一种基于Transformer的多变量时间序列异常检测方法
本发明涉及时间序列异常检测,尤其是涉及一种基于transformer的多变量时间序列异常检测方法。
背景技术:
1、随着工业化进程不断的完善,在此过程中会产生和存储大量的数据,在各类数据类型中,时间序列数据是其中重要的数据类型之一。时间序列数据是指随着时间的推移,在某些指标上每隔一定时间进行采集,并将采集到的结果按顺序排列从而形成的序列数据。时间序列数据描述了系统各个维度随时间的变化情况,对于捕捉前后数据间的关联,分析系统的发展情况具有重要意义。
2、因此,时间序列异常检测一直以来都是工业界的重要课题,其通过对连续的时间序列数据进行分析,以确定哪些实例与其他实例不同,即发掘出其中存在的异常。时间序列数据在很多领域都有实际应用,比如金融市场,生物数据,用户行为,工业设备等,分析时间序列数据的异常情况,对于保障系统正常运转、及时做出预判以免造成经济损失等均具有重要意义。
3、传统的异常检测任务由数据挖掘专家完成,他们通过人工分析不遵循正常趋势的数据来报告错误。然而,在监测工业设备的系统中,随着部署的传感器数量的不断增加,数据模式的复杂度不断提高,人工识别故障面临的挑战也越来越大。在人工智能的发展下,大数据分析和深度学习的出现,可以有效帮助专家解决这一问题。目前,时间序列异常检测技术所采用的方法主要包括基于聚类或分类的方式、基于深度学习的方式这两种,但是这些方法依然存在着相应的问题:
4、第一,基于聚类的异常检测方法难以确定聚类的类别数k。基于聚类的方法中较为经典的方法是k-means聚类算法,该方法也被称为子序列时间序列聚类。给定某个时间序列数据,根据定义的滑动窗口长度,可以将时间序列数据转换成一系列的子序列。在定义了聚类的个数k后,k-means聚类算法将作用在子序列上,直到该子序列可以收敛到k个类别。为了进行时间序列异常检测,需要计算每个子序列到最近的类别的距离,通常采用欧式距离进行计算,将该距离和阈值相比,若大于阈值,则对应的时间序列为异常。然而提前假设k的取值,对于现实的系统操作是比较困难的。
5、第二,基于分类的异常检测方法是将异常检测问题看成分类问题。先用训练数据集对模型进行优化训练,然后使用根据训练过程学习到的模型对测试集中的数据进行检测。根据训练集中异常被标记的情况,可以将基于分类的异常检测方法分为多分类异常检测和单分类异常检测。最初的支持向量机算法是单分类异常检测方法,它是一种线性监督方法。通过引入内核技巧来扩展算法,该技巧使svm能够进行非线性分类。之后,引入了一种新的使用svm(support vector machine,支持向量机)检测异常的方法,称为一类svm(one-class support vector machine,oc-svm)。oc-svm是一种半监督的方法,其中训练集仅包含一个类别:正常数据。在训练集中拟合模型后,测试数据被归类为是否与普通数据相似,这样能够检测异常。但是现实中的系统通常标签极不平衡,分类方法在标签极不平衡的数据集上准确率不高,且多数现实数据集的训练集通常也会包含异常数据。
6、第三,基于循环神经网络的异常检测方法依赖于一个循环神经网络的深度神经网络模型,它使用输入序列作为训练数据,对于每个输入的时间戳,预测下一个时间戳的数据,将预测误差作为异常检测的依据。例如lstm(long short-term memory,长短期记忆网络)是一种学习顺序数据中顺序依赖性的自回归神经网络,其中每个时间戳的预测使用来自前一个时间戳输出的反馈。然而,由于这类模型是一个循环模型,在输入的时间序列较长的情况下,训练速度较慢,特别是当输入数据有噪声时,这种表现更为明显。此外,但这类系统没有考虑不同时间序列之间的相关性。因此,这类在具有序列相关性的数据集中的效果并不理想。
7、第四,基于图神经网络的异常检测方法是近年来最受关注的系统方法之一,但是它依赖于图结构的构建。图神经网络主要关注以图形式存在的数据,挖掘图中不同节点之间的关系、以及边的关系。此类方法无法直接用于时序数据下的异常检测问题,需要提前构建显式的图结构。基于图神经网络的异常检测系统有效地利用了时间序列之间的相关信息,提高了异常检测的准确率。但是这种方法依赖显式地构建出图数据结构,在处理维数较少或序列间关系不够密切的多变量时间序列时,图神经网络构造的特征关系图太小或太稀疏。这使得图神经网络模型能从数据中提取的信息有限,从而导致系统的性能瓶颈。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于transformer的多变量时间序列异常检测方法,能够准确且具有鲁棒性地针对多变量时间序列进行异常检测。
2、本发明的目的可以通过以下技术方案来实现:一种基于transformer的多变量时间序列异常检测方法,包括以下步骤:
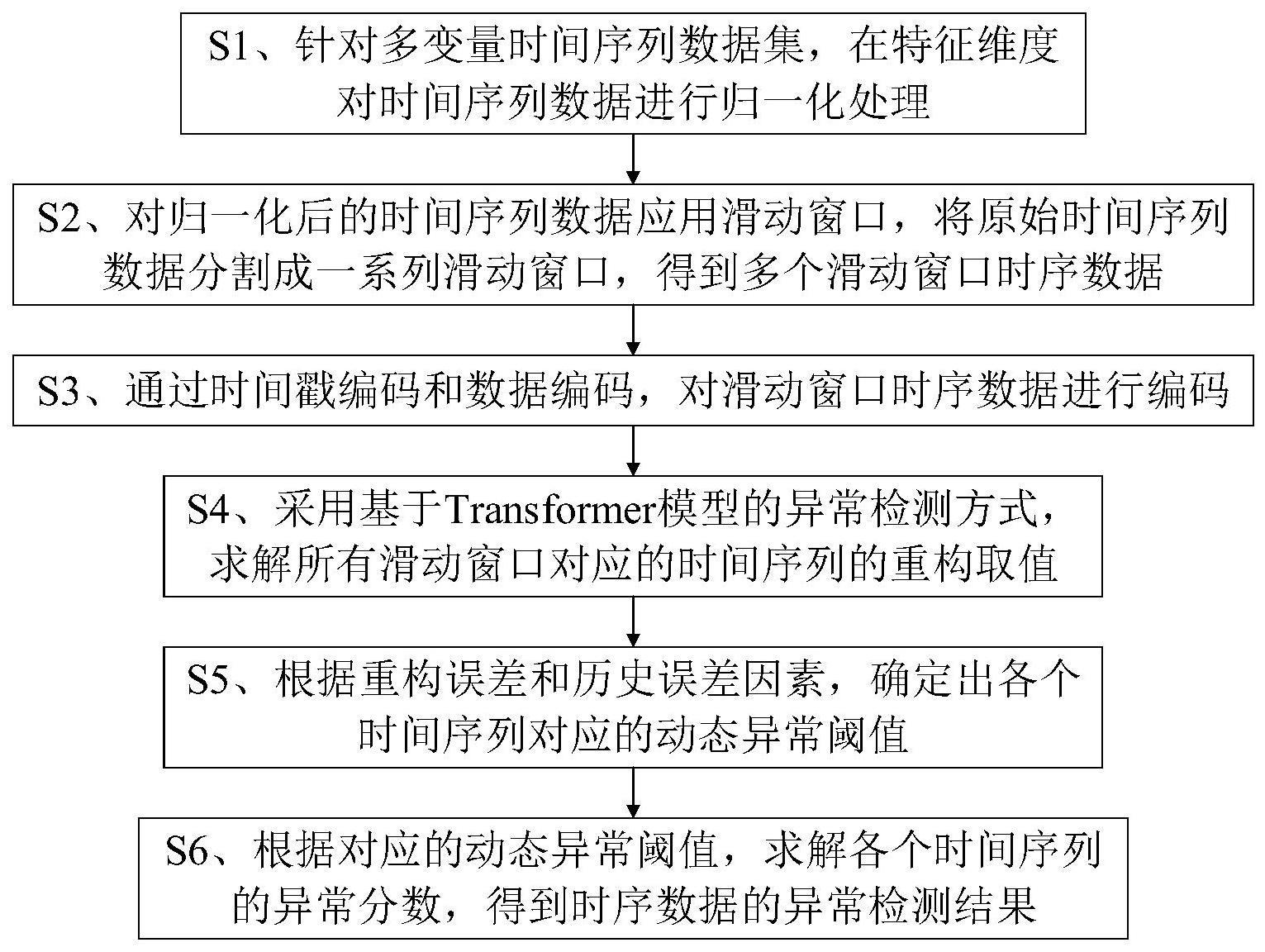
3、s1、针对多变量时间序列数据集,在特征维度对时间序列数据进行归一化处理;
4、s2、对归一化后的时间序列数据应用滑动窗口,将原始时间序列数据分割成一系列滑动窗口,得到多个滑动窗口时序数据;
5、s3、通过时间戳编码和数据编码,对滑动窗口时序数据进行编码;
6、s4、采用基于transformer模型的异常检测方式,求解所有滑动窗口对应的时间序列的重构取值;
7、s5、根据重构误差和历史误差因素,确定出各个时间序列对应的动态异常阈值;
8、s6、根据对应的动态异常阈值,求解各个时间序列的异常分数,得到时序数据的异常检测结果。
9、进一步地,所述步骤s3具体包括以下步骤:
10、s31、将时间戳包含的时序信息分解为对应的时间戳数据,并进行时间戳编码,得到时间戳编码向量;
11、s32、采用傅里叶变换的方式,对时间序列数据的周期性进行分析,并对时间戳数据进行周期性编码,得到周期性编码向量;
12、s33、对周期性编码向量和时间戳编码向量进行嵌入和投影,得到全局时间序列编码;
13、s34、对滑动窗口内的时序数据进行局部时间序列编码;
14、s35、将全局时间序列编码与局部时间序列编码附加到输入的时序数据中,得到transformer模型的输入数据。
15、进一步地,所述步骤s33具体是通过可学习的嵌入层,以对周期性编码向量和时间戳编码向量进行嵌入和投影操作。
16、进一步地,所述步骤s4中transformer模型包括编码器、特征融合模块、第一判别器、解码器、第二判别器,所述编码器包括特征注意力模块和时序注意力模块,所述编码器用于将输入数据中的子序列转换成对应的隐变量;
17、所述特征融合模块用于将编码器输出的多个隐变量组合成一个向量表示;
18、所述第一判别器与编码器之间构成第一对抗网络,通过对隐变量施加先验分布,采用对抗训练策略引导隐变量的先验分布和后验分布达到近似;
19、所述解码器用于重构原始输入,得到重构结果;
20、所述第二判别器与解码器之间构成第二对抗网络,用于对重构结果和原始输入之间施加对抗训练。
21、进一步地,所述步骤s4的具体过程为:
22、s41、将原始输入数据传输到编码器中,应用多维注意力机制,分别运行特征注意力模块和时序注意力模块,将原始时间序列输入x转换成隐变量y;
23、s42、对t个不重叠的子序列重复步骤s41的操作,得到对应的t个隐变量y;
24、s43、通过线性插值的方式,将t个实例、即t个隐变量y进行特征融合操作,形成新的隐变量编码z;
25、s44、对于隐变量施加先验分布,采用对抗训练策略引导隐变量的先验分布和后验分布达到近似;
26、s45、将隐变量输入到解码器中,重构模型的原始输入,得到重构结果x’;
27、s46、对重构结果x’和原始输入x之间施加对抗训练,得到训练好的异常检测模型,将当前输入数据传输给异常检测模型,输出得到所有滑动窗口对应的时间序列的重构取值。
28、进一步地,所述步骤s41中,特征注意力模块用于学习时间序列的不同特征之间的相关性,时序注意力模块用于学习时间序列内部的长短期依赖关系;
29、所述步骤s41的具体过程为:
30、首先将输入数据传输给特征注意力模块,使用时间序列的输入数据计算得到特征编码,得到特征编码后,将原始的时间序列输入与特征编码相结合,此时时间序列的原始输入x转换为隐变量y;
31、之后,将隐变量y输入到时序注意力模块中,获取时序特征,得到时序特征后,结合时序注意力模块的输入y,将时间序列转换为隐变量z:
32、z=k1·ova+k2·ota+x+time_enc(x)
33、其中,ova为特征编码,ota为时序特征,k1为特征注意力模块的加权系数,k2为时序注意力模块的加权系数,time_enc(x)为输入x的时间编码结果。
34、进一步地,所述步骤s43中,t个实例表示为:
35、
36、通过线性插值将t个实例合并为一个向量:
37、
38、其中,是时序为t的特征向量。
39、进一步地,所述步骤s44的具体过程为:
40、假设z满足先验分布p(z),原始数据x满足分布p(x),q(z|x)是编码的分布,编码器通过以下方式产生关于隐变量z的后验分布:
41、
42、其中,是时序为t的原始数据;
43、假设q(z|xkt)满足高斯分布,采用重新参数化技巧通过编码器网络进行反向传播,第一判别器d1用来引导隐变量z的后验分布q(z)和其先验分布p(z)之间类似,第一判别器的目标是放大彼此之间的距离;另一方面,由编码器构成的生成器g1为了迷惑第一判别器d1,则试图缩小彼此之间的差距,该过程对应以下优化目标,采用最大最小策略来优化:
44、
45、其中,v(d1,g1)为编码器与第一判别器之间的交叉熵损失。
46、进一步地,所述步骤s46中对重构结果x’和原始输入x之间施加对抗训练的具体过程为:
47、解码器g2根据编码器g1的生成产生重构:
48、x′t=g2(g1(xtk))
49、解码器g2的目标为迷惑第二判别器d2,此过程对应的优化函数如下所示:
50、
51、其中,v(d2,g2)为解码器与第二判别器之间的交叉熵损失。
52、进一步地,所述步骤s5的具体过程为:
53、s51、计算所有时间序列数据的真实时间序列数据与重构时间序列数据之间差值的绝对值:
54、
55、s52、将历史重构误差进行缓存,在时刻t,计算出对应的重构误差后,将其加入到历史误差向量中,如下式所示:
56、
57、s53、运用平滑平均模型对重构误差进行平滑处理,对误差进行多次代换,将经过滑动平均处理的误差序列记为:
58、
59、s54、基于经过平滑处理后的误差序列,确定出误差阈值ε:
60、
61、其中,δμ为误差均值的差,μ为误差均值,δσ为误差方差的差,σ为误差方差,若时间点对应的重构误差大于误差阈值ε,则表明该时间点发生异常,否则该时间点正常。
62、进一步地,所述步骤s6中时间序列的异常分数的计算公式为:
63、
64、其中,s(i)为第i个子序列对应的异常分数,e(i)为第i个子序列的误差。
65、与现有技术相比,本发明具有以下优点:
66、一、本发明针对多变量时间序列,首先在特征维度对时间序列数据进行归一化处理并且应用滑动窗口,以将原始时间序列数据分割成一系列滑动窗口;再通过时间戳编码和数据编码,对滑动窗口内的时序数据进行编码;采用基于transformer模型的异常检测方法,求解所有滑动窗口对应的时间序列的重构取值;再根据重构误差和历史误差因素,确定出各个时间序列对应的动态异常阈值,并进一步求解各个时间序列的异常分数,从而衡量时序数据的异常程度。由此能够准确地对多变量时间序列进行异常检测,且能保证检测过程的鲁棒性。
67、二、本发明中,设计transformer模型包括编码器、特征融合模块、第一判别器、解码器、第二判别器,利用编码器将输入数据中的子序列转换成对应的隐变量;利用特征融合模块将编码器输出的多个隐变量组合成一个向量表示;利用第一判别器与编码器之间构成第一对抗网络,通过对隐变量施加先验分布,采用对抗训练策略引导隐变量的先验分布和后验分布达到近似;利用解码器重构原始输入,得到重构结果;利用第二判别器与解码器之间构成第二对抗网络,用于对重构结果和原始输入之间施加对抗训练。由此将transformer模型很好地应用于时间序列异常检测,能够准确可靠地得到所有滑动窗口对应时间序列的重构取值。
68、三、本发明中,transformer模型中编码器包括特征注意力模块和时序注意力模块,利用特征注意力模块来学习时间序列的不同特征之间的相关性,利用时序注意力模块来学习时间序列内部的长短期依赖关系,能够充分有效地获取时间序列中不同特征之间的相关性以及时间序列中的长短期依赖关系,从而确保后续异常检测的准确性。
- 还没有人留言评论。精彩留言会获得点赞!