融合项目反应的时序卷积知识追踪方法
本发明属于智慧教育,教育数据,具体涉及知识追踪。
背景技术:
1、知识追踪是根据学生以往的答题情况对学生的知识掌握程度进行建模,从而得到学生当前知识状态并预测下一道题的做题情况的技术。作为精准推送、学生学习路径规划和知识图谱构建的首要任务,知识追踪是构建自适应教育系统的核心和关键。现有知识追踪方法存在的主要问题:(1)预测方法效率低、预测结果不精确;(2)预测过程和结果缺乏可解释性;(3)多针对习题对应的知识点建模,忽视了题目本身蕴含的丰富信息。因此,运用计算机技术结合题目知识点的信息探索出高预测性能,且具有系统透明度可解释的知识追踪方法,已经成为智慧教育领域的研究热点和挑战性课题。
2、当前知识追踪技术主要归纳为两类:基于传统机器学习方法和基于深度学习的方法。基于传统方法的知识追踪方法又分为基于概率和基于回归的知识追踪方法。其中,概率方法将学习者对每个知识点的掌握情况建模为一组二元变量,忽略了知识点之间的相互联系,难以处理较复杂的知识体系,且在实际应用中难以模拟较长的交互序列;回归方法通过从历史数据中学习特定参数从而对答题情况进行预测,具有较好的解释性,但是难以自动拓展到不同的数据中,且由于其本身的表示能力有限,因此预测性能欠佳。基于深度学习的知识追踪是目前知识追踪领域的主流方法,深度知识追踪模型首次将深度学习引入知识追踪领域,使用循环神经网络追踪学生的知识状态,该方法具有强大的表征能力,也在知识追踪任务取得了较好的预测结果。但由于循环神经网络自身特性,导致模型容易出现长序列依赖,梯度消失以及解释性不足的技术问题。在此基础上,一些知识追踪方法通过结合教育数据特征以及引入注意力机制进一步改进模型,提高模型预测能力。
技术实现思路
1、本发明所要解决的技术问题在于克服上述现有技术的缺点,提供一种预测准确度高、解释性的融合项目反应的时序卷积知识追踪方法。
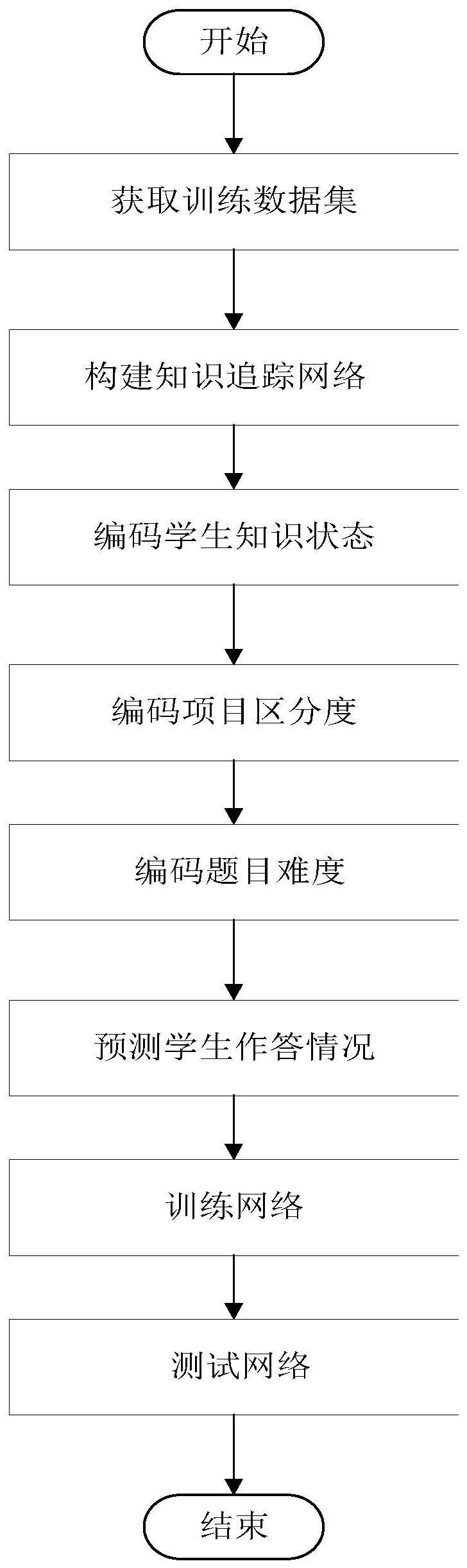
2、解决上述技术问题所采用的技术方案由下述步骤组成:
3、(1)获取训练数据集
4、在公共数据集assistment2009中选取答题数量大于3题的学生,分为训练集和测试集,训练集与测试集的比为4:1,学生的答题序列xt为:
5、xt=(x1,x2,...,xt) (1)
6、xt=(qt,at)
7、其中,qt为学生在时刻t的回答的题目信息,at为学生在时刻t回答问题的正确与否,t∈[4,200]。
8、(2)构建知识追踪网络
9、知识追踪网络由知识状态编码模块1与题目区分度编码模块2、题目难度编码模块3并联后,再与学生答题情况预测模块4串联构成。
10、所述知识状态编码模块1由时序卷积网络构成;所述的题目区分度编码模块2由深度神经网络dnn与全连接层1串联构成;所述的题目难度编码模块3由全连接层2构成;所述的学生答题情况预测模块4由全连接层3构成。
11、(3)编码学生知识状态
12、采用知识状态编码模块1对学生的知识状态进行编码,按式(2)编码生成学生知识状态ht:
13、
14、其中,xt-d(n-1)为t-d(n-1)时刻的输入值,wt-d(n-1)为神经元的权重,取值为有限正整数,d为膨胀系数、取值为21~29,k为卷积核大小、取值为5~8。
15、(4)编码题目区分度
16、采用题目区分度编码模块2对题目区分度进行编码,按式(3)确定题目区分度α:
17、α=sigmoid(wo×lt+bo) (3)
18、
19、
20、其中,ai为i时刻学生所有答题记录特征向量总和,xj为j时刻学生的答题信息,j表示该学生在i时刻之前的答题记录,j∈[4,200],i表示该学生在t时刻之前的答题记录,i∈[4,200],f为非线性激活函数,lt表示t时刻项目区分度特征向量,ws,wo为权重系数,s取值为50~200,bo为偏置系数,o取值为50~200,sigmoid为s型激活函数。
21、(5)编码题目难度
22、采用题目难度编码模块3对学生作答题目的难度进行编码,按式(4)确定题目难度β:
23、β=tanh(wp×dt+bp) (4)
24、dt=(qt,et,mt)
25、其中,wp为区分度权重系数,bp为偏置系数,p取值为50~200,tanh为双曲正切激活函数,dt表示学生在时刻t作答的题目难度特征向量,qt表示学生在时刻t的回答的题目信息,et表示学生在时刻t作答题目的类型,mt表示学生在时刻t的作答时间。
26、所述的类型包括单项选择、多项选择、填空题、计算题、应用题。
27、(6)预测学生作答情况
28、采用学生答题情况预测模块4预测学生的答题情况,按式(5)确定预测值yt:
29、
30、θ=sigmoid(wr×ht+br)
31、其中,θ表示学生在时刻t作答题目的能力,ht表示学生在时刻t的知识状态,wr为权重系数,br为偏置系数,r取值为有限正整数,sigmoid为s型激活函数,e值为2.718,d为常量、取值为1.7~1.74。
32、(7)训练网络
33、1)构建损失函数
34、按下式构建损失函数l:
35、
36、其中,n为交互序列长度,n取值为有限的正整数,yt为模型的预测值,at为学生在时刻t的真实回答值。
37、2)训练知识追踪网络
38、将训练集输入知识追踪网络,对知识追踪网络进行训练,在知识状态编码模块1,特征向量嵌入维度为100~300,时序卷积网络的通道数为200~300;在题目区分度编码模块2,特征向量嵌入维度为100~300,深度神经网络隐藏层的神经元个数为50~300,输出维度为1,进行特征融合的全连接网络fc层数为1;在题目难度编码模块3,题目知识点特征向量嵌入维度为50~150,题目类型特征向量嵌入维度为10~100;训练时每次送入知识追踪网络数据量为32,学习率为0.001;知识追踪网络通过对损失函数l进行反向传播,不断优化知识追踪网络中每个模块的权重参数,训练至损失函数l收敛。
39、(8)测试网络
40、将测试集输入训练后的知识追踪网络,逐一预测每个学生在每个时刻的答题情况,直至预测完测试集上所有学生的答题情况。
41、在本发明的步骤(2)构建知识追踪网络中,所述的时序卷积网络由因果膨胀卷积层与归一化层、非线性映射层、丢弃层依次串联后,与残差块并联构成。
42、本发明的因果膨胀卷积层深度为1~9,卷积核大小为7。
43、在本发明的步骤(2)构建知识追踪网络中,所述的深度神经网络dnn的特征向量嵌入维度最佳为200,神经元个数最佳为200,全连接层1、全连接层2、全连接层3的神经元个数为1。
44、在本发明的步骤(7)训练网络的2)步骤中,所述的在知识状态编码模块1,特征向量嵌入维度最佳为200,时序卷积网络的通道数最佳为246;在题目区分度编码模块2,特征向量嵌入维度最佳为200,深度神经网络隐藏层的神经元个数最佳为200,输出维度为1,进行特征融合的全连接网络fc层数为1;在题目难度编码模块3,题目知识点特征向量嵌入维度最佳为100,题目类型特征向量嵌入维度最佳为50;训练时每次送入知识追踪网络数据量为32,学习率为0.001;知识追踪网络通过对损失函数l进行反向传播,不断优化知识追踪网络中每个模块的权重参数,训练至损失函数l收敛。
45、在本发明的步骤(1)获取训练数据集中,所述的公共数据集assistment2009中选取答题数量大于3题的学生,分为训练集和测试集,训练集、测试集的比为4:1,学生的答题序列xt为:
46、xt=(x1,x2,...,xt) (1)
47、xt=(qt,at)
48、其中,qt为学生在时刻t的回答的题目信息,at为学生在时刻t回答问题的正确与否,t取值最佳为100。
49、本发明采用时序卷积网络对学生的交互序列进行特征提取以得到学生知识状态,在此基础上,进一步研究了学生和习题之间的互动关系,对学生答题情况进行预测,并从习题难度、项目区分度和用户个人能力这几方面为预测结果提供解释。本发明与现有技术相比,网络模型的预测准确率显著提升,能有效地避免循环神经网络存在的梯度消失的情况,对学生的作答过程有更加全面、准确的跟踪和解释。
- 还没有人留言评论。精彩留言会获得点赞!