一种基于跨度边界表示的文本共指关系预测方法及系统
本发明涉及自然语言处理领域,具体涉及一种基于跨度边界表示的文本共指关系预测方法及系统。
背景技术:
1、共指消解在处理文本中重复出现的对同一个客体的引用,现已成为了自然语言处理研究的核心组成部分,作为自然语言处理领域应用的组件时,共指消解都会带来一个潜在的性能提升。
2、近年来共指消解特别是单先行词回指消解领域取得了非常大的进展,并且随着预训练模型的引入,共指消解的研究思路逐步打开,现已成为学术界研究的重点方向,并有向其他领域如对话系统、问答系统结合的趋向。但目前阶段关于指代关系的判断仍受限于预训练模型的时空复杂度以及指代特征的相对局部性。而现有的文本共指关系预测也因动态构建跨度表示将导致大量内存和显存的使用,并且存在因其体系结构缺陷导致的篇章级信息利用不足等问题。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种基于跨度边界表示的文本共指关系预测方法及系统,减少了计算量和因动态构建跨度表示而消耗的内存、显存,并能提升文本共指关系预测的准确性。
2、为了达到上述发明目的,本发明采用的技术方案为:
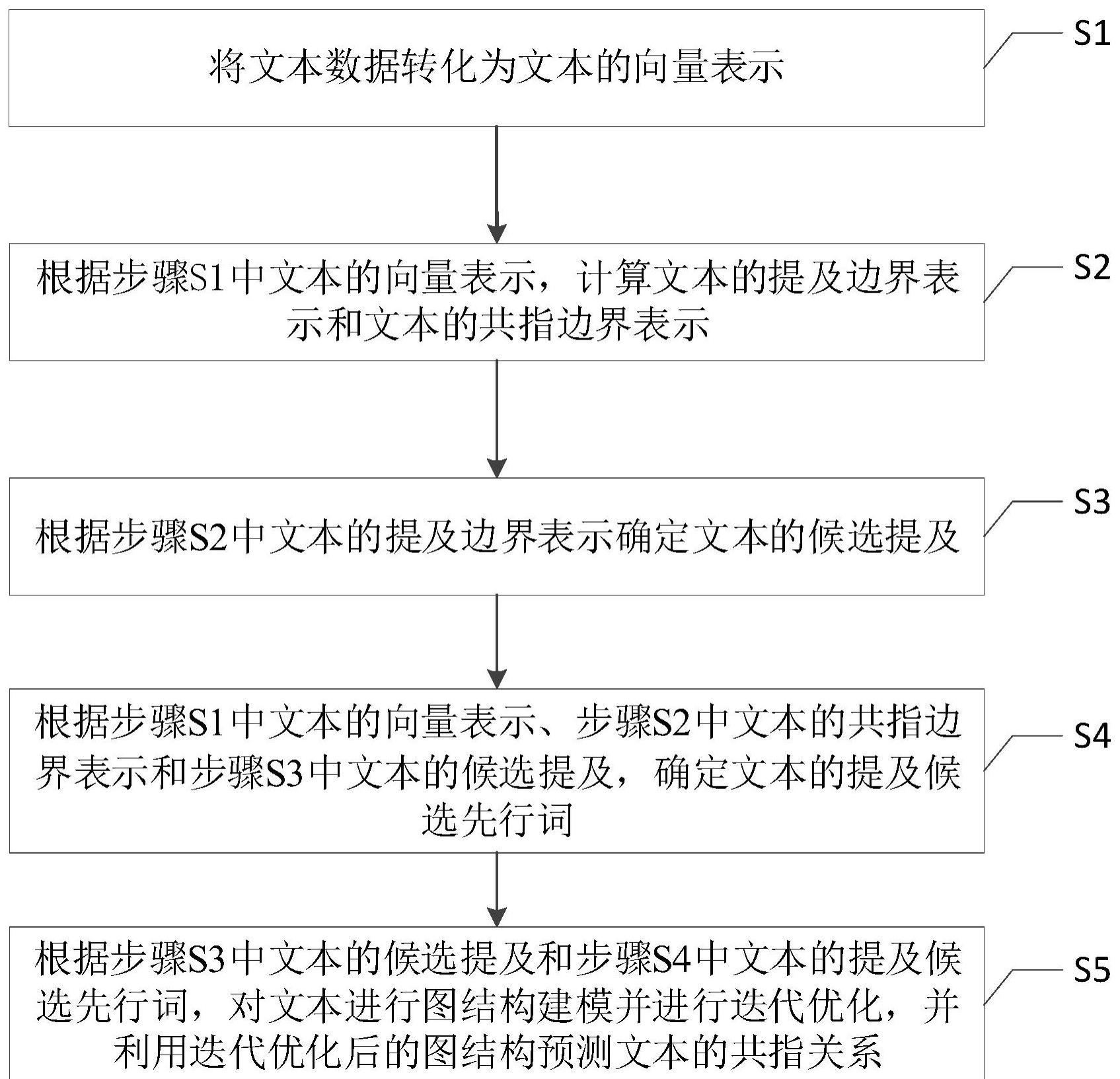
3、一种基于跨度边界表示的文本共指关系预测方法,包括以下步骤:
4、s1、将文本数据转化为文本的向量表示;
5、s2、根据步骤s1中文本的向量表示,计算文本的提及边界表示和文本的共指边界表示;
6、s3、根据步骤s2中文本的提及边界表示确定文本的候选提及;
7、s4、根据步骤s1中文本的向量表示、步骤s2中文本的共指边界表示和步骤s3中文本的候选提及,确定文本的提及候选先行词;
8、s5、根据步骤s3中文本的候选提及和步骤s4中文本的提及候选先行词,对文本进行图结构建模并进行迭代优化,并利用迭代优化后的图结构预测文本的共指关系。
9、进一步地,步骤s1包括以下分步骤:
10、s11、采用预训练的spanbert模型的分词器对文本进行分词;
11、s12、对预训练的spanbert模型预设单词词典,并采用预设的单词词典将分步骤s11中分词后分的文本转化为单词索引表示;
12、s13、采用预训练的spanbert模型对分步骤s12中的单词索引表示进行编码,得到文本的向量表示。
13、进一步地,步骤s2包括以下分步骤:
14、s21、根据步骤s1中文本的向量表示,计算文本的提及前边界表示,表示为:
15、ms=1x+b1
16、其中:ms为文本的提及前边界表示,m1为第一矩阵,x为文本的向量表示,b1为第一向量;
17、s22、根据步骤s1中文本的向量表示,计算文本的提及后边界表示,表示为:
18、me=2x+b2
19、其中:me为文本的提及后边界表示,m2为第二矩阵,b2为第二向量;
20、s23、根据步骤s1中文本的向量表示,计算文本的共指前边界表示,表示为:
21、as=m3x+b3
22、其中:as为文本的共指前边界表示,n3为第三矩阵,b3为第三向量;
23、s24、根据步骤s1中文本的向量表示,计算文本的共指后边界表示,表示为:
24、ae=m4x+b4
25、其中:ae为文本的共指后边界表示,m4为第四矩阵,b4为第四向量。
26、进一步地,步骤s3中包括以下分步骤:
27、s31、根据步骤s2中文本的提及边界表示计算文本中候选跨度的提及分数,表示为:
28、
29、其中:f’m(p)为文本中候选跨度p的提及分数,vs为用来评估文本中候选跨度p前边界的参数向量,为文本中候选跨度p的提及前边界表示,ve为用来评估文本中候选跨度p后边界的参数向量,为文本中候选跨度p的提及后边界表示,bm为用于评估文本中候选跨度p作为候选提及的参数矩阵;
30、s32、根据分步骤s31中的文本中候选跨度的提及分数和提及分数阈值,确定文本的候选提及。
31、进一步地,步骤s4包括以下分步骤:
32、s41、对步骤s3中文本的候选提及进行配对;
33、s42、确定分步骤s41中配对后文本的候选提及的提及分数;
34、s43、根据步骤s2中文本的共指边界表示,计算分步骤s41中配对后文本的候选提及共指的可能性,表示为:
35、
36、其中:fa(m,q)为配对后文本的候选提及m和文本的候选提及q共指的可能性,为文本的候选提及m的共指前边界表示,为第一参数矩阵,为文本的候选提及q的共指前边界表示,为第二参数矩阵,为文本的候选提及q的共指后边界表示,为文本的候选提及m的共指后边界表示,为第三参数矩阵,为第四参数矩阵;
37、s44、根据步骤s1中文本的向量表示,计算分步骤s41中配对后文本的候选提及的语义相似性,表示为:
38、
39、其中:fs(m,q)为配对后文本的候选提及m和文本的候选提及q的语义相似性,为向量和向量的拼接后的向量,为文本的候选提及m的前边界对应的向量表示,为文本的候选提及m的后边界对应的向量表示,为向量和向量的拼接运算,为文本的候选提及q的前边界对应的向量表示,为文本的候选提及q的后边界对应的向量表示,为向量的模长,为向量的模长;
40、s45、对分步骤s42中配对后文本的候选提及的提及分数、分步骤s43中配对后文本的候选提及共指的可能性和分步骤s43中配对后文本的候选提及的语义相似性进行求和,得到文本的共指分数,表示为:
41、f(m,q)=fm(m)+fm(q)+fa(m,q)+fs(m,q)
42、其中:f(m,q)为配对后文本的候选提及m和文本的候选提及q的共指分数,fm(m)为文本的候选提及m的提及分数,fm(q)为文本的候选提及q的提及分数;
43、s46、根据分步骤s45中文本的共指分数确定文本的提及候选先行词。
44、进一步地,步骤s41包括以下分步骤:
45、s411、将步骤s3中文本的候选提及按文本顺序进行排序,并确定排序后的第一个候选提及和最后一个候选提及;
46、s412、将分步骤s411中的第一个候选提及和最后一个候选提及进行配对。
47、进一步地,步骤s5包括以下分步骤:
48、s51、将文本中的token建模为节点,并根据步骤s3中文本的候选提及和步骤s4中文本的提及候选先行词将token之间的关系建模为边,对文本进行图结构建模,并构建文本的邻接关系矩阵;
49、s52、将分步骤s51中文本的邻接关系矩阵嵌入至transformer自注意力层,得到融合图结构的transformer模型;
50、s53、利用分步骤s52中融合图结构的transformer模型对图结构进行迭代优化,并利用迭代优化后的图结构预测文本的共指关系。
51、进一步地,在步骤s51中,token之间的关系包括提及关系和共指关系;提及关系建模具体为:将候选提及的最后一个token通过有向边连接第一个token;共指关系建模具体为:将候选提及的提及头通过有向边连接其提及候选先行词的提及头。
52、进一步地,嵌入文本的邻接关系矩阵的transformer自注意力层的计算模型,表示为:
53、
54、其中:attention(q,k,v,lk,lv)为嵌入文本的邻接关系矩阵的transformer自注意力层的计算模型,q为transformer的查询向量,k为transformer的键向量,v为transformer的值向量,lk=e(gt-1)·wk,e(gt-1)为嵌入的文本的邻接关系矩阵,wk为用于将矩阵e(gt-1)转化为键向量k的参数矩阵,lv=(gt-1)·wv,wv为用于将矩阵e(gt-1)转化为值向量v的参数矩阵,softmax为加权函数,t为转置符号,d为transformer隐向量的维度,v为transformer的值向量。
55、一种应用上述方法的基于跨度边界表示的文本共指关系预测系统,包括嵌入表示模块、跨度边界表示模块、提及评估模块、共指评估模块和迭代优化模块;
56、嵌入表示模块用于将文本转化为向量表示,并将文本的向量表示分别传输至跨度边界表示模块和共指评估模块;
57、跨度边界表示模块用于接收嵌入表示模块传输的文本的向量表示,计算文本的提及边界表示和文本的共指边界表示,将文本的提及边界表示传输至提及评估模块,并将文本的共指边界表示传输至共指评估模块;
58、提及评估模块用于接收跨度边界表示模块传输的文本的提及边界表示,根据文本的提及边界表示计算文本中候选跨度的提及分数,根据提及分数确定文本的候选提及,并将文本的候选提及分别传输至共指评估模块和迭代优化模块;
59、共指评估模块用于接收嵌入表示模块传输的文本的向量表示,接收跨度边界表示模块传输的文本的共指边界表示,接收提及评估模块传输的文本的候选提及,根据文本的向量表示、文本的共指边界表示和文本的候选提及计算候选提及的共指分数,根据候选提及的共指分数确定文本的提及候选先行词,并将文本的提及候选先行词传输至迭代优化模块;
60、迭代优化模块用于接收提及评估模块传输的文本的候选提及,接收共指评估模块传输的文本的提及候选先行词,根据文本的候选提及和文本的提及候选先行词对文本进行图结构建模并进行迭代优化,并利用迭代优化后的图结构预测文本的共指关系。
61、本发明的有益效果为:
62、(1)本发明使用文本的跨度边界表示即通过计算文本的提及边界表示和文本的共指边界表示,不需要构建文本的跨度表示,显著减少了计算量和因动态构建跨度表示而消耗的内存、显存;
63、(2)本发明设计了融合图结构的transformer模型,通过该模型将候选提及和提及候选先行词(即文本中的共指链接关系)以图结构进行建模,并基于历史预测结果对图结构进行迭代优化,因为该图结构是全局的即该图结构式针对整个文本构建,所以不会忽略掉文本中提及词之间的依赖关系,从而可以充分挖掘文本中的高阶信息,有效提升文本共指关系预测的准确性。
- 还没有人留言评论。精彩留言会获得点赞!