一种基于强化学习的异步群体决策系统及方法
本发明属于群体决策,尤其涉及一种基于强化学习的异步群体决策系统及方法。
背景技术:
1、决策是生活中经常遇到的一类问题。随着社会环境变得越来越多样,决策问题也变得更加复杂,单靠个人决策很难较好地完成各类型决策任务。此时,群体决策比个人决策更加使用。群体决策是指一个决策者群体根据自身知识和理解评估备选方案,其主要目标是选择最优的备选方案。
2、不幸的是,虽然相比于个体决策,群体决策能完成类型更加多样的决策问题,且其正确率也有一定程度的提升,但在某些方面他仍存在着问题和缺陷,具体表现为:
3、(1)决策群体应该如何选择。现有的研究没有过多去讨论决策群体是如何得到的,大多是基于一个系统或者组织的内部成员,例如公司董事会,某一组织的管理层,某特定决策系统内部成员等。这一决策群体选择方法缺乏从专业角度对决策者进行筛选,以保证决策结果质量更高。
4、(2)群体中决策者的权重定义问题。现有的一些研究通过分析社交网络的拓扑关系,基于群体间成员的信任关系,定义决策者的权重。但在实际任务中,这种信任关系的建立需要知道决策者群体的拓扑结构,这易导致计算量的提升以及占用较大的存储资源。另外,对于不同的任务,基于信任的权重表示方法可能不够准确。且这种方法无法做到决策的公平性和平等性,对最终决策的正确率也有一定程度的影响。
5、(3)针对选择不一致的决策者如何制定合适的调整机制,促进群体共识的达成。现有的研究针对这一问题的解决方案主要分为两类:其一是针对不一致的决策者采取少数服从多数的原则,牺牲了少部分人的选择,照顾了大多数人的倾向。但有时真相存在着少数人手里,因此少数服从多数的原则对于群体决策问题并不是那么适用。其二是通过反馈或者一个可信第三方进行协调,调整决策者的决策结果,但这无疑是耗时耗力的。
技术实现思路
1、针对现有技术存在的问题,本发明提供了一种基于强化学习的异步群体决策系统及方法。
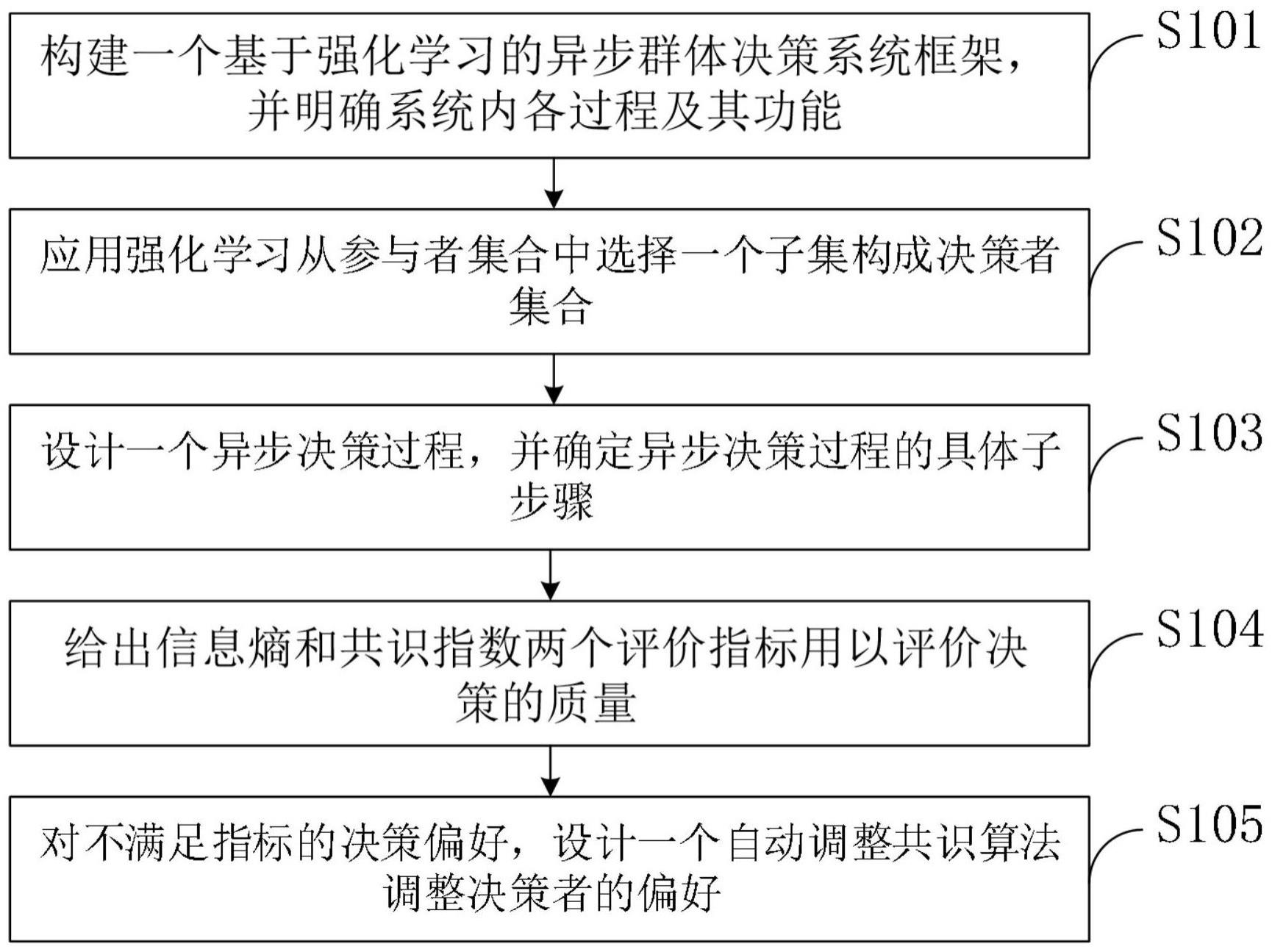
2、本发明是这样实现的,一种基于强化学习的异步群体决策方法包括以下步骤:
3、步骤一、构建一个基于强化学习的异步群体决策系统框架,并明确系统内各过程及其功能;
4、步骤二、应用强化学习从参与者集合中选出一个子集作为决策者集合;
5、步骤三、设计一个异步决策过程,并给出该过程的具体子步骤;
6、步骤四、给出信息熵和共识指数两个评价指标用以评价决策的质量;
7、步骤五、对不满足指标的决策偏好,设计一个自动调整共识算法调整决策者的偏好。
8、进一步,所述步骤一如图(2)所示,该框架一共包括决策者选择,决策以及共识调整三个过程。决策者选择过程应用强化学习为决策过程筛选出一组在历史决策中最优平均性能的决策者集合。决策过程能够将决策结果传回决策者选择过程,更新强化学习中的神经网络。另外,决策后的结果也会被传到共识调整共识,用以进一步调整决策者的偏好。
9、进一步,所述步骤二设计一个决策者选择方法中,令p={p1,p2,…,pm}表示系统内的参与者集合,共包含m名参与者;
10、根据各参与者的历史决策结果,在参与者集合p中选择n名组成决策者集合e,e={e1,e2,…,en},其中n≤m。
11、进一步,运用q-learning在参与者集合中选择一个平均性能最优的群体,组成决策者集合;
12、根据参与者的历史决策结果矩阵hdm×l和历史决策时间矩阵htm×l,对q-learning中的状态、动作、奖励、回报函数和策略五大主要元素做出定义,具体包括如下步骤:
13、步骤1,状态s被定义为一个m维二进制向量。
14、步骤2,动作a被定义为一个m维二进制向量。
15、步骤3,奖励r是由参与者pi的历史决策时间、历史决策正确率、填补知识的空白三要素构成;
16、步骤4,回报函数表示在采取了一系列动作后得到的奖励的总和;
17、步骤5,策略则是采用ε贪心策略。
18、进一步,所述步骤3中,对于pi的历史决策时间,其奖励r1(pi)表示为:
19、
20、leveli,l表示将决策时间分成五个等级,若在第l次决策时,pi未参与决策,则leveli,l=0,因此leveli,l∈[0,1,2,3,4,5]。l表示历史决策次数。
21、对于pi的历史决策正确率,其奖励r2(pi)表示为:
22、
23、如果pi在第l次决策正确,则hi,l=1,否则hi,l=0。
24、对于pi能够填补知识空白的多少,其奖励r3(pi)表示为:
25、
26、用来衡量在已选择群体中,加入pi后能填补历史决策空白的大小;
27、因此对于pi,他的奖励r(pi)表示为:
28、r(pi)=τ1·r1(pi)+τ2·r2(pi)+τ3·r3(pi)
29、τ1,τ2,τ3表示对于各部分奖励的权重。
30、进一步,给出q-learning中五大主要的定义后,通过对历史决策的多轮训练,不断更新q值,更新公式如下:
31、q(sk,ak)′=q(sk,ak)+α[r+γmax q(s′k,a′k)-q(sk,ak)]
32、q(sk,ak)′为q表更新后的值。α是学习率。[r+γmax q(s′k,a′k)-q(sk,ak)]表示估计误差。
33、执行决策任务前,系统会选择q值最大的前n名参与者组成决策者集合。
34、进一步,所述步骤三设计一个异步决策过程中,基于强化学习的异步群体决策系统收到一个决策任务,决策任务表示有一个决策问题,包含五个备选方案,即g={g1,g2,g3,g4,g5},决策者从五个备选方案中进行选择并向系统提交自己的决策偏好。
35、进一步,所述步骤三中的异步决策过程包括探索、融合和反馈三个阶段,具体如下:
36、(1)在探索阶段,决策者ei接收到决策信息g,将结合自身对决策内容的初始信息和反馈回的群体信息做出决策;
37、探索阶段可分为信息更新和决策确认两方面:
38、在信息更新中,我们用δi,t量化决策者ei在t时刻掌握信息的多少:
39、
40、其中,δini表示决策者ei拥有的初始信息,表示在t时刻系统反馈的群体信息。当在t时刻δi,t≥θ,决策者ei将会进行决策确认,做出决策,其中θ表示决策者将做出决策的阈值;
41、在决策确认中,决策者ei关于备选方案gj的决策偏好可以表示为:
42、
43、
44、ωi用来衡量决策者ei保持自身选择的意愿的强弱,表示决策者ei关于gj的自身决策偏好,表示在t时刻系统反馈回的关于gj的群体偏好;
45、(2)在融合阶段,系统聚合已决策者上传的偏好,得到群体偏好:
46、
47、nt表示t时刻已决策的决策者人数;
48、(3)在反馈阶段,系统若一段时间未收到决策者提交的决策偏好,则它将当前时刻的群体偏好以及已决策人数nt反馈给未决策者。
49、进一步,所述步骤四给出信息熵和共识指数两个评价指标用以评价决策的质量中,包含说明决策者偏好的集中程度的信息熵指标hi和h以及说明决策者偏好与群体偏好差异程度的共识指数指标cii和cg,具体步骤如下:
50、步骤1、量化决策者偏好的集中程度:
51、
52、步骤2、量化群体偏好的集中程度:
53、
54、表示决策过程完成后,关于备选方案gj的群体决策偏好。
55、步骤3、量化决策者偏好与群体偏好的差异程度:
56、
57、其中表示经过排序后的群体决策偏好,表示与群体决策排序相对应的决策者偏好。ξj为权重,
58、步骤4、量化群体的平均差异程度:
59、
60、进一步,所述步骤五对不满足指标的决策偏好,设计一个自动调整共识算法调整决策者的偏好中,系统将对于决策者ei的信息熵hi高于信息熵阈值η1或者共识指数cii低于共识指数阈值ζ的决策者的偏好进行修改,具体包括以下两个步骤:
61、步骤(1),对于信息熵hi>η1且共识指数cii≥ζ的决策者的偏好进行修改;
62、步骤(2),对于共识指数cii<ζ的决策者的偏好进行修改。
63、进一步,所述步骤(1)中,定义信息熵hi>η1且共识指数cii≥ζ的决策者群体为rd1,rd1={ei|ei∈e∩hi>η1∩cii≥ζ},对这一类决策者群体,将排序较后的决策者偏好分给排序较前的偏好;
64、进一步,所述步骤(2)中,定义共识指数cii<ζ的决策者群体为rd2,rd2={ei|ei∈e∩cii<ζ},对这一类决策者群体,粒子群优化算法被用来修改决策者的偏好,将每一位决策者关于各备选方案的偏好定义为粒子的位置,将群体偏好定义为粒子需要朝着运动的目标,因此,整个偏好调整过程被视为粒子向着目标不断移动的过程。
65、本发明的另一目的在于提供一种基于强化学习的异步群体决策系统,所述基于强化学习的异步群体决策系统包括:
66、决策者筛选模块,用于基于决策者的历史决策结果和历史决策时间,通过q-learning从参与者集合中选出一个最优平均性能的决策者集合,参与后续决策任务;
67、决策模块,用于通过一个异步的决策促使已决策者为未决策者提供信息,加快决策速度,帮助未决策者决策;
68、共识调整模块,用于通过加权聚合以及粒子群优化算法,为不满足决策指标的决策者调整其偏好,促进共识达成。
69、结合上述的技术方案和解决的技术问题,本发明所要保护的技术方案所具备的优点及积极效果为:
70、第一、本发明设计了一个基于强化学习的决策者筛选过程。该过程根据决策者的历史决策结果矩阵hdm×l和历史决策时间矩阵htm×l,运用q-learning训练q表,并基于训练好的q表,选择q值最大的n名决策者,最终得到一个平均决策时间短,平均决策准确率高且对于不同类型的决策任务都有一定成功决策人数的具有最优平均性能的决策者集合。另外,在新一轮决策完成后,决策者的决策结果以及决策时间将加入历史决策结果矩阵以及历史决策时间矩阵中,用以持续更新训练q表。
71、本发明将群体决策与群体智能思想相结合,提出了一个异步群体决策方法。在异步群体决策中,决策者结合自己已有信息以及系统反馈回的社会信息独立探索本次决策任务的最优方案,当达到促发决策的阈值θ后,决策者做出决策,并将决策偏好结果上传到系统。系统融合已决策者提交的决策偏好,得到群体决策偏好。之后,系统将融合的决策偏好反馈回未决策者,以帮助未决策者决策。因此在异步群体决策过程中,通过探索、融合、反馈(exploration-integration-feedback,eif)三个步骤,使已决策者为未决策者提供信息,提升未决策者的决策速度以及群体的决策准确率。
72、本发明提供了一种自动共识调整算法:对于与群体决策相似度较高的决策者的决策偏好,运用加权聚合的方法,集中决策者的偏好;对于与群体决策相似度较低的决策者的决策偏好,运用粒子群优化的方法,微调决策者的偏好,促进群体决策偏好更加集中,准确率更高。
73、本发明在群体决策的背景下进行实验,从决策准确度以及决策结果集中度等评价指标对比本发明提出的决策系统与其他决策系统。实验结果表明,本发明提出的群体决策系统在理想环境下能达到更高的决策效果。
74、第二,本发明给出了一种基于强化学习的异步群体决策系统和方法:
75、(1)该系统首先应用强化学习q-learning从参与者中筛选决策者,得到一个具有最优平均性能的决策者群体。
76、(2)该系统结合了群体智能的思想,通过一个包含探索、融合、反馈三个子步骤的异步决策过程,决策者群体内能够存在交流,使得已决策者能够帮助未决策者决策,加快决策速度,提升决策准确率。
77、(3)决策完成后,针对与群体结果不太一致的决策者,一个自动调整共识方法被用来调整他们的偏好。通过加权聚合以及粒子群优化算法,决策者的决策偏好得到调整,群体的共识程度得到提升。
78、第三,作为本发明的权利要求的创造性辅助证据,还体现在以下几个重要方面:
79、(1)本发明的技术方案填补了国内外业内技术空白:
80、现有的研究中关于群体决策中决策群体如何得到这一问题没有过多阐述,通常是直接将参与某一项目的人员,或者是系统内已注册人群被定为决策者,这缺少对决策者的筛选。本发明中,我们提出了一个决策者筛选过程,即根据决策者的历史决策结果,通过强化学习q-learning,筛选出一组具有最优平均性能的决策者参与决策,这能够提高决策的准确率。
81、(2)本发明的技术方案是否解决了人们一直渴望解决、但始终未能获得成功的技术难题:
82、群体决策是指为充分发挥集体的智慧,由多人参与决策分析并制定决策的过程。国内外关于群体决策方面的研究中,决策者的权重制定以及如何调整决策者的偏好以促进最终的共识是两大研究热点。
83、在决策者权重制定方面,目前的研究有通过社交网络分析,根据决策者间的信任关系,或者基于群体间的拓扑关系计算得到决策者的权重。但这些方法存在着计算复杂,计算量大,且基于信任的权重计算方式容易存在着一部分人权重过大,容易导致正确率低。本发明设计的异步决策过程结合了群体智能的思想,不去强调每位决策者的权重,通过探索、融合、反馈三个子步骤,让先决策者成为专家,为非决策者提供帮助。
84、在如何调整决策者的偏好以促进最终的共识方面,现有的研究则是通过一个可信第三方,不断协调每位决策者的偏好,最终达成共识。但基于协调的共识调整方法需要数个轮次的决策者间的协商,这无疑是耗时的,本文设计的自动调整共识算法考虑到了决策者的差异性,将有待调整的决策者分为两类,并通过加权聚合和粒子群优化方法,在提高群体共识的同时大大减少了调整时间。
- 还没有人留言评论。精彩留言会获得点赞!