基于多池优先经验回放的强化学习网络训练方法及装置
本发明涉及强化学习训练领域,具体涉及一种基于多池优先经验回放的强化学习网络训练方法及装置。
背景技术:
1、强化学习(reinforcement learning,rl)是一种智能体以试错的方式探索其在环境中最佳策略的技术,其目标是最大化一场游戏的累计奖励。作为人工智能领域的关键技术之一,强化学习算法由于在很多工程问题上都具有潜在的适用性,可以广泛应用在诸如自动驾驶(autonomous vehicles)、机器博弈(computer games)、机器人(robotics)等领域。
2、在早期的强化学习网络的训练过程中,智能体使用与环境单次交互得到的经验来更新其模型,这意味着在一次更新后这些交互信息将会被丢弃,进而导致两个问题:(1)获得的经验具有很强的时间相关性,这不利于模型的训练;(2)快速丢弃的交互信息可能是对以后有用的罕见经验。因此充分利用历史经验对模型的收敛尤为重要。经验回放机制能够很好地解决了这两个问题,它将智能体与环境交互得到的经验存储在经验回放池中,智能体可以根据这些混合了先前存放的经验和近期获得的经验来更新模型。一方面,这种机制解决了训练数据之间存在时间关联性的问题;另一方面,一些重要的经验也会被多次用来更新模型,这有效提高了智能体的学习效率。
3、最近许多工作都证明了在强化学习网络的训练过程中引入经验回放的必要性。dqn算法通过使用经验回放机制来稳定由深度神经网络表示的值函数的训练。ddpg算法也采用经验回放机制,即通过探索策略从环境中采样状态转移样本,并将样本存储到经验回放池中,每次更新时从该经验回放池中采样小批量样本,这样可以减少智能体与环境的交互次数。
4、尽管上述的强化学习网络都能够有效地探索环境的最优策略,然而它们都采用了均匀采样的方式,即不考虑样本的重要性程度,使得样本被采样到的概率都是相同的。而且在传统的强化学习方法中,优先经验回放有效加速了训练速度,但在异步强化学习环境下,优先经验回放还有待研究。直观地,把传统的非异步优先经验回放机制应用在异步强化学习中,有两种方式:(1)每个智能体都有各自的经验回放池,并在各自的经验回放池中采用优先经验回放机制;(2)每个智能体都使用同一个共享的经验回放池,并在共享的经验回放池中使用优先经验回放机制。第一种方式使得智能体之间不能共享各自学习到的优秀经验,导致训练速度缓慢;而第二种方式使得每个智能体都需要频繁地进行进程间的数据交互。因此传统的优先经验回放不适合用在异步强化学习中。
技术实现思路
1、针对上述提到的技术问题。本技术的实施例的目的在于提出了一种基于多池优先经验回放的强化学习网络训练方法及装置,来解决以上背景技术部分提到的技术问题,实现异步环境下的优先经验回放机制,使得智能体在该环境下更好的探索最优策略。
2、第一方面,本发明提供了一种基于多池优先经验回放的强化学习网络训练方法,包括以下步骤:
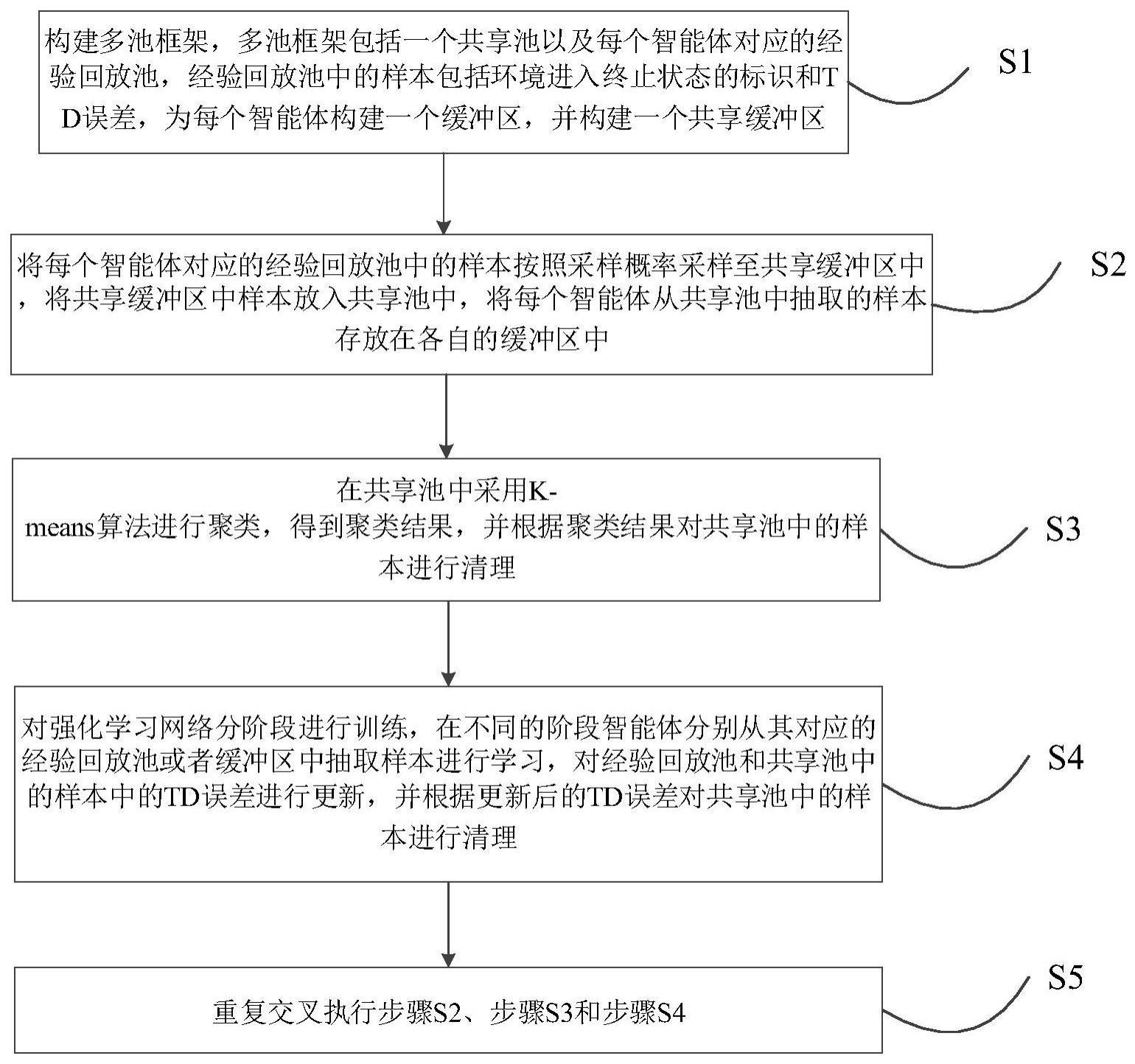
3、s1,构建多池框架,多池框架包括一个共享池以及每个智能体对应的经验回放池,经验回放池中的样本包括环境进入终止状态的标识和td误差,为每个智能体构建一个缓冲区,并构建一个共享缓冲区;
4、s2,将每个智能体对应的经验回放池中的样本按照采样概率采样至共享缓冲区中,将共享缓冲区中样本放入共享池中,将每个智能体从共享池中抽取的样本存放在各自的缓冲区中;
5、s3,在共享池中采用k-means算法进行聚类,得到聚类结果,并根据聚类结果对共享池中的样本进行清理;
6、s4,对强化学习网络分阶段进行训练,在不同的阶段智能体分别从其对应的经验回放池或者缓冲区中抽取样本进行学习,对经验回放池和共享池中样本的td误差进行更新,并根据更新后的td误差对共享池中的样本进行清理;
7、s5,重复交叉执行步骤s2、步骤s3和步骤s4。
8、作为优选,步骤s4具体包括:
9、将强化学习网络的训练分为第一阶段和第二阶段:
10、在第一阶段中,每个智能体从各自对应的经验回放池中抽取样本进行学习,重新计算抽取到的样本的td误差并进行更新;
11、在第二阶段中,每个智能体从各自对应的缓存区中抽取样本进行学习,重新计算共享池中所有样本的td误差并进行更新,根据更新后的td误差清理共享池的样本。
12、作为优选,根据更新后的td误差清理共享池的样本,具体包括:
13、对样本按照更新后的td误差从小到大进行排序,按第一清理比例的数量从更新后的td误差的最小值所对应的样本开始对其进行删除。
14、作为优选,在每个时间步中,强化学习网络中的每个智能体都与各自对应的环境进行交互,产生的样本放入经验回放池,经验回放池中的样本定义为<st,at,st+1,rt,done,td-error>,其中,st和at表示t时刻的状态和动作,st+1表示t+1时刻的状态,rt表示t时刻的奖励,done表示环境进入终止状态的标识,td-error表示td误差。
15、作为优选,td误差采用下式计算:
16、δt=rt+γq(st+1,at+1)-q(st,at);
17、其中,at+1表示t+1时刻的动作,γ表示折扣因子,q表示状态价值函数。
18、作为优选,采样概率为:
19、
20、其中,pi=|δt+ε|是样本i根据td误差排序得到的优先级,ε为非零正值,α表示决定优先采样的权值,当α=0时表示使用均匀采样的方式。
21、作为优选,步骤s3具体包括:
22、将共享池中的每个样本的状态st和动作at进行拼接,得到拼接样本,并构成拼接样本点集;
23、采用k-means算法对拼接样本点集中的拼接样本进行聚类,得到k个簇;
24、对每个簇内的拼接样本按第二清理比例进行清理。
25、第二方面,本发明提供了一种基于多池优先经验回放的强化学习网络训练装置,包括:
26、框架构建模块,被配置为构建多池框架,多池框架包括一个共享池以及每个智能体对应的经验回放池,经验回放池中的样本包括环境进入终止状态的标识和td误差,为每个智能体构建一个缓冲区,并构建一个共享缓冲区;
27、采样模块,被配置为将每个智能体对应的经验回放池中的样本按照采样概率采样至共享缓冲区中,将共享缓冲区中样本放入共享池中,将每个智能体从共享池中抽取的样本存放在各自的缓冲区中;
28、第一清理模块,被配置为在共享池中采用k-means算法进行聚类,得到聚类结果,并根据聚类结果对共享池中的样本进行清理;
29、第二清理模块,被配置为对强化学习网络分阶段进行训练,在不同的阶段智能体分别从其对应的经验回放池或者缓冲区中抽取样本进行学习,对经验回放池和共享池中样本的td误差进行更新,并根据更新后的td误差对共享池中的样本进行清理;
30、重复模块,被配置为重复交叉执行采样模块、第一清理模块和第二清理模块。
31、第三方面,本发明提供了一种电子设备,包括一个或多个处理器;存储装置,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如第一方面中任一实现方式描述的方法。
32、第四方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一方面中任一实现方式描述的方法。
33、相比于现有技术,本发明具有以下有益效果:
34、(1)本发明提出的基于多池优先经验回放的强化学习网络训练方法在异步环境下采用多池框架,能够解决不同智能体之间数据通讯的问题。
35、(2)本发明提出的基于多池优先经验回放的强化学习网络训练方法采用有效的自清理机制和自更新机制,解决了优先经验回放中数据缺乏多样性和td误差滞后的问题。
36、(3)本发明提出的基于多池优先经验回放的强化学习网络训练方法通过在每个智能体对应有缓存区,以将共享池中抽取的样本存入缓存区,每个智能体在不同的训练阶段分别从对应的经验回放池或缓存区中抽取样本进行学习,并构建有共享缓存区,以存放从经验回放池中抽取的样本,因此构成高效的数据交互结构,大大减少了进程通讯的成本。
- 还没有人留言评论。精彩留言会获得点赞!