基于改进YOLOv7的密集行人检测方法、装置及设备
本发明涉及图像处理领域,主要涉及一种基于改进yolov7的密集行人检测方法及系统。
背景技术:
1、行人检测在辅助自动驾驶、车辆监控系统和安防预警系统等多个领域扮演者重要角色目前的行人检测算法在实际大规模拥挤场景应用过程中,仍然存在着由于行人间相互遮挡、交叠以及背景干扰而导致的误检率、漏检率较高的问题,许多学者基于深度学习理论提出了不同措施以提高算法的性能解决密集行人检测的漏检、误检等问题。
2、如公开号为cn112464770a的中国专利文献公开了一种在复杂场景下的密集行人检测方法,包括监控设备采集行人图像;网络提取关键帧并将图片传输到msr算法进行图片增强处理;利用yolov3卷积神经网络模型对获取的行人图像进行检测识别。该方法通过对现有的基于yolov3的卷积神经网络模型与msr算法相结合,实现对复杂环境下的密集行人检测。
3、如公开号为cn115797970a的中国专利文献公开了一种基于yolov5模型的密集行人目标检测方法,包括行人数据采集;数据增强对对数据集进行数据预处理;主干网络嵌入坐标注意力机制;使用diou-nms基于距离交并比的非极大值抑制算法替换原yolov5模型中的nms非极大值抑制算法;引入focalloss损失函数增大困难样本的损失权重;实现提升模型泛化力且能解决因密集行人造成的错检漏检问题。
4、但是现有专利并不能完全解决密集行人检测由于行人间相互遮挡、交叠以及背景干扰而导致的误检率、漏检率较高的问题,密集行人检测领域仍有很大的发展空间。随着硬件计算能力的提升和深度学习的发展,密集行人检测的准确性和鲁棒性将会进一步得到提升。
技术实现思路
1、本发明提供一种基于改进yolov7的密集行人检测方法及装置,以解决在行人密集情况下出现的行人间遮挡,背景干扰,网络特征提取能力不足导致检测精度低、误检率和漏检率高的问题。
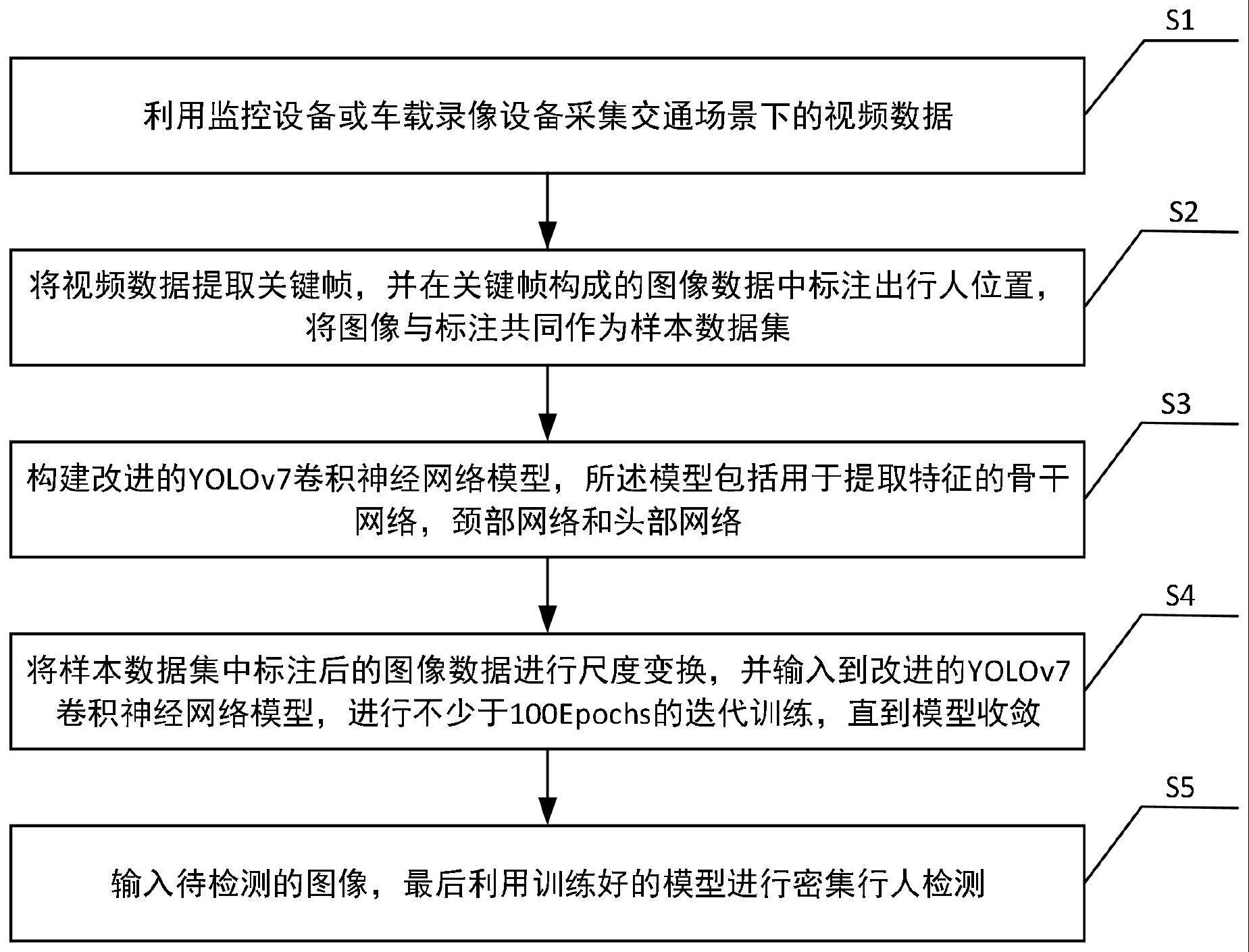
2、为解决上述技术问题,本发明提供一种基于改进yolov7的密集行人检测方法,包括:
3、s1,利用监控设备或车载录像设备采集交通场景下的视频数据;
4、s2,将视频数据提取关键帧,并在关键帧构成的图像数据中标注出行人位置,将图像与标注共同作为样本数据集;
5、s3,构建改进的yolov7卷积神经网络模型,所述模型包括用于提取特征的骨干网络、颈部网络和头部网络;
6、s4,将样本数据集中标注后的图像数据进行尺度变换,并输入到改进的yolov7卷积神经网络模型,进行不少于100epochs的迭代训练,直到模型收敛;
7、s5,输入待检测的图像,利用训练好的模型进行密集行人检测。
8、可选地,所述视频数据采集包括:
9、采集交通场景下的密集人流视频
10、可选地,所述数据集整理包括:
11、采用人工手动标注,整理好的数据集划分为训练验证数据集和测试集。
12、可选地,所述改进的yolov7卷积神经网络模型具体改进方法包括:
13、将全维动态卷积(omni-dimensional dynamic convolution-odconv)嵌入到yolov7的主干模块中,使模型能够更好地捕获行人的特征信息,并在各个检测头嵌入simam注意力模块使网络可以更好地处理复杂场景和避免产生噪声以更好的提取特征。
14、可选地,所述图像数据进行尺度变换包括:
15、使用裁剪的方式对标注后的数据图像进行尺度变换,将图像裁剪为固定的大小,同时根据标注的目标框信息来确定裁剪的位置和大小并保证行人完整地包含在裁剪后的图像中。
16、可选地,所述模型训练包括:
17、采用尺度变换后的数据集进行模型训练,同时采用k-means++均值聚类对数据集的行人标注框进行聚类,可以有效避免k-means聚类方法中由于初始中心点的不同容易陷入局部最优解的风险,参数初始化使用所采用目标检测模型的官方预训练权重进行初始化。
18、可选地,所述全维动态卷积(omni-dimensional dynamic convolution-odconv)包括:
19、全维动态卷积(omni-dimensional dynamic convolution-odconv)利用一种多维注意机制和并行策略,沿核空间的所有四个维度学习卷积核在任意卷积层上的互补注意,这四种不同的注意点分别是卷积核的输入通道数、卷积核本身的感知场、卷积核的输出通道数和卷积核的数量。这四个注意点是相互补充的,并按照位置、通道、滤波器、核的顺序与卷积核相乘,使得卷积操作不同于输入x的所有空间位置、所有输入通道、所有滤波器和所有核,显著增强上下文信息的捕获。其中odconv的输出可表示为公式(1):
20、output(y)=x*(αw1⊙αf1⊙αc1⊙αs1⊙w1+…+αwn⊙αfn⊙αcn⊙αsn⊙wn) (1)
21、其中,y和x分别表示输出特征和输入特征;αwi,αfi,αci,αsi(i=1,2,…,n)表是四个注意点:卷积核wi(i=1,2,…,n)的标量、空间维数,输入通道数,输出通道数。⊙表示核空间沿不同空间维数的逐元素乘积运算。
22、可选地,所述simam注意力模块包括:
23、simam注意力模块是一种基于相似度的自适应边界学习方法,主要用于增强特征的可区分性,通过自适应调整分类器的边界值,实现对特征间相似度的判别,提高特征的可区分性,降低同类别样本的漏检率。simam注意力模块通过测量目标神经元和其他神经元之间的线性可微分性,基于零域抑制的思想来评估每个神经元的重要性。因此,对每个神经元定义如下能量函数,如下公式(2):
24、
25、其中,t和xi分别为输入特征通道中的目标神经元和其他神经元。下标i表示被标注的变量是空间维度上第i维的变量,m表示该通道上的神经元总数。和是t和xi的线性变换形式,wt和xi是线性变换后的权重项和偏置项。yt和y0使用二进制标签,即1和-1。在公式(2)中加入一个正则化项,得到的能量函数为公式(3):
26、
27、其中,c=(1-(wtxi+bt))2+λwt2。
28、上式(3)中的wt和bt可由下式(4)和(5)求解:
29、
30、
31、其中,和分别是除目标神经元t外所选通道中所有神经元的均值和方差。因此,最小能量公式如下式(6):
32、
33、由最小能量公式(6)可知,神经元t的能量越低,与周围神经元的区别越大,其重要性越大。可以在不增加网络参数的情况下提高网络行人特征的提取能力。
34、基于同样的发明构思,本发明还提供一种基于改进yolov7的密集行人检测装置,包括:
35、图像采集模块,用于采集所需的图像、视频数据;
36、图像预处理模块,用于得到训练所需的训练验证数据集和测试集;
37、图像获取模块,用于获取密集行人待检测图像;
38、特征提取模块,用于使用改进的yolov7网络提取图像的特征;
39、模型训练模块,用于将所述处理后的数据集作为网络模型的输入,对所述网络模型进行训练;
40、图像检测模块,用于使用所述训练后的网络模型,对图像进行密集行人检测。
41、所述存储器用于存储至少一个计算机程序,所述处理器用于调用所述存储器中的至少一个所述计算机程序,以实现如上所述的基于改进yolov7的密集行人检测方法。
42、本发明的有益效果在于:
43、本发明提供的基于改进yolov7的密集行人检测方法及装置,通过全维动态卷积(odconv)利用多维注意机制和并行策略来学习卷积核在核空间的任意卷积层上的互补注意取代传统的“即插即用”的静态卷积,根据不同输入的密集行人图像数据自适应调整卷积核,有针对性地提取密集行人情况下的行人有效特征,提高了模型的特征提取能力,增强了网络的学习能力,解决了密集行人检测时静态卷积特征的学习能力受限问题;采用k-means++均值聚类对数据集的行人标注框进行聚类避免k-means聚类方法中由于初始中心点的不同容易陷入局部最优解的风险;使用simam注意机制抑制行人背景干扰信息,使模型更加关注行人的特征信息。
- 还没有人留言评论。精彩留言会获得点赞!