本发明涉及故障发现及修复领域,尤其涉及一种格兰杰因果关系发现方法、设备及存储设备。
背景技术:
1、格兰杰因果关系是一种广泛采用的统计学概念,用于检查一个时间序列是否可用于预测另一个。在时间序列数据中发现事件类型之间的格兰杰因果关系具有重要的意义,在多个领域都有应用。例如在通信网络中,一个故障事件可能在特定的时间范围内引发另一个故障事件,故障的影响可以通过网络中连接的设备传播。发现各种故障事件之间的格兰杰因果关系,这可以用于识别故障的根本原因,促进快速修复故障。如何针对时间序列数据,发现各个变量之间的格兰杰因果关系成为当下的一个研究热点问题。
2、格兰杰因果发现是一种用于识别两个变量之间是否具有因果关系的方法。现有的方法主要以统计学方法为主,通过对变量间的依赖关系进行独立性测试从而判断一个变量是否对另外一个变量的影响是否显著。同时也有一些基于时序点过程的方法通过强度函数恢复变量间的格兰杰因果关系。但是现有的方法往往忽略先验信息对格兰杰因果关系发现的重要性,先验信息一方面能够加速格兰杰因果发现的速度,另一方面先验信息能够指导现有算法发现更准确的格兰杰因果关系。
技术实现思路
1、目前时序数据中格兰杰因果关系算法中的忽略了因果结构先验信息,导致格兰杰因果关系算法复杂性增加,效率不高,识别的因果效应精度较低,成本较高,针对这些问题,本发明提供了一种格兰杰因果关系发现方法、设备及存储设备,可以提高故障识别准确度和识别速度,降低了成本。
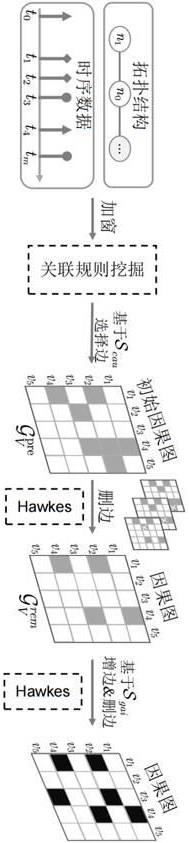
2、一种格兰杰因果关系发现方法,主要包括:
3、s1:根据移动基站的时序数据采用关联规则挖掘算法计算支持度(support)、置信度(confidence)和提升度(lift);
4、s2:根据support、confidence和lift计算具备先验信息的指标:因果强度值和增益分数值;
5、s3:根据因果强度值,构造初始因果图;
6、s4:采用hawkes点过程对步骤s3生成的初始因果图进行删边操作,得到因果图;
7、s5:根据增益分数值,采用hawkes点过程对步骤s4生成的因果图进行增边或删边操作,得到最终因果图。
8、进一步地,步骤s1中的实现过程为:
9、s1.1:对时序数据进行预处理,即设定滑动窗口大小为k1,将时序数据分成若干个窗口,每个窗口中包含k个时刻的数据;
10、s1.2:针对每个窗口中的子序列,构造“basketdataset”,即将每个子序列看作一个“basket”,并将所有“basket”组成一个“basketdataset”;
11、s1.3:根据构造出的“basket dataset”,计算每个关联规则的support、confidence和lift。
12、进一步地,步骤s2中的实现过程为:
13、s2.1:定义能够反应事件和事件之间潜在因果关系指标,具体计算公式为
14、
15、其中,表示事件到事件的提升度,表示事件到事件的置信度,表示随机噪声;
16、s2.2:定义能够反应事件和事件之间因果关系对似然函数的潜在增益指标,具体计算公式为
17、
18、其中,表示事件到事件的支持度,表示超参数,分别用于设定控制和的比例值;
19、s2.3:根据上述两个公式定义及步骤s1中support、confidence和lift指标,分别计算所有潜在事件的因果强度值和增益分数值。
20、进一步地,步骤s3中的实现过程为:
21、s3.1:设定初始因果图的因果边的数量m,并将所有的事件对按照因果强度值从大到小排序;
22、s3.2:从排序后的事件对中,逐次选取前m个事件对作为初始因果边,在无环约束情况下生成初始因果图。
23、进一步地,步骤s4中的实现过程为:
24、s4.1:将初始因果图作为当前因果图,根据hawkes点过程计算其似然函数值;
25、s4.2:对于当前因果图中的每条因果边分别移除,得到新的邻居因果图,根据hawkes点过程分别计算其似然函数值;
26、s4.3:根据似然函数值的大小,选取邻居因果图中最大似然函数值,若其似然函数值大于初始因果图的似然函数值,则将该邻居因果图作为当前因果图,否则继续保留原因果图;如果所有邻居因果图的似然函数值都小于或等于当前因果图的似然函数值,则停止移除因果边操作,即停止删边操作,返回当前因果图作为最终结果;
27、s4.4:重复步骤s4.1-4.3,直到无法再移除因果边为止,得到因果图。
28、进一步地,步骤s5中的实现过程为:
29、s5.1:根据因果图,并根据增益分数值定义了要添加和删除的潜在边的集合如下:
30、式中满足和;
31、其中,表示需要添加的潜在边集合,表示需要删除的潜在边集合,表示第i个需要添加的潜在边,表示第j个需要删除的潜在边,表示第i个需要添加的潜在边的增益分数,表示第j个需要删除的潜在边的增益分数,i=1,2,…,,j=1,2,…,,表示时间类型的数量,表示因果图中边的总数;
32、s5.2:引入超参数控制添加或删除边的概率,具体来说,在初始搜索时希望更多地尝试添加边,设置一个较高的,随着搜索的进行,添加和删除边的概率趋于平衡,因此的值会逐渐降低,直到得到趋于平衡的;
33、s5.3:采取与步骤s4相同的方法,迭代地选择似然函数值最高的邻居因果图作为下一个因果图,如果所有邻居因果图的似然函数值都小于或等于当前因果图的似然函数值,则停止增/删边操作,返回当前因果图作为最终结果;
34、s5.4:重复步骤s5.1-s5.3,直到无法再增/删边为止,得到最终因果图。
35、一种存储设备,所述存储设备存储指令及数据用于实现一种格兰杰因果关系发现方法。
36、一种格兰杰因果关系发现设备,包括:处理器及所述存储设备;所述处理器加载并执行所述存储设备中的指令及数据用于实现一种格兰杰因果关系发现方法。
37、本发明提供的技术方案带来的有益效果是:
38、本发明根据时序数据采用关联规则挖掘算法计算support、confidence和lift;然后根据support、confidence和lift分别计算具备先验信息的指标:因果强度值和增益分数值;接着根据因果强度值,构造初始因果图;然后根据步骤s3生成初始因果图并结合hawkes点过程进行删边操作得到因果图;最后结合hawkes点过程并根据增益分数值对生成的因果图进行增边或删边操作得到最终因果图。基于关联规则和hawkes点过程的格兰杰因果发现方法,能有效利用关联规则所挖掘信息实现更准确地因果关系发现;关联规则信息指导下进行因果关系发现,能够加速因果结构发现效率,降低算法对处理器资源消耗;基于关联规则和hawkes点过程的方法具有因果结构发现精度高和资源消耗低的特点,方便扩展处理更复杂场景下的因果关系发现需求。