一种基于分形进化学习的钢水质量多任务预测方法
本发明涉及转炉炼钢终点质量多任务预测,尤其涉及一种基于分形进化学习的钢水质量多任务预测方法。
背景技术:
1、目前我国炼钢的主要方式就是转炉炼钢,终点控制作为转炉炼钢中极其重要的一环,主要的目标就是生产出终点的碳、氧的质量分数以及终点温度符合要求的钢水。当钢水中的碳、氧的含量过高,无法达到钢种的相关要求,同时也会阻碍到终点脱磷;而如果碳、氧含量过低,那么就会提高钢水终点氮含量。另一方面温度高低与原料的冶炼时间以及对应的消耗量是有紧密的关系的,温度会带给钢水质量很大的影响。这些因素都会影响出钢质量并且降低冶炼效率,终点预测模型是终点控制模型的基础,所以有必要建立准确的预测模型,并且不占用过多的资源,影响成本。
2、针对转炉炼钢终点碳、氧元素,温度的预测,传统的测量方法有人工经验与取样分析法、副枪检测法、炉气分析法、光谱辐射分析法等。人工经验与取样分析法是比较普遍的方法,但很容易就会受到现场工人操作限制,很难确保命中率;副枪检测能够快速、准确地检测终点质量,但由于副枪是工作在高温环境下的,需要定期更换副枪的探头,造成高昂的成本,并且这种方法只能用于点触式检测。如图1所示,通过转炉炼钢终点质量多任务预测技术可以为转炉炼钢终点控制提供有效依据,保证炼钢的质量,减少重复不必的补吹操作,能够有效的提高钢厂的生产效率,同时也能节约能源和原材料减少浪费。
3、近年来,智能算法在钢铁冶金方向的应用已经有很多成果,之前的研究使用的智能算法主要是神经网络,专利号zl201110324038.0的中国专利发明了一种采集转炉炼钢中的当前生产参数信息及转炉炉口当前的火焰信息作为自变量;创建神经网络,利用所述自变量构成的训练样本对创建的神经网络进行训练钢水的温度和钢水终点碳元素含量。专利号zl201810410253.4的中国专利发明了一种根据铁水初始状态的特征参数和冶炼目标钢种的要求,对终点碳含量和温度进行控制,预测模型为神经网络,神经网络具有很强的非线性逼近能力,但是求解过程也存在容易陷入局部最小,导致模型的误差偏高的问题。专利号zl201811382479.4的中国专利发明了一种基于改进正则化极限学习机的转炉终点锰含量预测方法,通过采集影响终点锰含量的数据作为模型的输入变量,能精确、快速的对转炉炼钢终点的锰含量进行预测,但此方法只能对锰元素进行预测,无法对炉内其他元素同时预测。专利号zl200910010672.x的中国专利发明了一种连续预测转炉熔池碳含量方法,利用数学模型进行分析计算,但是只单单预测出碳元素含量,未对其他的反应元素进行分析。
技术实现思路
1、本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于分形进化学习的钢水质量多任务预测方法,实现对转炉炼钢终点钢水质量的多任务预测。
2、为解决上述技术问题,本发明所采取的技术方案是:一种基于分形进化学习的钢水质量多任务预测方法,包括以下步骤:
3、步骤1、对钢厂的实际生产数据进行收集,分类和预处理,并分析转炉炼钢终点质量的主要影响因素,确定转炉炼钢终点质量预测模型的输入;建立转炉炼钢历史数据集合,并在历史数据集合中选取不同钢种的参考炉次数据集合;
4、步骤1.1:获取不同钢种在铁水入炉到钢水出炉整个吹炼过程期间产生的数据;
5、所述不同钢种在铁水入炉到整个吹炼过程期间产生的数据包括入炉铁水温度以及入炉碳元素含量、入炉硅元素含量、入炉锰元素含量、入炉硫元素含量、入炉磷元素含量、冶炼过程中的氧气累积量和氮气累积量信息;
6、步骤1.2:在转炉炼钢主要原料入炉前,记录入炉的主要原料重量以及不同时刻投入炉内的辅原料加入量;
7、转炉炼钢主要原料包括铁水和废钢;
8、辅原料包括块状石灰石、轻烧白云石、溶剂块矿、块白云石和脱硫剂;
9、步骤1.3:获取转炉炼钢终点时刻测得的钢水温度、氧元素含量、碳元素含量;
10、步骤1.4:将步骤1.1~步骤1.3所获得的数据作为转炉炼钢历史数据集合;
11、所述转炉炼钢历史数据集合包括:在铁水入炉时的铁水温度、碳元素含量、硅元素含量、锰元素含量、硫元素含量、磷元素含量、入炉铁水重量和入炉废钢重量、冶炼过程中的累积氧气加入量、累积氮气加入量、辅原料加入量,以及出钢过程中钢水终点温度、碳元素含量、氧元素含量;
12、步骤1.5:从转炉炼钢历史数据集合中选取不同钢种在一定温度范围内入炉时的铁水重量、废钢重量、铁水温度、碳元素含量、硅元素含量、锰元素含量、硫元素含量、磷元素含量信息,以及炼钢终点的炉内钢水温度、碳元素含量、氧元素含量信息作为不同钢种的参考炉次数据集合;
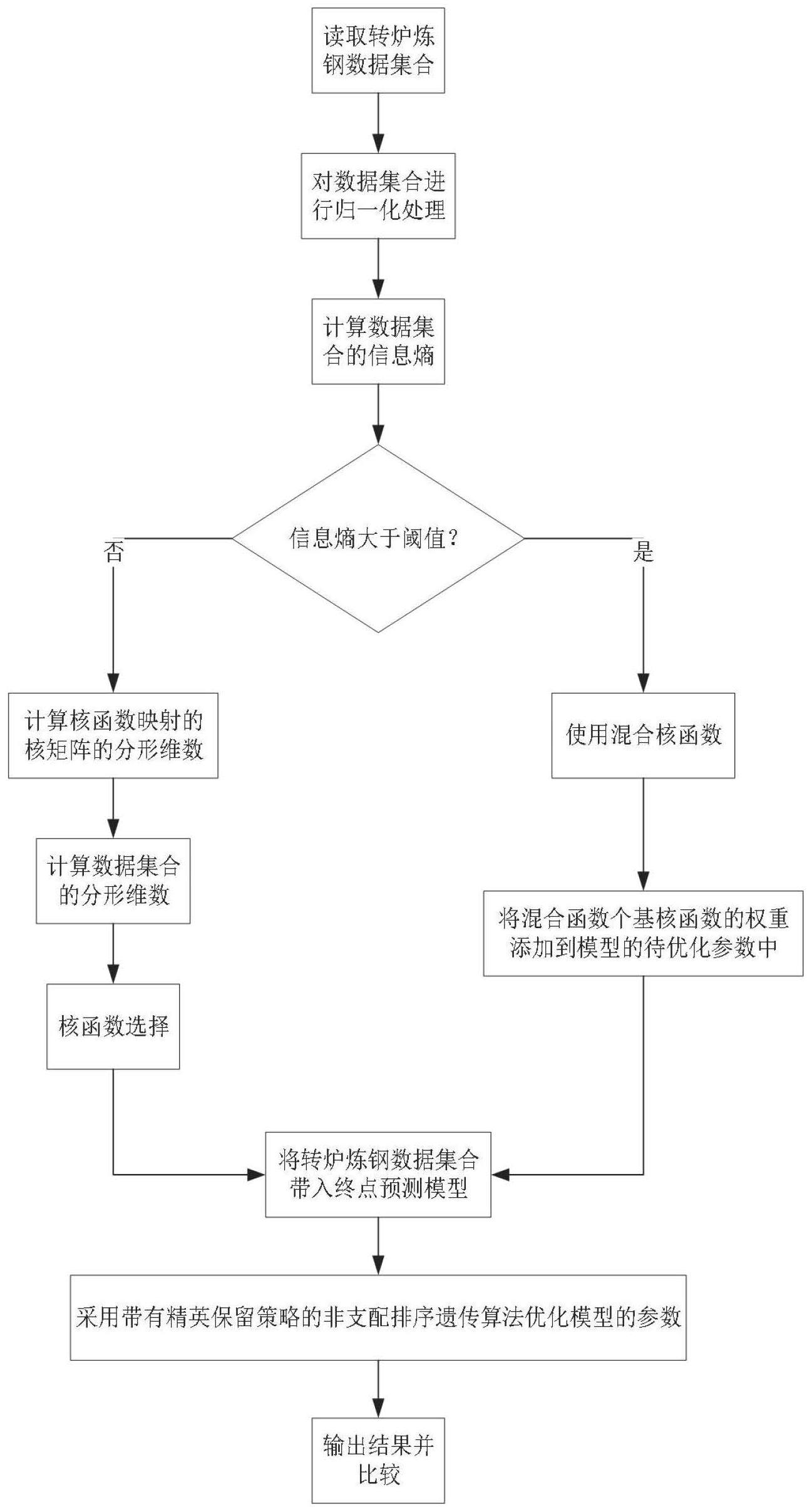
13、步骤2、以不同钢种的参考炉次数据集合作为转炉炼钢质量终点预测模型的输入,采用信息熵和分形理论进行多输出支持向量机的核函数选择,进而建立转炉炼钢质量终点预测模型,对转炉炼钢的终点碳含量、氧含量、钢水温度进行预测;
14、步骤2.1:以采集的炼钢过程中实际加入铁水重量、实际加入废钢重量、入炉铁水温度、累积氧气加入量、累积氮气加入量、辅原料投入量,以及入炉时的碳元素含量、硅元素含量、锰元素含量、硫元素含量、磷元素含量作为转炉炼钢质量终点预测模型的输入信息,炼钢过程中终点的钢水碳元素含量、氧元素含量以及终点温度作为转炉炼钢质量终点预测模型的输出;
15、步骤2.2:利用信息熵和分形理论进行转炉炼钢质量终点预测模型核函数的选择;
16、步骤2.2.1:将采集的参考炉次数据集合中实际加入铁水重量、实际加入废钢重量、入炉铁水温度、累积氧气加入量、累积氮气加入量、辅原料投入量、入炉时的碳元素含量、硅元素含量、锰元素含量、硫元素含量、磷元素含量的信息熵作为选择单一基核函数或者混合核函数的评价标准;
17、步骤2.2.2:分别计算步骤2.2.1中参考炉次数据集合分形维数和多输出支持向量回归机核矩阵的分形维数并将两者进行比较,以最小相差作为选取核函数标准;
18、步骤2.3:利用选取采集的钢水温度及碳元素、氧元素含量所在相应的范围内对应的转炉炼钢终点质量预测模型进行预测,将参考炉次数据带入到相应的各转炉炼钢终点质量预测模型,输出预测的钢水温度值及碳元素含量和氧元素含量值;
19、步骤3、通过多目标优化算法对转炉炼钢终点质量预测模型的参数进行优化;
20、步骤3.1:选取转炉炼钢质量终点预测模型的参数和混合核函数的权重作为带有精英保留策略的非支配排序遗传算法的决策变量;
21、初始化转炉炼钢终点质量预测模型的各个参数值,将初代参数组合群代入步骤2中的转炉炼钢终点质量预测模型,得到多输出支持向量回归机的输入层权重和偏置,用训练数据集训练模型,计算相应参数组合的目标函数值;
22、步骤3.2:将转炉炼钢终点质量预测模型的均方根误差当作模型精度、多输出支持向量回归机拟合的权重向量信息熵当作模型复杂度,分别将模型精度和模型复杂度作为非支配排序遗传算法多目标优化的目标函数,同时进行目标函数最小化处理,以实现转炉炼钢终点质量预测模型的参数优化;
23、步骤4、根据实际生产情况,对转炉炼钢终点质量预测模型进行不断更新升级,以保持模型预测精度;
24、步骤4.1:判断吹炼后期下副枪取样得到的钢水中碳元素含量、氧元素含量、钢水温度是否满足出钢条件,如果是,则钢水出钢,并执行步骤5;否则执行步骤4.2;
25、步骤4.2:判断吹炼后期下副枪时的各转炉炼钢终点质量预测模型输出的碳元素含量、氧元素含量、钢水温度预测值与取样值误差是否在偏差范围以内,如果是,则在下一次预测的时候继续用当前的转炉炼钢终点质量预测模型,并执行步骤5;否则,返回步骤3,调整多目标优化算法的参数选择范围,对模型参数进行进一步优化,然后再用于转炉炼钢终点质量预测;
26、步骤5、定期对转炉炼钢历史数据集合进行更新;
27、定期对历史数据集合进行增量式更新,将与更新后的转炉炼钢终点质量预测模型不相关的数据集删除,增强模型的适应性。
28、采用上述技术方案所产生的有益效果在于:本发明提供的一种基于分形进化学习的钢水质量多任务预测方法,建立转炉炼钢终点质量预测模型,对转炉炼钢终点质量进行多任务预测。与以往的预测模型相比,本发明方法建立的预测模型具有较高的终点命中率,能够满足实际生产的需求。转炉炼钢终点碳、氧元素含量和终点温度的命中率达到了预期效果,双命中率的结果符合静态预测模型的要求,适用于转炉炼钢的实际背景,可为后续静态控制和动态控制的研究提供理论依据,并且能快速地根据采集的数据同时预测多个成分的含量,并采用分形理论和带有精英保留策略的非支配排序遗传算法优化了模型的泛化能力,使转炉炼钢终点质量的预测精度进一步提升。同时在该模型基础上,可以建立转炉炼钢的终点控制模型,通过控制冷却剂加入量、吹氧量、氧枪高度,以使钢水的成分和温度达到终点预期。该方法为企业员工操作提供了必要的参考信息,提高了炼钢生产质量,降低了能源消耗,节约了生产成本。
- 还没有人留言评论。精彩留言会获得点赞!