一种基于频域增强的压缩视频人体行为识别方法
本发明涉及视频分析,尤其涉及一种基于频域增强的压缩视频人体行为识别方法。
背景技术:
1、人体行为识别是智能视频分析领域的研究热点,是智能视频分析与理解、视频监控、人机交互等诸多领域的理论基础,近年来得到了学术界及工程界的广泛重视,人体行为识别在视频检索、自动驾驶和智能监控等方面有广泛的应用前景。而基于压缩域数据和频域数据的人体行为识别方法,由于其高效性,以及压缩域数据、频域数据与rgb数据含有的不同语义和运动线索,近年也受到了大量关注。
2、而对于实际应用,需要考虑实时性和准确性的问题,现有的方法仍存在许多问题和挑战。在基于rgb数据的人体行为识别方法中,基于卷积神经网络(convolutionalneural network,cnn)的方法取得了较好的识别效果,但仍存在计算量大、缺乏对全局信息的建模等问题;而视觉transformer的方法能够捕获长距离的特征依赖关系,提升了人体行为识别任务的识别效果,但仍存在计算量大、需要大量训练数据和缺乏对局部信息的建模等问题。另一方面,基于压缩域数据的人体行为识别方法近年来也受到大量关注。基于压缩域数据的人体行为识别利用视频的压缩域数据而不是rgb数据进行人体行为识别。压缩域数据只保留少数完整帧,即i帧(i frame,i),其他帧基于偏移进行重建,称为运动矢量(motion vector,mv)和残差(residual,r)。基于压缩域数据的人体行为识别方法达到了较高的识别速度,但解码过程仍需花费较长时间,且仍存在空间信息冗余的问题。此外,基于频域数据进行视觉任务的处理的方法也受到了广泛关注,其将频域数据,即离散余弦变换(discrete cosine transform,dct)系数作为原始图像或压缩视频格式的替代,提供了数据的频域形式,但大部分方法需要完整解压图像或视频,然后再通过dct变换计算获得其dct系数,因此速度并没有显著提升。并且,目前基于频域数据的方法忽略了频域不同通道的显著性不同的特点,造成低频包含的显著纹理和边缘信息的丢失,导致目前基于频域数据的方法的识别准确率相较于基于rgb视频帧的方法仍有一定差距。
3、目前,现有技术的视频人体行为识别方法存在信息冗余问题和识别效率较低的问题。由于视频的相邻帧之间的相似性较高,视频中含有大量的冗余信息。而视频的压缩域数据只保留少数完整帧(i帧),其他帧(p帧,包括残差r和运动矢量mv)基于偏移进行重建,能够一定程度降低视频的信息冗余。另一方面,传统的基于rgb数据的人体行为识别方法需要对视频进行完全解码以获得rgb视频帧,而基于压缩域的方法也需要对i帧和残差r进行完全解码获得rgb数据,解码过程所需的预处理时间较长,降低了人体行为识别的效率;且需要对解码得到的rgb帧进行空间下采样,造成了空间显著信息的丢失。
4、现有技术的基于频域的人体行为识别方法存在低频显著时空纹理和边缘信息丢失的问题。与rgb数据的通道不同,频域数据的通道显著性分布具有一定的特点,即主要时空信息集中在dc和低频通道,而高频通道包含一部分冗余信息和噪声等。现有的频域学习方法直接采用卷积操作对频域数据的所有通道进行相同处理,忽略了不同频域通道所包含信息量不同的特点,导致了低频的显著时空纹理和边缘线索的丢失,造成频域中行为相关的物体和背景信息不能被有效获取,使得基于频域数据的人体行为识别方法的准确率与基于rgb数据及压缩域数据的方法相比有一定的差距。
5、现有技术中的第一种压缩视频人体行为识别(coviar)方法包括:利用压缩视频的i帧、运动矢量mv、残差r进行人体行为识别。具体处理步骤包括:
6、1)视频解码。通过对压缩视频进行解码,得到压缩域i帧和p帧(残差r、运动矢量
7、mv)数据。
8、2)数据处理。为了打破连续p帧之间的依赖性,使得每个p帧只依赖于参考i帧,而不依赖于其他p帧,累计运动矢量和残差到参考i帧。
9、3)输入网络。将i帧、残差r、运动矢量mv分别输入到resnet-152、resnet-18、
10、resnet-18网络中,输入帧数均为3帧,最后对输出的预测分数取平均,得到最终的预测结果。
11、上述现有技术中的第一种压缩视频人体行为识别(coviar)方法的缺点包括:
12、1)采用resnet-152作为i帧的骨干网络,计算复杂度较高,导致识别速度下降。
13、2)仍然需要将压缩域的i帧和残差r解码为rgb图片数据,解码过程仍需要较多时间,降低了人体行为识别的效率。
14、3)存在空间下采样过程中帧内显著空间信息丢失的问题。
15、现有技术中的第二种从频域进行快速人体行为识别(fast-coviar)的方法包括:利用压缩视频的频域数据进行人体行为识别。具体处理步骤包括:
16、1)通过对压缩视频进行解码,得到i帧和运动矢量mv数据,不使用残差r。
17、2)通过熵解码获得i帧频域dct数据,并选择16或32个主要通道作为输入。
18、3)将i帧和运动矢量mv分别输入到适应于dct输入的resnet50、resnet18中,输入帧数均为3帧,最后对输出的预测分数取平均,得到最终的预测结果。
19、上述现有技术中的第二种从频域进行快速人体行为识别(fast-coviar)的方法的缺点包括:
20、1)频域数据的获取较为复杂,效率提升不明显。
21、2)缺乏对频域数据的时空上下文的提取。
22、3)没有充分利用频域数据的显著性分布特点,导致识别准确率相比基于压缩域的基线方法coviar出现明显下降,识别性能与基于压缩域的方法相比有较大差距。
23、现有技术中的第三种基于频域数据的快速压缩视频人体行为识别方法(faster-fcoviar)包括:利用压缩视频部分解码,直接获得视频的频域数据,进行快速的压缩视频人体行为识别。具体处理步骤包括:
24、1)部分解码。通过对压缩视频进行部分解码,得到i帧和残差r的频域数据以及运动矢量mv,效率较高。
25、2)通道选择。通过实验选择24个信息显著的通道作为输入。
26、3)输入网络。将频域i帧、频域残差r、运动矢量mv分别输入到resnet-50、resnet-
27、50、resnet-18网络中,输入帧数均为3帧,最后对输出的预测分数取平均。
28、4)空间域-频域联合学习。通过知识蒸馏,将空间语义知识从空间教师网络转移到轻量级的频域学生网络。
29、上述现有技术中的第三种基于频域数据的快速压缩视频人体行为识别方法(faster-fcoviar)的缺点包括:
30、1)输入帧数较少,不利于网络捕获长期运动线索。
31、2)缺乏对频域数据的时空上下文的提取。
32、3)对输入网络的频域数据的所有通道进行同等处理,没有充分利用频域数据不同通道的时空显著性不同的特点,造成时空信息的丢失,导致与基于rgb数据的方法仍有准确率的差距。
技术实现思路
1、本发明的实施例提供了一种基于频域增强的压缩视频人体行为识别方法,以实现有效地对压缩视频进行人体行为识别。
2、为了实现上述目的,本发明采取了如下技术方案。
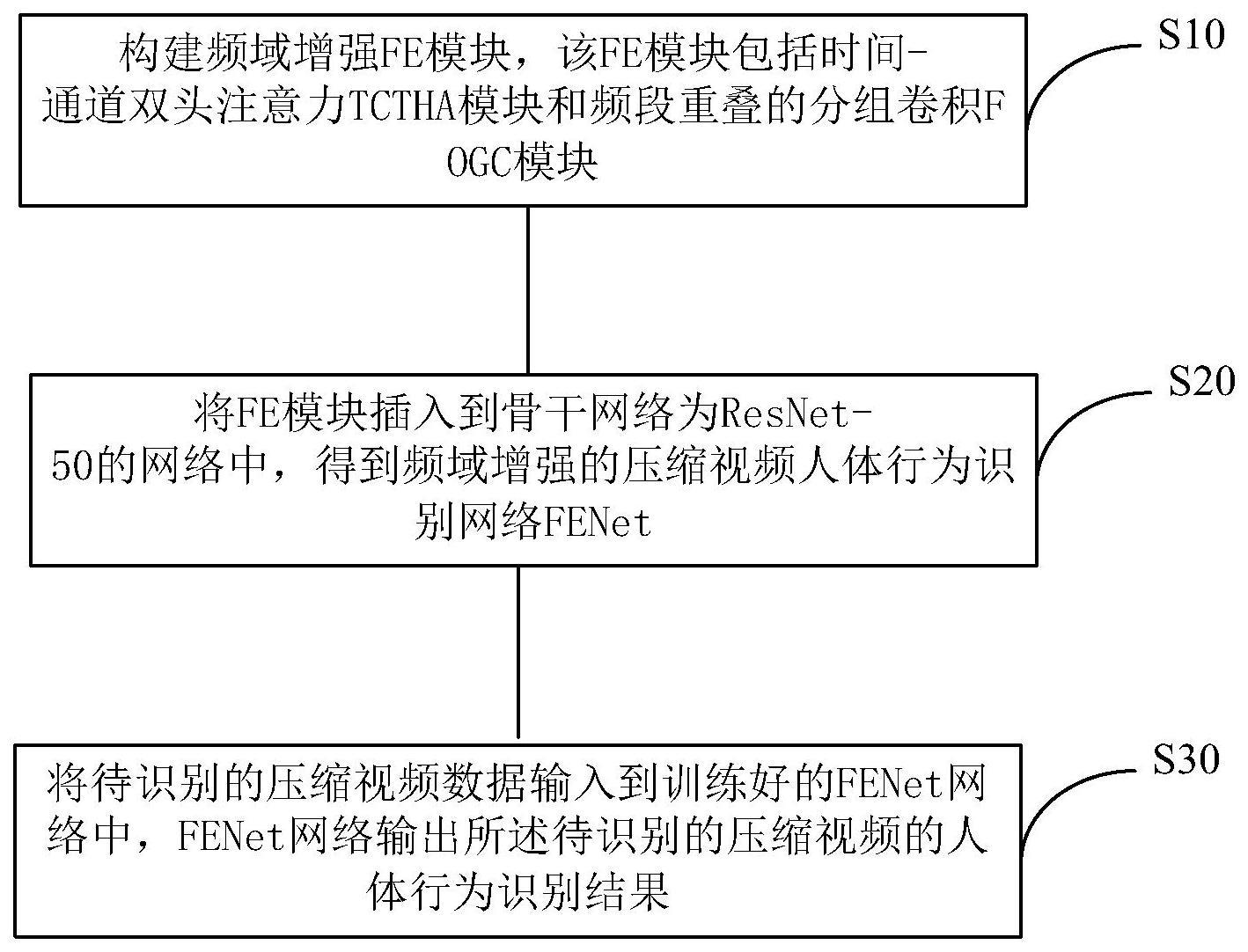
3、一种基于频域增强的压缩视频人体行为识别方法,包括:
4、构建频域增强fe模块,所述fe模块包括时间-通道双头注意力tctha模块和频段重叠的分组卷积fogc模块;
5、将所述fe模块插入到骨干网络为resnet-50的网络中,得到频域增强的压缩视频人体行为识别fenet网络,对所述fenet网络进行训练;
6、将待识别的压缩视频数据输入到训练好的fenet网络中,fenet网络输出所述待识别的压缩视频的人体行为识别结果。
7、优选地,所述的构建频域增强fe模块,所述fe模块包括时间-通道双头注意力tctha模块和频段重叠的分组卷积fogc模块,包括:
8、构建包括tctha模块和fogc模块的fe模块,输入特征首先经过tctha模块,将tctha模块输出的特征输入到fogc模块中;
9、所述tctha模块对输入特征x进行全局平均池化,得到空间池化后的特征,对空间池化后的特征进行通道维度的1d卷积,得到不同通道的注意力权重,使用通道注意力权重对输入特征的通道维度进行加权,得到输出特征;
10、所述fogc模块将输入特征x的通道分成g组,使得每组内只含有相邻频段的通道,组与组之间有部分通道重叠,对每组特征进行一个时间维度的1d卷积和一个空间2d卷积,对不同组的输出特征沿通道维度进行拼接,应用一个1×1的2d卷积将通道维度转换为与输入通道大小一致,得到最终的输出结果。
11、优选地,所述的tctha模块将输入特征分别输入到通道注意力分支和时间注意力分支,在通道注意力分支中,将输入特征x进行全局平均池化,得到空间池化后的特征
12、
13、对特征uchannel进行通道维度的1d卷积,得到不同通道的注意力权重:
14、schannel=σ(conv1d(uchannel)) (2)
15、其中conv1d为卷积核大小为5的1d卷积,σ为sigmoid函数;
16、使用通道注意力权重对输入特征的通道维度进行加权,得到输出特征
17、
18、其中·为通道维度的乘法。
19、在时间注意力分支中,将特征x进行全局平均池化)后,得到空间池化后的特征
20、
21、对特征utemporal进行时间维度的1d卷积,得到不同帧的时间注意力权重,捕获时间上下文信息:
22、stemporal=σ(conv1d(utemporal)) (5)
23、其中conv1d为卷积核大小为5的1d卷积,σ为sigmoid函数。
24、使用时间注意力权重对输入特征的时间维度进行加权,得到输出特征
25、
26、其中·为时间维度的乘法。
27、将通道注意力分支和时间注意力分支的输出特征沿通道维度进行拼接,经过一个1×1的2d卷积将通道维度恢复到输入通道大小,得到最终的输出结果
28、
29、其中conv1×1d为1×1的2d卷积,表示通道注意力分支和时间注意力分支的输出特征沿通道维度进行拼接。
30、优选地,所述的将所述fe模块插入到骨干网络为resnet-50的网络中,得到频域增强的压缩视频人体行为识别fenet网络,对所述fenet网络进行训练,包括:
31、将fe模块插入到骨干网络为resnet-50的网络中,使用tctha模块和fogc模块替换掉所有resnet-50的瓶颈块的3×3的2d卷积,得到频域增强的fenet网络;
32、fenet网络采用resnet-50作为骨干网络,采用频域部分解码方法获得压缩视频的频域i帧数据,采样帧数为8帧,将频域i帧数据输入到fenet网络中;
33、训练fenet网络时,对频域i帧进行随机翻转以进行数据增强,采用权重衰减为0.0001的adam优化器进行训练,训练的批处理batch大小设置为64,采用和kinetics-700数据集进行训练,实验一共训练60轮,初始学习率为0.001,且在第10、24和44轮时衰减为原学习率的1/10,得到训练好的fenet网络。
34、优选地,所述的将待识别的压缩视频数据输入到训练好的fenet网络中,fenet网络输出所述待识别的压缩视频的人体行为识别结果,包括:
35、对于待识别的压缩域视频,采样共8帧的频域i帧,作为训练好的fenet网络的输入数据,输入数据经过fenet网络中的全连接层后,对所有频域i帧的分类分数进行平均,得到所述待识别的压缩域视频的人体行为识别结果。
36、由上述本发明的实施例提供的技术方案可以看出,本发明方法解决了频域学习的低频纹理和边缘线索丢失问题、时空建模不足的问题,与其他基于频域数据的方法相比,达到了更高的识别准确率,与其他基于压缩域数据的方法和基于rgb数据方法相比,也达到了具有竞争力的准确率,同时具有较高的效率。
37、本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!