基于关系注意力增强和词性掩码的实体关系联合抽取方法
本发明涉及信息抽取,特别是涉及一种基于关系注意力增强和词性掩码的实体关系联合抽取方法。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、随着互联网的快速发展,互联网用户在享受网上冲浪乐趣的同时也产生了庞大的非结构化数据。这些数据中包含大量文本内容,蕴含丰富的语义信息,想要充分利用这些语义信息,就需要对这些非结构化文本进行知识提取。
3、为了从自由文本等非结构化数据中抽取出计算机可以理解的结构化语义信息,人们提出了信息抽取技术。信息抽取技术主要包括命名实体识别、关系抽取、事件抽取等子任务。其中命名实体识别和关系抽取是信息检索、知识图谱构建等任务的基础,命名实体识别主要是识别文本中特定的实体,如人名、地名、组织名等;关系抽取主要是识别实体之间的关系,如人和公司之间的从属关系、家庭成员关系等。实体与关系抽取任务则包含上述两个子任务,主要目的是抽取自然语言文本中存在的实体对和实体对之间存在的关系类型,并以(头实体h;关系r;尾实体t)三元组的形式表示。
4、深度学习方法能够自动从文本中学习语义特征,不需要构建大量的特征工程,目前其相关技术已经被广泛引用到了计算机视觉与自然语言处理等任务中。实体与关系抽取任务中也涌现了很多基于深度学习的抽取方法,这些方法大致可以分为两类:基于流水线的方法与联合抽取的方法。
5、基于流水线的实体关系抽取方法是实体抽取与关系分类彼此独立,或者线性关联,结构简单、调试方便;但是实体抽取与关系分类相对独立,忽视两个任务间的关联性,而关系分类往往基于实体抽取结果,误差累计问题明显。
6、针对流水线方法存在的问题,研究人员提出联合抽取模式,即实体关系联合抽取方法,是指在一个模型中同时训练实体识别与关系抽取两个子任务,实体识别和关系抽取共享同一个词向量表示及权重参数,两个任务互相联系促进,最后输出实体与关系三元组。虽然这种方式的模型相对复杂,但是可以有效的考虑实体与关系之间的相关性,可以缓解累计误差问题。但是仍存在一些问题:
7、(1)现有模型只考虑实体对关系抽取的促进作用,而忽略关系对实体抽取的反作用,没有充分利用实体抽取与关系抽取两个子任务之间的相互作用;例如:已知关系“出生于”,就可以推断头实体和尾实体分别为人和地点实体。
8、(2)词语的词性与词语是否为一个实体也存在一定的相关性;例如,表示实体的词一定倾向于是一个名词,而现有模型并未考虑词语词性对实体抽取的作用,限制实体抽取子任务的精度。
技术实现思路
1、为了解决上述问题,本发明提出了一种基于关系注意力增强和词性掩码的实体关系联合抽取方法,在考虑实体对关系抽取作用的同时,兼顾关系对实体抽取的辅助作用,同时引入词性信息,提高对实体抽取的准确度。
2、为了实现上述目的,本发明采用如下技术方案:
3、第一方面,本发明提供一种基于关系注意力增强和词性掩码的实体关系联合抽取方法,包括:
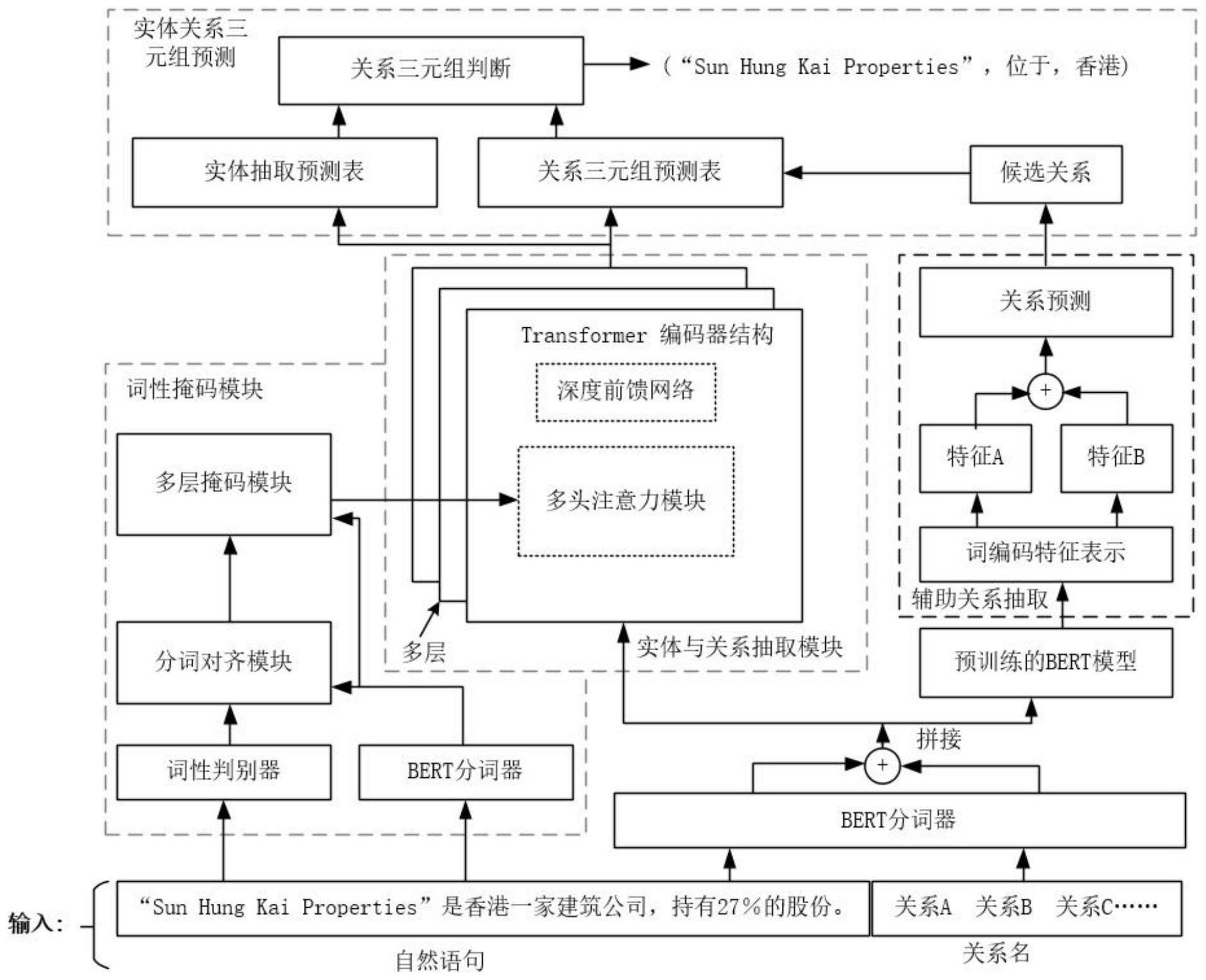
4、对待处理的自然语句和关系名序列分别进行分词后,得到句子分词标记和关系分词标记,将句子分词标记和关系分词标记拼接得到分词标记序列;
5、提取分词标记序列的词编码特征,根据词编码特征进行关系预测,得到候选关系列表;
6、对自然语句进行词性标注,将得到的词性标注序列和句子分词标记对齐后得到词性对齐序列,根据词性对齐序列生成多层掩码;
7、对分词标记序列采用多层transformer编码器进行处理,在每层transformer编码器的多头注意力处理中引入多层掩码,由此得到多层注意力矩阵,将多层注意力矩阵划分为实体抽取预测表和关系三元组预测表;
8、根据实体抽取预测表与设定阈值的比较得到实体抽取结果,根据候选关系列表对关系三元组预测表中不存在的关系删除后,通过与设定阈值的比较得到关系三元组预测结果,将实体抽取结果和关系三元组预测结果整合得到实体关系三元组。
9、作为可选择的实施方式,根据词编码特征进行关系预测的过程中,以首编码特征作为序列整体特征,以其余编码特征的均值作为序列局部特征,通过序列整体特征和序列局部特征进行关系预测;其中,关系预测包含2个全连接层和2个激活函数层,选择得分最高的k个关系类别作为候选关系列表。
10、作为可选择的实施方式,所述多层掩码包括词性掩码和句子分词掩码。
11、作为可选择的实施方式,每层transformer编码器包括多头注意力模块和深度前馈网络,将分词标记序列转换为连续向量,输入transformer编码器中,先通过引入多层掩码的多头注意力模块,将多头注意力模块的输出和连续向量相加后,再通过深度前馈网络得到该层transformer编码器的输出。
12、作为可选择的实施方式,所述实体抽取预测表为多层注意力矩阵中前n层注意力矩阵并求均值得到的用于实体抽取的抽取矩阵;实体抽取过程中,根据实体的头坐标和尾坐标进行判断,且不考虑抽取矩阵中坐标大于ml的元素和对角线下的元素,ml为句子分词标记长度。
13、作为可选择的实施方式,所述关系三元组预测表为多层注意力矩阵中剩余层的注意力矩阵并求均值得到用于关系三元组预测的预测矩阵;关系三元组预测过程中,根据头实体的头、尾实体的头和关系类别进行判断。
14、作为可选择的实施方式,将实体抽取结果和关系三元组预测结果整合的过程为,当[ts,te,ri]是三元组且存在两个以ts,te为头的实体,才为最终的实体关系三元组;其中,ts,te,ri分别表示头实体的头、尾实体的头以及关系类别。
15、第二方面,本发明提供一种基于关系注意力增强和词性掩码的实体关系联合抽取系统,包括:
16、预处理模块,被配置为对待处理的自然语句和关系名序列分别进行分词后,得到句子分词标记和关系分词标记,将句子分词标记和关系分词标记拼接得到分词标记序列;
17、辅助关系抽取模块,被配置为提取分词标记序列的词编码特征,根据词编码特征进行关系预测,得到候选关系列表;
18、词性掩码提取模块,被配置为对自然语句进行词性标注,将得到的词性标注序列和句子分词标记对齐后得到词性对齐序列,根据词性对齐序列生成多层掩码;
19、实体关系抽取模块,被配置为对分词标记序列采用多层transformer编码器进行处理,在每层transformer编码器的多头注意力处理中引入多层掩码,由此得到多层注意力矩阵,将多层注意力矩阵划分为实体抽取预测表和关系三元组预测表;
20、实体关系三元组预测模块,被配置为根据实体抽取预测表与设定阈值的比较得到实体抽取结果,根据候选关系列表对关系三元组预测表中不存在的关系删除后,通过与设定阈值的比较得到关系三元组预测结果,将实体抽取结果和关系三元组预测结果整合得到实体关系三元组。
21、第三方面,本发明提供一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成第一方面所述的方法。
22、第四方面,本发明提供一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成第一方面所述的方法。
23、与现有技术相比,本发明的有益效果为:
24、本发明提出一种基于关系注意力增强和词性掩码的实体关系联合抽取方法,先通过分词器和词性判别器对输入文本进行分词和单词词性的判断,再通过构建多层词性掩码将词性信息引入到实体关系抽取过程中,同时进行候选关系预测,增强对文本隐含关系的提取能力,最后通过结合实体关系抽取和关系预测信息得到最终的实体关系三元组。在考虑实体对关系抽取作用的同时,兼顾关系对实体抽取的辅助作用,充分实现两个子任务的交互,同时引入词性信息,在一定程度上考虑词性对实体抽取的影响。
25、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!