一种基于零样本学习的两阶段解耦图像去雾方法
本发明涉及图像去雾,具体涉及一种基于零样本学习的两阶段解耦图像去雾方法。
背景技术:
1、雾霾是一种由于空气中颗粒物大量的聚集和悬浮而产生的现象。由于大气光的吸收和散射,光线在传播时受到颗粒物的影响,使得各种图像采集设备所获取的图像清晰度、对比度降低,图片降质严重,给后续的各种图像处理操作带来较大的困难。在严重的情况下,这些因素还会使图像中的颜色信息失真,从而使各类计算机视觉技术更加难以应用。
2、近年来,随着计算机视觉系统的普及,这些系统在道路、航空和其他领域中发挥了重要作用,但雾天低能见度的天气对航空、道路交通等视觉设备造成了极大的困扰。因此,图像去雾一直是计算机视觉领域研究的一个焦点。
3、图像去雾的目的是从观测到的雾霾图像中估计潜在的无雾图像。对于单图像去雾问题,有一个常用的模型来表示雾霾图像的退化过程:
4、i=j(x)t(x)+a(1-t(x))
5、其中i为雾霾图像,j为潜在的无雾图像,a为全局大气光,t为传输图,x为像素位置信息。而传输图可以表示为:
6、t(x)=e-βd(x),
7、其中,β是大气的散射系数,d是场景深度。
8、以上所述可以看出,图像去雾是一个典型的不适定问题。由此,许多图像去雾方法被提出,它们大致可以被分为基于先验的方法和基于学习的方法。基于先验的方法,即传统的去雾方法,倾向于使用图像本身具有的先验知识进行去雾。例如:暗通道先验(dcp)来检测图像的雾霾分布,颜色衰减先验(cap)来估计传输图,虽然这些基于先验的方法取得了一定的效果,但是所使用的先验知识在实践中很容易被推翻,并且在复杂的实际场景中鲁棒性较低。
技术实现思路
1、针对现有技术存在的不足,本发明的目的在于提供一种基于零样本学习的两阶段解耦图像去雾方法,该方法基于零样本学习,直接将雾霾图像输入网络进行去雾,无需提供雾霾-干净图像对,避免了大规模的数据训练;同时,该方法在恢复无雾图像的过程中,不仅能保证多尺度特征的提取,同时能保证原始尺度和邻域信息的提取。
2、为实现上述目的,本发明提供了如下技术方案:一种基于零样本学习的两阶段解耦图像去雾方法,包括以下步骤:
3、(1)获取真实的单图像去雾(realistic single image dehazing,reside)数据集中的合成目标测试集(synthetic objective testing set,sots)和混合主观测试集(hybrid subjective testing set,hsts)的两个测试子集,对原始数据集进行预处理,作为测试集;
4、(2)构建去雾网络模型:根据大气散射物理模型i=j(x)t(x)+a(1-t(x)),
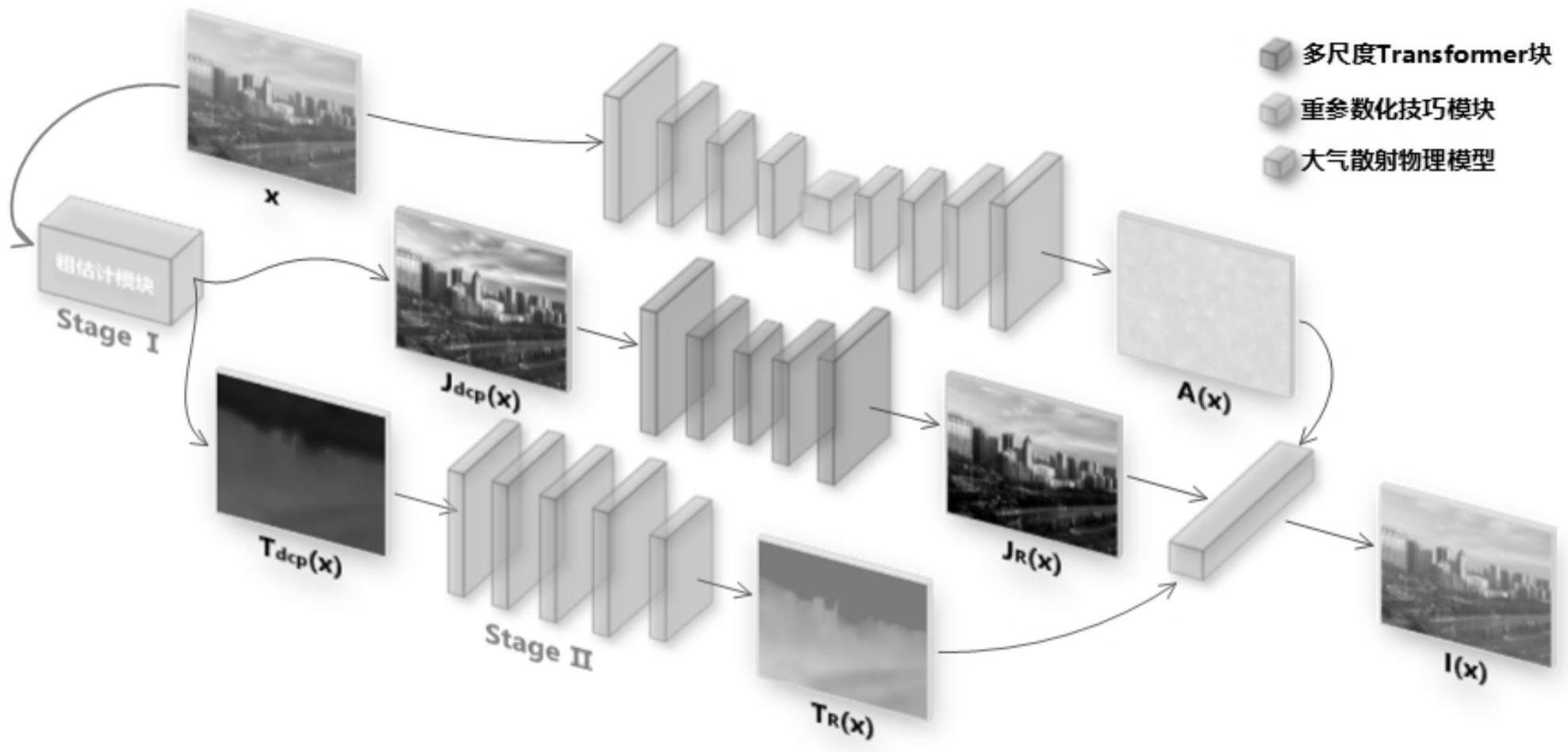
5、其中x表示输入的雾霾图像,i(x)表示重构后的有雾图像,j(x)表示原始的场景信息,即清晰无雾图像,t(x)表示透射率,a表示大气散射光。
6、基于解耦的思想将网络模型分为潜在的无雾图像层、传输图层和全局大气光层三层,对潜在的无雾图像以及传输图层使用两个阶段进行估计,第一阶段使用嵌入的暗通道先验进行粗略估计,第二阶段则分别使用无雾图像细化网络和传输图层细化网络进行精细化的估计,对于全局大气光,使用一个编码器-解码器网络(即大气光估计网络)来估计,在网络的顶端,将三个子网络(无雾图像细化网络、传输图层细化网络以及大气光估计网络)估计的图像再根据大气散射物理模型重构,获得重构后的雾霾图像;
7、(3)将预处理后的数据集中的雾霾图像输入到构建好的去雾网络模型中,根据设计好的损失函数计算损失,不断迭代更新参数,对雾霾图像直接进行图像去雾。
8、作为优选的:步骤(2),第一阶段的粗略估计具体包括以下步骤:
9、(2.1)计算输入图像x的暗通道:先取rgb三通道中的最小值来构建灰度图,然后再对灰度图取逆,进行最大池化操作,对最大池化后的结果取逆即得到idark,具体公式为其中ic指的是i的r,g,b通道之一;
10、(2.2)计算传输图的粗略估计tdcp(x):将idark带入大气散射物理模型得到idark(x)=jdark(x)t(x)+a(1-t(x)),其中idark(x)和jdark(x)分别是图像i和j的暗通道;对于大气光a,在idark中选取亮度前0.1%的像素,取其平均值为大气光a的值;而对于jdark,根据暗通道先验的假设,对于户外无雾图像j的非天空区域的暗通常趋向于零,jdark(x)→0,从而根据得到传输图的初步结果;由于暗通道图片存在的边缘过渡不平滑,采用导向滤波的方式使得tdcp(x)的边缘更为平滑,使用一个平均池化操作实现导向滤波,该平均池化操作的内核大小为19*19,步幅为1。
11、(2.3)计算无雾图的粗略估计jdcp(x):根据大气散射物理模型,且已知大气光a和传输图tdcp(x),jdcp(x):通过等式计算获得
12、作为优选的:步骤(2),构建去雾网络模型的三个子网,具体包括以下步骤:
13、(a)无雾图像细化网络的架构是一种改进的5级u-net架构,其卷积块被引入的多尺度transformer块所取代,并且使用sk融合模块来进行不同层之间的连接和融合,使用了软重建层来获得全局残差;
14、(b)传输图细化网络是一种由五个卷积层构成的非退化结构的网络,前四个层中,每一层都只包括卷积层、批处理归一化层和leakyrelu激活函数,最后一层包含了卷积层以及一个将输出归一化为[0,1]的sigmoid函数;
15、(c)大气光估计网络是一个对称的编码器-解码器架构的网络,网络的编码器和解码器各有四层,其中编码器的每一层均包含了卷积层、relu激活函数和最大池化层,解码器的每一层均包含了上采样、卷积层、批处理归一化层和re lu激活函数,在编码器和解码器的中间,使用了一个重参数化技巧模块,该模块将编码器的输出转换为潜在的高斯分布,然后对其进行重采样,再输入解码器。
16、作为优选的:步骤(a)中,构建多尺度transformer块,具体包括以下步骤:
17、(a1)采用rescalenorm层作为归一化层,rescalenorm的具体归一化过程表示为:
18、其中f(·)表示多尺度transformer块中的主要部分多尺度自注意力,分别表示均值和标准差,分别是学习到的比例因子和偏差,和分别为两个用于转换μ和σ的线性层权重和偏置项,转换过程表示为{γ,β}={σwγ+bγ,μwβ+bβ},为了加速收敛,bγ和bβ初始化为1和0。
19、(a2)采用多尺度自注意力来计算自注意力,多尺度自注意力(multi-scale self-attention,mssa)拥有两个分支,聚合窗口内的多尺度特征信息,同时在一定程度上保留邻域的信息。
20、作为优选的:步骤(a2)中,计算多尺度自注意力(multi-scale self-attention,mssa),包括两个分支:
21、(a21)在分支中,对查询向量q、键向量k、值向量v进行不同的处理,对于q,保留原始的尺度,对其进行普通的全连接操作,对于键k,值v,在同一自注意力层中,使用尺度变换(st)来获得不同尺寸的k和v,具体表示为:
22、q=xwq,
23、ki,vi=sti(x)wik,sti(x)wiv,
24、vi=vi+lei(vi),
25、其中x表示输入的特征序列,wq,wik,wiv是第i个尺度层在自注意层同一头部的线性投影参数,lei(·)是深度卷积的局部增强分量;而sti(·)是第i个尺度层的尺度变换操作,它提供对x的降采样,可具体表示为:
26、sti(x)=ln(convi(x)),
27、其中,ln(·)是指层归一化(layernormalization);convi(·)是指第i个尺度层所使用的卷积,不同尺度层所用的内核大小和步幅不同,从而造就了不同的尺度变换;因此,在同一自我注意力层中,键和值捕捉到不同尺度的特征;然后,自注意力头head可以计算为:
28、
29、其中softmax(·)是激活函数,t表示转置操作,d是维度,将不同的头连接,通过以下方法计算主要分支中的多头自我注意(multi-head selfattention,mh):
30、mh(q,k,v)=concat(head0,…,headj)wo,
31、其中concat(·)是连接操作,headi表示第i个自注意力头,wo是线性投影参数;
32、(a22)另一个保留邻域信息的分支仅对输入的特征依次进行线性投影和卷积操作,多尺度自注意力mssa可表示为:
33、mssa=concat(mh{q,ki,vi}i=1,…,m)+conv0(xw0),
34、其中concat(·)是连接操作,mh表示多头自我注意力,q,ki,vi分别表示查询向量、第i个尺度层的键向量、第i个尺度层的值向量,conv0(·)是指卷积操作,x是输入的特征序列,wo是线性投影参数;
35、作为优选的:步骤(3)中,所述损失函数由五个损失函数构成:
36、(3.1)重建损失lrec,用于计算输入图像与重建后图像的误差,以此来约束整个网络,lrec定义为:
37、lrec=||i(x)-x||f,
38、其中,||·||f表示给定矩阵的弗罗比尼乌斯范数,x是输入的雾霾图像,i(x)是由三个子网的输出重建成的雾霾图像;
39、(3.2)损失函数lj,用于计算无雾图像估计jr(x)的亮度和其饱和度之间的差,具体表示为:
40、lj=||v(jr(x))-s(jr(x))||f,
41、其中,v(·)表示亮度,s(·)表示饱和度,||·||f表示给定矩阵的弗罗比尼乌斯范数。
42、(3.3)大气光损失lh,用于计算估计的大气光a(x)和ainit(x)之间的损失,其中ainit(x)是从输入的图像数据中自动估计的初始化大气光,lh具体表示为:
43、lh=||a(x)-ainit(x)||f.
44、(3.4)lkl是大气估计光网络中重参数化模块的的变分推理项损失,使网络中重采样后的潜码和采样前的z差异最小化,在数学上,
45、
46、其中,kl(·)表示两个分布之间的kullback-leibler散度,zi表示z的第i个维度,μz,σz分别表示z的均值和标准差,分别表示zi的均值和标准差;
47、(3.5)为了避免网络过拟合设置的正则项损失lreg,具体表示为:
48、
49、其中,n(·)表示二阶邻域,|n(·)|表示二阶邻域的大小,n表示a(x)的像素数,a(x)表示大气光;
50、总损失通过结合以上五种损失函数来定义:
51、l=lrec+lj+lh+lkl+λlreg,
52、其中,lreg前的参数λ是用来平衡正则化的一个非负参数,在实践中为0.1。
53、采用上述技术方案,本发明具有如下有益效果:
54、本发明构建图像去雾网络模型:根据大气散射物理模型,基于解耦的思想将网络模型分为三个层,即潜在的无雾图像层、传输图层和全局大气光层。对潜在的无雾图像以及传输图层使用两个阶段进行估计,第一阶段使用嵌入的暗通道先验进行粗略估计,第二阶段则分别使用无雾图像细化网络和传输图层细化网络进行精细化的估计。对于全局大气光,使用一个编码器-解码器网络来估计。在网络的顶端,将三个子网估计的图像再根据大气散射物理模型重构,获得重构后的雾霾图像。在去雾网络模型的精细无雾图像的子网络中引入一种新的多尺度transformer块,它在自关注部分执行多尺度令牌聚合,使其能够捕捉不同尺度的特征,并有效地恢复雾霾图像中的潜在场景信息。
55、本发明基于零样本学习,直接将雾霾图像输入网络进行去雾,无需提供雾霾-干净图像对,避免了大规模的数据训练;同时,该方法在恢复无雾图像的过程中,不仅能保证多尺度特征的提取,同时能保证原始尺度和邻域信息的提取。
56、下面结合说明书附图和具体实施例对本发明作进一步说明。
- 还没有人留言评论。精彩留言会获得点赞!