一种面向区域分布式发电预测的联邦学习方法及系统
本发明涉及电力预测,具体为一种面向区域分布式发电预测的联邦学习方法及系统。
背景技术:
1、在区域分布式发电预测过程中,历史数据集是进行预测和优化的重要数据资源,但数据保护和隐私问题一直是数据交换的瓶颈。目前,数据交换的常规方式是通过集中式数据中心实现。但这种区域式存在中心化风险和数据隐私问题,如何实现分布式发电历史数据集的安全和高效交易并且提高各个数据用户提供真实数据的积极性是当前需要解决的问题。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种面向区域分布式发电预测的联邦学习方法及系统,解决了如何实现分布式发电历史数据集的安全和高效交易并且提高各个数据用户提供真实数据的积极性的问题。
3、(二)技术方案
4、为实现以上目的,本发明通过以下技术方案予以实现:
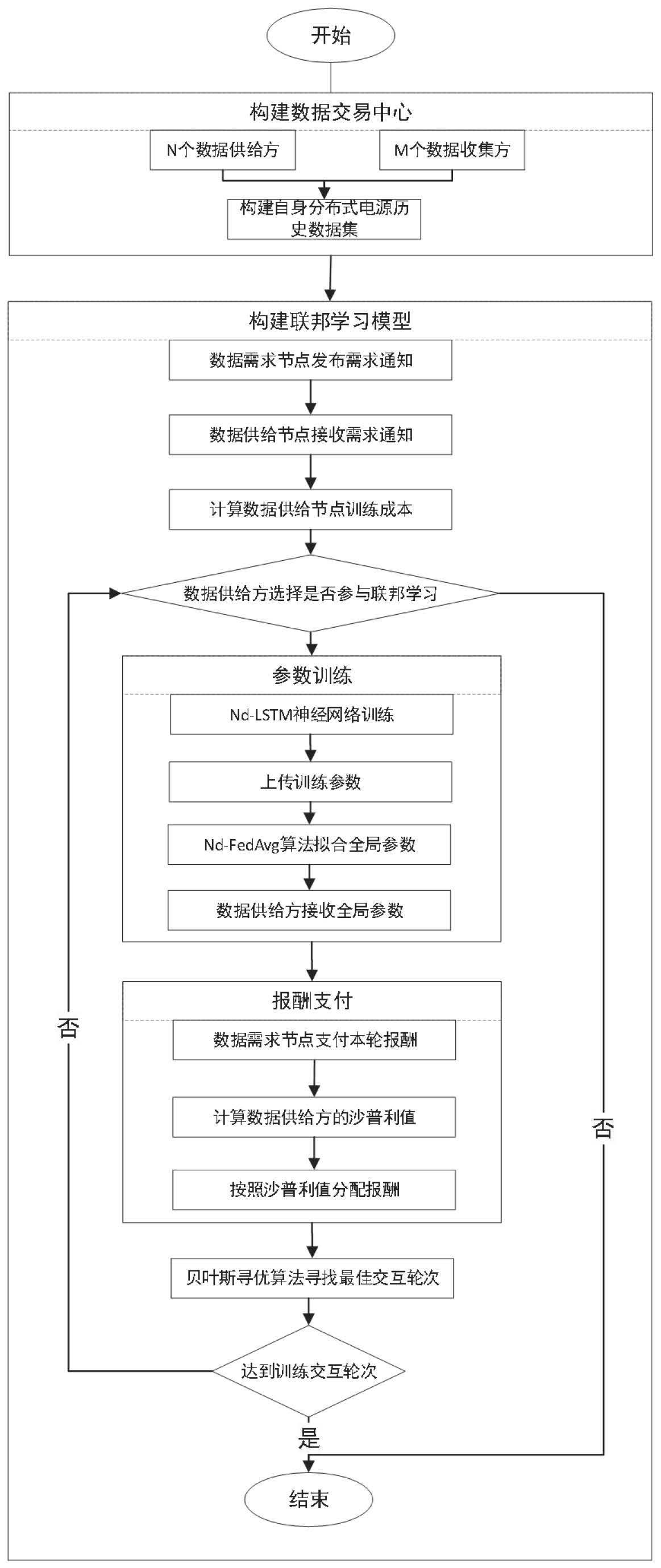
5、第一方面,提供了一种面向区域分布式发电预测的联邦学习方法,包括以下步骤:
6、数据划分步骤,基于划分的数据需求节点和数据供给节点,构建联邦学习初始化模型节点,所述数据需求节点和数据供给节点基于构建的各分布式发电节点历史数据集中按需求数据或供给数据进行划分;
7、成本计算步骤,计算数据供给节点的数据训练成本,判断数据供给节点是否参与数据交互:若数据训练成本小于需求节点提供的报酬中数据训练部分,则数据供给节点参与数据交互;若数据训练成本大于需求节点提供的报酬中数据训练部分,数据供给节点不参与数据交互;
8、参数训练步骤,将参与数据交互的数据供给节点的梯度参数上传并进行训练,将训练后的梯度参数上传至本地梯度需求节点。
9、优选的,发布数据需求通知的为数据需求节点,其余各区域称之为数据供给节点,其中n个数据供给节点可以表示为p={p1,p2,...,pn},m个数据需求节点可以表示为r={r1,r2,...,rm},其数据包括但不限于训练成本、所获得的报酬以及温度、光照、空气湿度和出力数据。
10、优选的,数据供给节点的数据训练成本由隐私成本、计算成本和数据成本组成,计算成本用于计算模型训练时自身所消耗的资源;隐私成本用于计算降低本地模型在上传时额外泄露隐私信息的成本,通过使用不同的梯度参数,达到最大程度减少隐私泄露的风险的效果;数据成本为不同区域获取本地数据时所花费的成本;将隐私成本、计算成本和数据成本量化得到训练成本。
11、优选的,所述训练成本的计算步骤为:
12、计算成本表示为:
13、cunit(pi)=αζcisifi2
14、其中,α为成本调控因子,ζ为获取数据过程中所需要花费的成本,ci为数据第i轮运算所需要花费的cpu周期;si为第i轮迭代的样本容量,fi为cpu时钟频率;
15、经过差分隐私处理后的梯度参数表示为:
16、
17、其中,μ,b表示laplace中分布的位置参数和尺度参数,δf表示噪声局部敏感度,∈是差分隐私预算;
18、
19、其中,隐私成本在计算过程中主要参考隐私预算i;
20、将上述隐私成本和计算成本量化后加上数据成本,得到最终的训练成本;训练成本表示为:
21、
22、优选的,所述参数训练步骤具体包括:
23、在首轮数据交互时,每个节点采用lstm神经网络对本地数据进行训练,生成并上传本地模型参数,训练完成后的模型参数为:
24、
25、其中wk,t为节点k经过lstm神经网络训练t轮过后的神经元权重系数,简称模型参数,为训练过程中的梯度下降,η为lstm神经网络训练过程中的学习率;
26、通过fedavg算法得到全局模型参数wg,t,fedavg算法生成第t轮全局模型参数wg,t的公式如下:
27、
28、其中,n为所有参与数据供给节点的总数;k为筛选出的节点个数;
29、在接收到梯度参数后,数据需求节点ri支付报酬bi,通过沙普利值对数据供给节点在联邦学习模型第r轮数据交互中的贡献v(pir)进行报酬分配实现数据供给激励。同时对于连续多次贡献度小于0的数据供给节点予以禁止参与交易处罚。
30、优选的,所述数据需求节点根据沙普利值分配数据供给节点的数据供给效用,在联邦学习训练过程中,pi拥有随时参与和退出数据供给的权力,每轮供给效用最终累计数据供给节点pi参与联邦学习时的沙普利值分配,按其贡献值分配交易报酬计算公式为:
31、
32、
33、
34、其中,是第r轮参与数据供给的节点的子集,即表示sr不含pi的数据供给节点集合,n为数据供给节点的个数,v(pir)为数据供给节点pi参加训练后对在第r轮训练中对于模型性能提升的贡献度,其中k1,k2分别为各分布式节点的时间和准确率权重参数,为pi的第r轮训练时间,为第r轮所有数据供给节点第轮训练的平均时间,为第r轮所有数据供给节点的平均数据均方差,为pi第r轮训练的数据均方差,k1<0表示各分布式区域数据训练时间以短为优,k2<0表示各分布式区域数据均方差也以低为优;
35、若数据供给节点pi对于模型性能提升贡献度为0,则其ξi也为0,若数据供给节点的模型性能提升贡献度为负时,其可以支付一定报酬换取质量更高的模型参数,完成自身参数的更新;在每轮交易结束之后对各数据供给节点贡献度进行记录,当任一数据供给节点连续三次贡献度为负时,则判定其提供虚假数据,对其禁止参与剩下所有数据交互轮次,实现激励数据供给节点提供真实数据。
36、优选的,所述训练步骤过程中,行动策略表示为为迭代次数,为训练成本,训练成本的策略选择即为通过对控制迭代次数的博弈求得迭代次数和行动策略的最优解,直至所述参数训练步骤结束;
37、在行动策略贝叶斯博弈定义如下为其中p代表数据供给节点pi,ω为状态空间,具体代表pi的训练成本ccos(pi),表示数据供给节点的行动策略μ表示数据供给节点pi选择时的先验概率,效用函数≥为的行动偏好;pi在pbg中通过参考除pi外的其他数据供给节点μ,达到优化行动策略从而求解贝叶斯纳什均衡以获得数据供给节点行动策略的最优解,实现各区域效用之和最大化。
38、优选的,在求解最佳行动策略的贝叶斯纳什均衡解时,应满足以下约束:
39、仅当pi∈p和满足时,所有参与联邦学习的行动策略是博弈中的一个贝叶斯纳什均衡解:
40、
41、其中,p\{pi}表示表示数据供给节点中不含pi的集合,表示在数据供给节点pi与其他数据供给节点p\{pi}进行贝叶博弈时,pi所预期获得的效益;
42、仅当报酬函数满足博弈能够达到纳什均衡状态其中表示行动策略为的概率,表示当行动策略为时所产生的成本;
43、在求解各分布式区域的最佳行动策略过程中,将各数据供给节点pi在r轮训练过程中应获得的收益表示为训练成本为数据需求节点的总收益为由此各区域总收益最大化问题表示为成本约束表示为
44、
45、
46、
47、各区域总收益最大化问题采用朗日乘法构建为拉格朗日函数为
48、
49、根据拉格朗日乘法公式对函数中的和λ分别一阶偏导可得:
50、
51、得到的最优解为:
52、
53、
54、当数据供给节点的训练策略为时,分布式数据供给节点的收益供给之和为最大化且训练策略不便,取纳什均衡状态。此时通过基于的凸函数性质进行证明;
55、由slater条件可知,总收益最大化满足强对偶条件,此时满足其中为的拉格日朗鞍点,同时在区域总收益最大化约束下的kkt条件为:
56、
57、
58、
59、第二方面,提供了一种面向区域分布式发电预测的联邦学习系统,包括以下模块:
60、数据划分模块,用于基于划分的数据需求节点和数据供给节点,构建联邦学习初始化模型节点,所述数据需求节点和数据供给节点基于构建的各分布式发电节点历史数据集中按需求数据或供给数据进行划分;
61、成本计算模块,用于计算数据供给节点的数据训练成本,判断数据供给节点是否参与数据交互:若数据训练成本小于需求节点提供的报酬中数据训练部分,则数据供给节点参与数据交互;若数据训练成本大于需求节点提供的报酬中数据训练部分,数据供给节点不参与数据交互;
62、参数训练模块,用于将参与数据交互的数据供给节点的梯度参数上传并进行训练,将训练后的梯度参数上传至本地梯度需求节点。
63、第三方面,提供了一种计算设备,包括:
64、一个或多个处理器、存储器以及一个或多个程序,其中一个或多个程序存储在所述存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个程序包括用于执行所述的方法中的任一方法的指令。
65、(三)有益效果
66、本发明一种面向区域分布式发电预测的联邦学习方法及系统,通过构建分布式电源数据交互中心,实现了分布式电源历史数据的交互和共享,从而提高了数据的利用效率和经济效益。同时,采用联邦学习模型和贝叶斯博弈算法,保证了数据隐私和安全,提高了数据交互的效率和准确性。此外,通过数据交互报酬的分配,激励数据提供节点参与数据交互,促进了分布式电源数据的共享和可持续发展。
- 还没有人留言评论。精彩留言会获得点赞!