一种数据校对方法、系统及存储介质与流程
本发明属于数据处理,具体涉及一种数据校对方法、系统及存储介质。
背景技术:
1、当前,无论是企业的办公数据,还是工厂中的生产数据,在其被事先打入数据标签的情况下,在之后的审核中均需要对数据标签进行校对,以防止其出现欺诈行为;例如在企业中,在办公文件数据提交后,需要根据预设规则对其进行审核,若文件数据符合预设规则,表明数据标签与文件数据对应,则审核通过该文件;又例如工厂中,当发生故障时,数据标签为故障原因,在进行审核校对是,通过获取设备的故障现象及故障参数,将其与预设规则进行校对,从而确定设备的故障原因是否与数据标签标注的原因一致;然而,在实际应用场景中,无论是办公文件数据、还是设备故障数据,其中均包含有数值数据和文本数据,现有技术中一般设置自动校对模块,在自动校对模块中输入预设的数据范围,通过确定接收到的实际数据在哪个数据范围内,以实现对文件数据的自动审核校对;但是,在实际应用中,接收到的数据一般包括数值数据和文本数据,例如设备的故障参数为数值数据,故障现象为文本数据,那么如何对文本数据进行审核校对,是本领域亟待解决的技术问题。
技术实现思路
1、为解决上述问题,本发明提供了一种数据校对方法、系统及存储介质,以实现对文本数据和数值数据的自动审核校对。
2、为了达到上述的发明目的,本发明提出一种数据校对方法,包括:
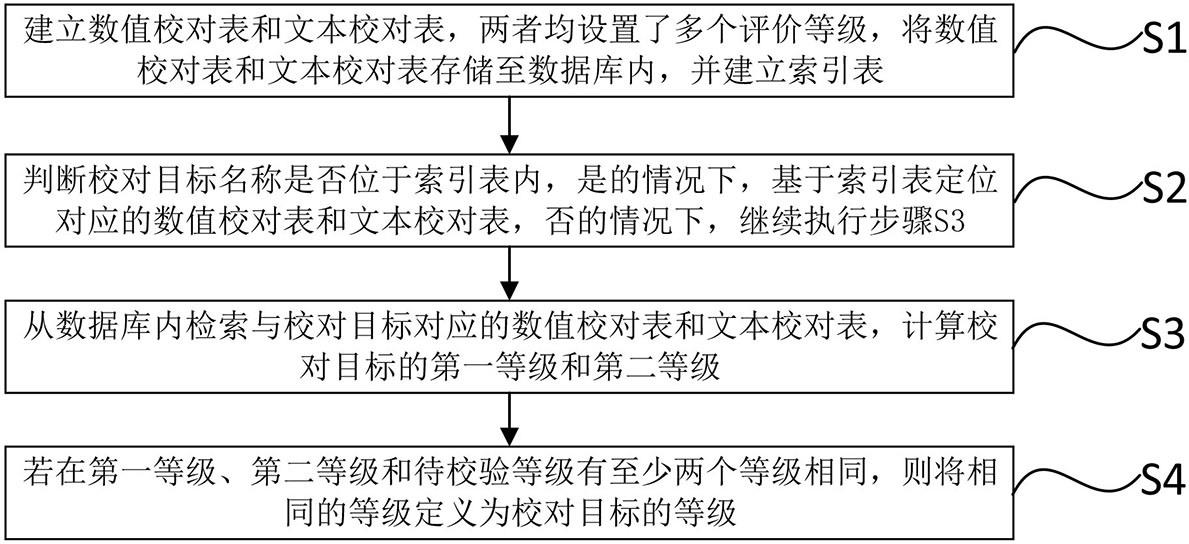
3、步骤s1:针对每个对象建立数值校对表和文本校对表,所述数值校对表和所述文本校对表内均设置了多个评价等级,所述数值校对表中每个所述评价等级对应多种数值数据的范围,所述文本校对表中每个所述评价等级对应一种第一文本数据,将不同所述对象的所述数值校对表和所述文本校对表存储至不同的数据库内,并建立指示所述数值校对表和所述文本校对表所在所述数据库位置的索引表;
4、步骤s2:确定需要审核的所述对象,定义为校对目标,判断所述校对目标的名称是否位于所述索引表内,是的情况下,基于所述索引表定位对应的所述数值校对表和所述文本校对表,否的情况下,继续执行步骤s3;
5、步骤s3:接收所述校对目标的属性数据和待校验等级,所述属性数据包括多个不同类型的数值数据和对所述校对目标描述的第二文本数据,从所述属性数据中抽取数值数据和所述第二文本数据,从所述数据库检索与所述校对目标相关联的所述数值校对表和所述文本校对表,基于所述校对目标的数值数据和所述数值校对表获得第一等级,基于第二文本数据和所述文本校对表获得第二等级;
6、步骤s4:若在所述第一等级、所述第二等级和所述待校验等级中,有至少两个等级相同,则将相同的等级定义为所述校对目标的等级,若三个等级均不相同,则将所述校对目标的所述属性数据和所述待校验等级存储至专家审核队列。
7、进一步的,所述步骤s3中,从所述数据库检索与所述校对目标相关联的所述数值校对表和所述文本校对表包括以下步骤:
8、步骤s31:为每个所述文本校对表中设置标签组,所述标签组包括多个第一特征关键词,抽取所述校对目标的所述第二文本数据,将所述第二文本数据逐字符拆分,获得多个单字符,统计各个所述单字符的出现次数,设置第一阈值,将出现次数大于等于所述第一阈值的所述单字符定义为第一字符;
9、步骤s32:以每个所述第一字符为起点,将所述第一字符与其前一个字符组成第一词组,将所述第一字符与其后一个字符组成第二词组,统计各个所述第一词组和所述第二词组的出现次数,设置第二阈值,将出现次数大于等于所述第二阈值的所述第一词组和第二词组保留;
10、步骤s33:以每个所述第一词组为起点,将所述第一词组与其相邻字符组成第三词组,若基于同一所述第一词组生成的所述第三词组相同,则将所述第三词组设置为第二特征关键词,若所述第三词组均不相同,则将所述第一词组设置为所述第二特征关键词,重复本步骤,基于所述第二词组生成第四词组,并从所述第四词组中选取所述第二特征关键词;
11、步骤s34:以每个所述第三词组起点,每个所述第四词组为起点,重复所述步骤s33继续进行扩展,设置第三阈值,当词组的字符长度达到所述第三阈值时停止扩展,获得多个不同字符长度的所述第二特征关键词,基于所述第二特征关键词生成检索次序表并进行检索,若存在所述标签组包括多个与其对应的所述第一特征关键词,则将所述标签组对应的文本校对表,以及与所述文本校对表对应的所述数值校对表作为检索结果。
12、进一步的,所述步骤s34中,生成所述检索次序表包括以下步骤:
13、统计各个所述第二特征关键词在所述第二文本数据中的出现次数,基于出现次数的大小,自上而下降将所述第二特征关键词排列为所述检索次序表;
14、定位所述检索次序表中包括四个字符的所述第二特征关键词,并抽取各个所述第二特征关键词中的首字符和尾字符,分别统计各个所述首字符和所述尾字符在所述第二特征关键词首端和尾端出现次数,设定第四阈值,若所述首字符出现次数大于所述第四阈值,则抽取包含该所述首字符所述第二特征关键词的前三个字符,定义为第一衍生词组,若所述尾字符出现次数大于所述第四阈值,则抽取包含该所述尾字符所述第二特征关键词的后三个字符,定义为第二衍生词组,将所述第一衍生词组和所述第二衍生词组添加至所述检索次序表内。
15、进一步的,在生成所述检索次序表后,基于以下步骤在所述数据库内进行检索:
16、从所述检索次序表中抽取第一次序的所述第二特征关键词,在所述数据库内进行检索,定义包含所述第二特征关键词的所述标签组,将检索出的所述标签组对应的所述文本校对表作为检索结果,继续从所述检索次序表中抽取第二次序的第二特征关键词在所述数据库内进行检索获得检索结果,重复此步骤,直至完成所述检索次序表中所有所述第二特征关键词的检索,抽取各个检索结果中,所述文本校对表对应的所述标签组,将所述标签组与所述检索次序表进行对比,将所述标签组中包含所述第二特征关键词最多的所述文本校对标准定义为最终检索结果。
17、进一步的,基于第二文本数据和所述文本校对表获得所述第二等级包括以下步骤:
18、建立语义对比模型,获取所述校对目标的所述待校验等级,基于所述待校验等级在所述文本校对表内搜索与其对应的所述第一文本数据,基于所述语义对比模型,将搜索出的所述第一文本数据与所述第二文本数据进行对比,获取两者的相似度,设定第五阈值,若所述相似度大于所述第五阈值,则将所述第二等级设置为所述第一文本数据对应的所述评价等级,若所述相似度低于所述第五阈值,则将所述校对目标传输至所述专家审核队列。
19、本发明还提供了一种数据校对系统,该系统用于实现上述所述的一种数据校对方法,该系统主要包括:
20、数据库模块,包括多个数据库,每个数据库内存储有不同对应的数值校对表和文本校对表,所述数值校对表和所述文本校对表内均设置了多个评价等级,所述数值校对表中每个所述评价等级对应多种数值数据的范围,所述文本校对表中每个所述评价等级对应一种第一文本数据;
21、判断模块,所述判断模块内设置有索引表,所述判断模块确定需要审核的所述对象,定义为校对目标,判断所述校对目标的名称是否位于所述索引表内,是的情况下,基于所述索引表定位对应的所述数值校对表和所述文本校对表;
22、等级生成模块,若所述校对目标的名称没有位于所述索引表内,则接收所述校对目标的属性数据和待校验等级,所述属性数据包括多个不同类型的数值数据和对所述校对目标描述的第二文本数据,从所述属性数据中抽取数值数据和所述第二文本数据,从所述数据库检索与所述校对目标相关联的所述数值校对表和所述文本校对表,基于所述校对目标的数值数据和所述数值校对表获得第一等级,基于第二文本数据和所述文本校对表获得第二等级;
23、校对模块,接收所述第一等级、所述第二等级和所述待校验等级,若在所述第一等级、所述第二等级和所述待校验等级中,有至少两个等级相同,则将相同的等级定义为所述校对目标的等级,若三个等级均不相同,则将所述校对目标的所述属性数据和所述待校验等级存储至专家审核队列;
24、本发明还提供一种计算机存储介质,所述计算机存储介质存储有程序指令,其中,在所述程序指令运行时控制所述计算机存储介质所在设备执行上述所述的一种数据校对方法。
25、与现有技术相比,本发明的有益效果至少如下所述:
26、本发明首先通过针对每个对象建立数值校对表和文本校对表,当接收到校对目标的数据中,从数据中抽取数值数据和文本数据,然后将数值数据与数值校对表中各个数值范围进行对比,从而获取校对目标的第一等级,将文本数据与文本校对表中各个描述文本进行对比,从而获取校对目标的第二等级,之后,将校对目标的待校验等级、第一等级和第二等级进行核对,一方面,可以较为可靠的确定校对目标所处的等级,另一方面,由于待校验等级为基于人工进行判断,因此通过第一等级和第二等级对待校验等级进行校核,可以避免人工判断错误,或者人工故意设置错误待校验等级的欺诈行为。
27、本发明通过设置多个数据库,将同种类型的对象存储至不同的数据库内,之后建立索引表进行索引,在校对目标名称完整时,可以基于索引表索引,当校对目标不完整时,可以基于对应的类型只在一个数据库内进行检索,从而提升了数据的检索效率。
- 还没有人留言评论。精彩留言会获得点赞!