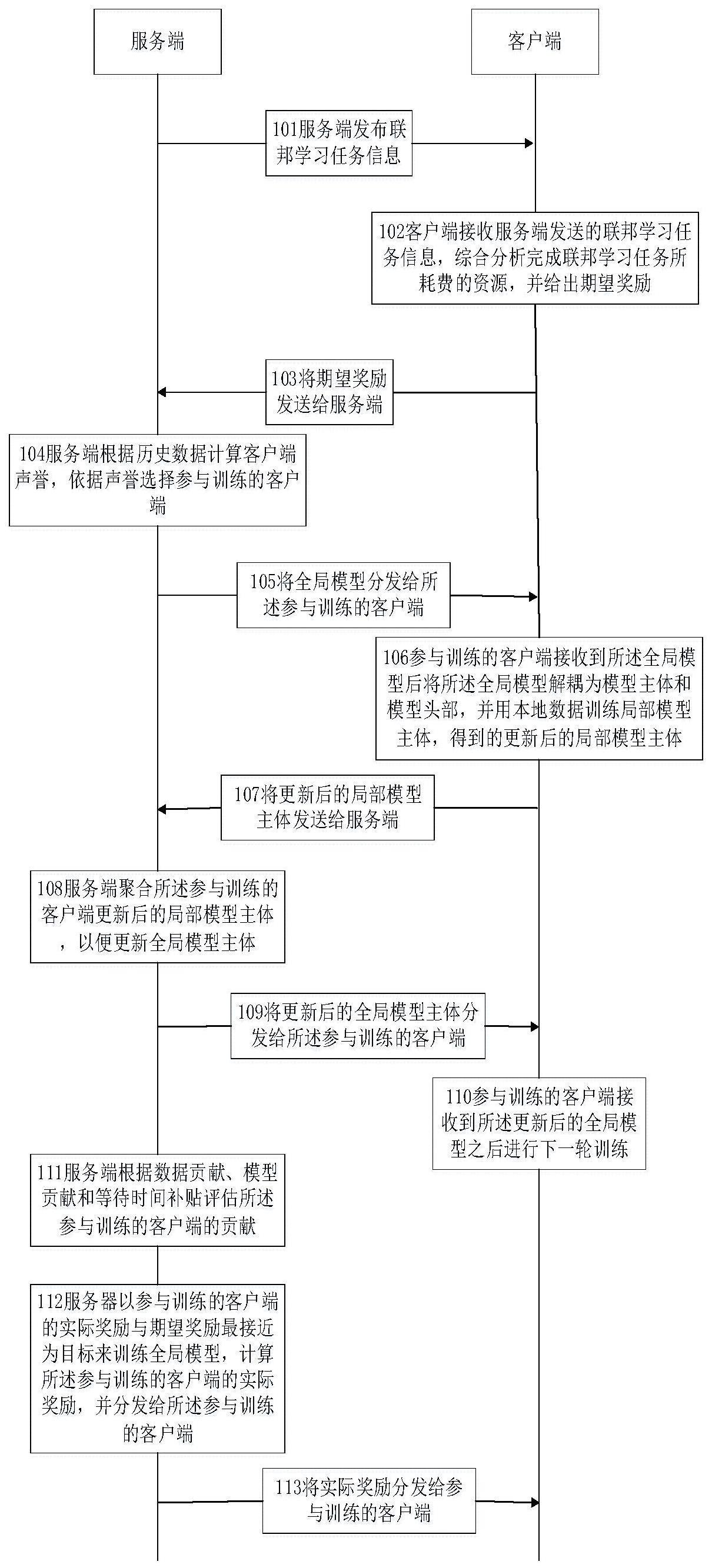
2、本发明所采用的第一技术方案是:一种基于模型解耦的联邦学习数据隐私保护方法,包括以下步骤:
3、服务端发布联邦学习任务;
4、所述服务端根据历史数据计算客户端声誉,依据声誉选择参与训练的客户端,并将全局模型分发给所述参与训练的客户端;
5、所述服务端聚合所述参与训练的客户端更新后的局部模型主体,来更新全局模型主体,并将更新后的全局模型主体分发给所述参与训练的客户端;
6、所述服务端根据数据贡献、模型贡献和等待时间补贴评估所述参与训练的客户端的贡献;
7、所述服务端以参与训练的客户端的实际奖励与期望奖励最接近为目标来训练全局模型,计算所述参与训练的客户端的实际奖励,并分发给所述参与训练的客户端。
8、进一步,所述服务端根据历史数据计算客户端声誉,依据声誉选择参与训练的客户端,并将全局模型分发给所述参与训练的客户端一步骤,其具体包括:
9、所述服务端根据客户端的历史联邦学习任务评估每次任务的期望奖励和实际奖励之间的匹配程度;
10、所述服务端根据所述匹配程度计算客户端声誉;
11、所述服务端选择所述客户端声誉高的客户端作为所述参与训练的客户端,并将所述全局模型分发给所述参与训练的客户端。
12、进一步,所述服务端根据所述匹配程度计算客户端声誉的计算公式具体表示为:
13、
14、其中,和分别表示客户端ck在第r次任务中的实际奖励和期望奖励,表示第r次任务的遗忘因子,vk表示客户端ck的声誉。
15、进一步,所述服务端聚合所述参与训练的客户端更新后的局部模型主体,来更新全局模型主体,并将更新后的全局模型主体分发给所述参与训练的客户端这一步骤,具体包括:
16、所述服务端接收来自所述参与训练的客户端上传的更新后的局部模型主体;
17、所述服务端基于fedavg方式将所述更新后的局部模型主体统一聚合,生成更新后的全局模型主体;
18、所述服务端将所述更新后的全局模型主体分发给所述参与训练的客户端。
19、进一步,所述数据贡献、模型贡献和等待时间补贴的计算公式具体为:
20、所述数据贡献的表达式
21、
22、其中,ud,k表示客户端ck的数据贡献,dk表示客户端ck的本地数据集,d表示所有客户端的数据集;
23、所述模型贡献由局部模型主体与聚合后全局模型主体的相似度和参与训练的客户端的局部模型主体的夏普利值构成;
24、所述相似度的表达式
25、
26、其中,表示客户端ck在第t轮训练中的局部模型主体与聚合后全局模型主体的相似度,表示局部模型主体,表示全局模型主体;
27、所述参与训练的客户端的局部模型主体的夏普利值的表达式
28、
29、其中,表示客户端ck在第t轮训练中的夏普利值,表示参与任务的客户端集合去掉客户端ck后的真子集,v(·)表示括号内客户端集合组成的联盟进行模型聚合得到的全局模型在验证集上的准确率得分;
30、所述模型贡献的表达式为
31、
32、其中,表示客户端ck在第t轮训练中的模型贡献,τ表示超参数;
33、所述等待时间补贴的表达式为
34、
35、其中,表示客户端ck在第t轮训练中的等待时间补贴,δtk表示客户端收到新一轮的全局模型的时间与服务器成功收到局部模型主体的时间之差,t*表示等待时间阈值。
36、本发明所采用的第二技术方案:一种基于模型解耦的联邦学习数据隐私保护方法,包括:
37、客户端接收服务端发送的联邦学习任务信息,综合分析完成联邦学习任务所耗费的资源,并给出期望奖励;
38、所述参与训练的客户端将接收到的全局模型解耦为模型主体和模型头部,并用本地数据训练局部模型主体,将得到的更新后的局部模型主体上传给服务端;
39、所述参与训练的客户端接收更新后的全局模型主体进行下一轮训练。
40、进一步,所述参与训练的客户端将接收到的全局模型解耦为模型主体和模型头部,并用本地数据训练局部模型主体,将得到的更新后的局部模型主体上传给服务端这一步骤,具体包括:
41、所述参与训练的客户端接收服务端分发的全局模型;
42、所述参与训练的客户端将全局模型解耦为模型主体和模型头部,并将所述模型主体作为客户端的局部模型主体;
43、所述参与训练的客户端将本地数据输入至所述局部模型主体中进行训练;
44、基于损失函数和预设的学习率对局部模型主体进行反向传播,得到更新后的局部模型主体。
45、本发明所采用的第三技术方案是:一种基于模型解耦的联邦学习数据隐私保护系统,所述系统包括服务端和客户端,其中,
46、所述服务端,用于:
47、发布联邦学习任务;
48、根据历史数据计算客户端声誉,依据声誉选择参与训练的客户端,并将全局模型分发给所述参与训练的客户端;
49、聚合所述参与训练的客户端更新后的局部模型主体,来更新全局模型主体,并将更新后的全局模型主体分发给所述参与训练的客户端;
50、根据数据贡献、模型贡献和等待时间补贴评估所述参与训练的客户端的贡献;
51、以参与训练的客户端的实际奖励与期望奖励最接近为目标来训练全局模型,计算所述参与训练的客户端的实际奖励,并分发给所述参与训练的客户端;
52、所述客户端,用于:
53、接收服务端发送的联邦学习任务信息,综合分析完成联邦学习任务所耗费的资源,并给出期望奖励;
54、所述参与训练的客户端接收到所述全局模型后将所述全局模型解耦为模型主体和模型头部,并用本地数据训练局部模型主体,将得到的更新后的局部模型主体上传给服务端;
55、所述参与训练的客户端接收到所述更新后的全局模型主体之后进行下一轮训练。
56、本发明提供的一种基于模型解耦的联邦学习数据隐私保护方法及系统的有益效果是:本发明通过在联邦学习中引入模型解耦和公平性激励,降低了计算开销,并提高了模型性能,实现满足本地客户端期望的公平性。
- 还没有人留言评论。精彩留言会获得点赞!