一种基于SECA的多尺度网络及其训练方法
本发明属于人工智能中的深度学习和计算机视觉,更具体地,涉及一种基于加强风格交叉注意力(style enhanced crossattention,简称seca)的多尺度网络及其训练方法。
背景技术:
1、风格迁移的目标是将图片以给定的风格渲染出来同时保持其原来的内容结构不变,其在艺术领域有很大的意义。
2、关于任意风格迁移的研究成果可以归为几类,第一类方法是基于全局转换的方法,旨在全局修改特征以达到期望的风格迁移效果,其中一个具有代表性和突破性的工作是adain,它通过自适应地将样式特征的均值和方差应用于内容特征进行重新缩放。其他方法如wct,其利用白化和着色两个转换步骤;linear,它分别根据内容和样式特征生成线性变换来实现全局样式的迁移;第二类方法是基于局部转换的方法,如style-swap,其利用内容和样式补丁之间的相似性来实现样式化;
3、然而,上述两种方法都存在一些缺陷:基于全局转换的方法虽然在任意风格迁移领域取得了重大进展,但它们通常难以保留局部信息;基于局部转换的方法虽然有效地保留了局部信息,但可能会导致视觉伪影。
4、为了解决上述两种方法的问题,人们研究出了基于注意力机制的方法,相较于之前的两类工作可以更好的建模样式和内容图像的局部特征之间的细粒度对应关系,park等人提出了风格注意力网络(style-attentional network)来匹配内容和样式特征,deng等人提出了自适应地分离内容和风格表示,然后通过注意力机制计算内容表示和风格表示之间的相似性来重新排列风格表示的分布,liu等人提出了一个新的模块adaattn,通过对每个像素点进行自适应注意力规范化,同时融合不同网络层次的统计信息,实现了很好的效果。aesust通过引入美学辨别器(aesthetic discriminator)和新颖的美学风格注意力(aesthetic-aware style-attention)模块,能够生成更具美学感和真实感的任意样式转移结果,进一步提高了样式迁移的性能。
5、然而,上述基于注意力机制的方法仍然存在一些不可忽略的缺陷:其风格化程度不够,风格图片中的很多样式没有出现在结果图片,导致图片中的变化较少,画面看起来比较单调,笔触感不够。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种基于seca的多尺度网络及其训练方法。其目的在于,解决现有基于深度学习的风格迁移方法由于风格化程度不够,风格图片中的很多样式没有出现在结果图片,导致图片中的变化较少、画面看起来比较单调、笔触感不够的技术问题。
2、为实现上述目的,按照本发明的一个方面,提供了一种基于seca的多尺度网络,其网络结构如下:
3、第1层为编码器层,其采用了预训练的vgg19模型中从开始到relu5_1的部分,其使用vgg模型的不同激活层特征的策略,即分别使用vgg19的relu4_1和relu5_1输出的特征分别通过transform之后再进行融合,输入为3*h*w的的矩阵,最后输出大小为512*h/16*w/16、内容特征和风格特征的的隐藏向量,其中h表示输入图像的高度,w表示输入图像的宽度。
4、第2层为转换层,其包含n个seca模块,其中n表示不同大小风格图片的个数,输入为第1层输出的内容特征和风格特征的的隐藏向量,各个seca模块接受不同大小的风格特征和同样大小的内容特征,输出不同高度和宽度的特征,然后通过向上缩放特征(upscale)的操作将这些特征缩放到相同的高度和宽度,再融合起来。再结合multi_level的策略,将不同层的特征向量分别通过转换后,经过一个融合层把不同层的风格化特征结合起来,最终输出512*h/16*w/16的风格化特征向量。
5、第3层是解码器层,它的网络结构是第2层的镜像,输入为第二层输出的512*h/16*w/16的风格化特征向量,最终输出3*h*w的矩阵。
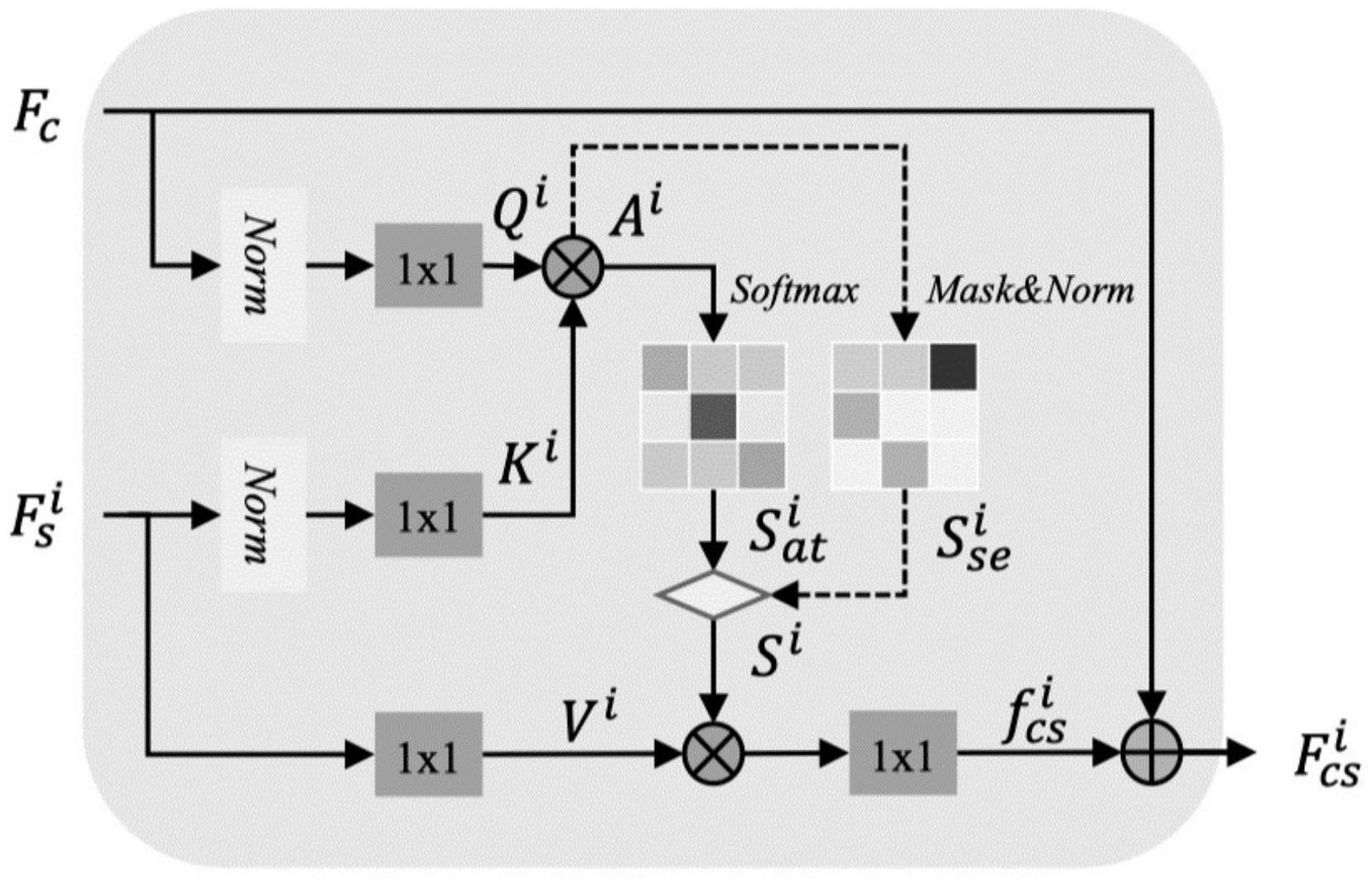
6、优选地,seca模块的网络结构如下:
7、第1层,输入为内容图片的特征矩阵和风格图片的特征矩阵,输出q,k,v三个特征矩阵;
8、第2层,输入为第1层输出的的特征矩阵q和,对其做矩阵乘法,输出注意力分数图a;
9、第3层,输入为第2层输出的注意力分数图a,对其进行归一化指数函数操作,以得到注意力权重图并输出;
10、第4层,输入为第3层得到的注意力权重图和第1层得到的特征矩阵,对和在空间上进行加权平均,以得到风格特征fcs并输出;
11、第5层,输入为第2层输出的注意力分数图a,选出每个风格特征最相关的内容特征ms-c并输出;
12、第6层,输入为第2层输出的注意力分数图a,对第2层输出的注意力分数图a进行mask处理,仅保留第5层输出的内容特征ms-c,即注意力分数图a中每列的最大值,并把a中除最大值之外的其他值设置为极小的负数,输出为()mask;
13、第7层,输入为第6层输出的()mask,对()mask进行norm操作,以得到风格增强注意力图sse并输出;
14、第8层,输入为第7层输出的的风格增强注意力图sse和第3层输出的注意力权重图,对sse和进行混合,以得到新的注意力权重图并输出。
15、第9层,输入为第8层输出的新的注意力权重图,对新的注意力权重图加权平均样式特征,以得到最终的输出。
16、优选地,第一层是采用以下公式:
17、q=f(norm(fc))
18、k=g(norm())
19、v=h()
20、其中f(.),g(.),h(.)分别代表的是可学习的1x1卷积,norm代表的是逐通道均值-方差标准化,fc表示经过编码器层后内容图片的特征矩阵,表示经过编码器层后风格图片的特征矩阵。
21、第四层是采用以下公式:
22、
23、其中o(.)代表1x1卷积。
24、第五层是采用以下公式:
25、ms-c=max(,dim=-2)
26、其中dim表示注意力分数图a特征的维数。
27、第六层是采用以下公式:
28、()mask=mask(,ms-c)
29、其中mask操作表示保留原始注意力分数图a中的部分值而把剩下的值设置为极小的负数。
30、第七层是采用以下公式:
31、sse=norm(()mask,dim=-1)
32、其中norm操作代表一种归一化操作。
33、第八层是采用以下公式:
34、=γ(α+βsse)
35、其中α,β代表注意力权重图和风格增强注意力图sse各自的混合比例,γ表示调整整体的强度,其中γ>0。
36、按照本发明的另一方面,提供了一种基于seca的多尺度网络的训练方法,包括以下步骤:
37、(1)获取ms-coco作为内容图片数据集,获取wikiart作为风格图片数据集,并按照8:2的比例将内容图片数据集划分为内容图片训练集和内容图片测试集,按照8:2的比例将风格图片数据集划分为风格图片训练集和风格图片测试集;
38、(2)将步骤(1)得到的内容图片训练集和风格图片训练集输入基于seca的多尺度网络中,并使用反向传播算法对基于seca的多尺度网络中每层的权重参数和偏置参数进行更新和优化,以得到训练好的基于seca的多尺度网络。
39、优选地,步骤(2)包括以下子步骤:
40、(2-1)将步骤(1)得到的内容图片训练集和风格图片训练集输入基于seca的多尺度网络中,以得到内容图片,风格图片和不同尺度风格图片1,2,...;其中n表示风格图片训练集中每张风格图片不同尺度风格图片的数量;
41、(2-2)对(2-1)输出的内容图片和不同尺度的风格图片1,2,...进行vgg编码,以得到内容特征和不同尺度的风格特征1,2,...;
42、(2-3)将(2-2)得到的内容特征和不同尺度的风格特征1,2,...分别输入seca模块,以得到n个不同尺度的风格特征
43、(2-4)将(2-3)得到的不同尺度的风格特征输入基于seca的多尺度网络中的转换层进行混合,以得到最终的风格化特征;
44、(2-5)将(2-4)得到的最终的风格化特征输入基于seca的多尺度网络的解码器层,以获取风格转换后的图片;
45、(2-6)基于(2-1)得到的内容图片和风格图片、以及步骤(2-5)风格转换过的图片,对训练过程中的总损失函数进行反向传播,以优化基于seca的多尺度网络的参数,并得到训练好的基于seca的多尺度网络。
46、优选地,总损失函数为:
47、
48、其中λ1、λ2、λ3、λ4均为大于0的权重系数;表示全局的内容损失,表示全局的风格损失,ladv表示对抗损失,lid表示身份损失。
49、优选地,全局的内容损失lcontent等于:
50、
51、全局的风格损失lstyle等于:
52、
53、其中φi(.)表示vgg encoder的第i个激活层输出,计算全局内容损失时使用relu4 1,relu5 1层,计算全局内容损失时使用relu1 1,relu2 1,relu31,relu4 1,relu51层,μ()表示对特征取均值,σ()表示对特征取方差,和分别代表内容图片训练集和风格图片训练集中图片的个数。
54、优选地,对抗损失ladv的计算方式如下:
55、
56、其中d表示辨别器网络,g表示基于seca的多尺度网络,指的是内容图片数据集的图片,指的是风格图片数据集中n个不同尺度的图片,e()表示对内容求期望。
57、优选地,身份损失lid的计算公式如下:
58、
59、其中icc和iss分别表示将内容特征fc和未经缩放的风格特征fs直接通过基于seca的多尺度网络中的解码器层获得的图片。
60、总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
61、(1)本发明由于采用了seca模块,其对原本交叉注意力模块得到输出特征进一步的进行了额外的特征后处理操作,因此使结果图片风格化程度增加;
62、(2)本发明提供的seca模块具有较强的通用性,之前很多基于交叉注意力模块已经训练好的模型,可以直接把交叉注意力模块换成我们的seca模块,其风格转换效果就可以得到提升。seca模块没有使用额外的训练参数,替换后也不需要额外的训练。
63、(3)本发明由于采用了步骤(2-4),其通过缩放得到不同尺度的风格图片再各自经过编码器得到不同尺度的风格特征,然后这些风格特征和正常尺度的内容特征在seca模块中混合得到不同尺度的风格化后的结果,最后把这些风格化特征融合起来,因此让基于seca的多尺度网络输出的图片变化更丰富,笔触感更强。
- 还没有人留言评论。精彩留言会获得点赞!