一种个性化差分隐私场景下高可用的联邦学习方法、系统及设备
本发明属于信息安全,尤其涉及一种个性化差分隐私场景下高可用的联邦学习方法、系统及设备。
背景技术:
1、联邦学习(federated learning)是一种新兴的分布式机器学习框架,它使得数据在不出本地的情况下,通过交互模型中间参数进行模型训练,从而保护数据拥有方的隐私。目前联邦学习已广泛应用于各个领域,如智慧金融、智慧医疗、自动驾驶、无线通信、目标检测等。
2、虽然联邦学习通过参与方和服务器交换模型参数的方式保护了参与方的数据隐私,但是学者研究发现交换的模型参数也可能泄露原始训练数据。防止信息泄露的一种常用技术是差分隐私技术,现有的基于差分隐私联邦学习的工作包括本地差分隐私,基于随机梯度下降的差分隐私等。在本地差分隐私中,每个参与方根据其本地隐私预算的大小,对本地模型参数添加大小不同的扰动,并且向服务器发送扰动后的模型参数,从而保护参与方的隐私信息。现有的关于差分隐私联邦学习的工作假设所有参与方都有统一的隐私预算。然而,在实践中,参与方的隐私预算呈现出个性化特征。由于不同的隐私政策或数据主体的不同隐私偏好,不同的数据主体可能有不同的隐私需求,这导致跨主体隐私预算的不同。然而,现有的联邦平均聚合算法根据客户端数据集大小对本地模型进行加权平均,这并不适用于个性化差分隐私场景,因为隐私预算更小的客户端添加更大的扰动,导致模型可用性较低,在这种场景下采用联邦平均聚合算法将导致聚合模型可用性较低。且如何在对模型可用性参数进行隐私保护的同时,基于模型可用性参数进行全局模型聚合,从而提高模型可用性是一个极具挑战性的问题,目前,尚无较好的解决方案。
3、文献[r.hu,y.guo,h.li,q.pei and y.gong,"personalized federatedlearning with differential privacy,"in ieee internet of things journal,vol.7,no.10,pp.9530-9539,oct.2020,doi:10.1109/jiot.2020.2991416.]中提出了一种个性化联邦学习方案,通过学习用户的特征完成多任务学习,但该方案没有考虑联邦学习过程的安全性。
4、文献[g.yang,s.wang and h.wang,"federated learning with personalizedlocal differential privacy,"2021ieee 6th international conference on computerand communication systems(icccs),chengdu,china,2021,pp.484-489,doi:10.1109/icccs52626.2021.9449232.]中提出了一种个性化的差分隐私联邦学习方案,在该方案中,用户通过使用自己的隐私偏好扰动数据,但该方案没有考虑用户个性化添加噪声对于全局数据的影响,也没有量化隐私保护程度。
技术实现思路
1、为了克服上述现有技术的不足,本发明的目的在于提供一种个性化差分隐私场景下高可用的联邦学习方法、系统及设备,通过本地差分隐私技术实现对参与方本地模型的隐私保护,同时,基于模型可用性理论,通过联邦聚合算法,能够从可用性较高的本地模型中提取更多的有用信息,从而提高全局模型的可用性,在该算法中采用同态加密和安全多方计算技术对本地模型可用性参数进行隐私保护,本发明能够在保证模型可用性参数隐私的情况下提高聚合模型的可用性。
2、为了实现上述目的,本发明采用如下技术方案:
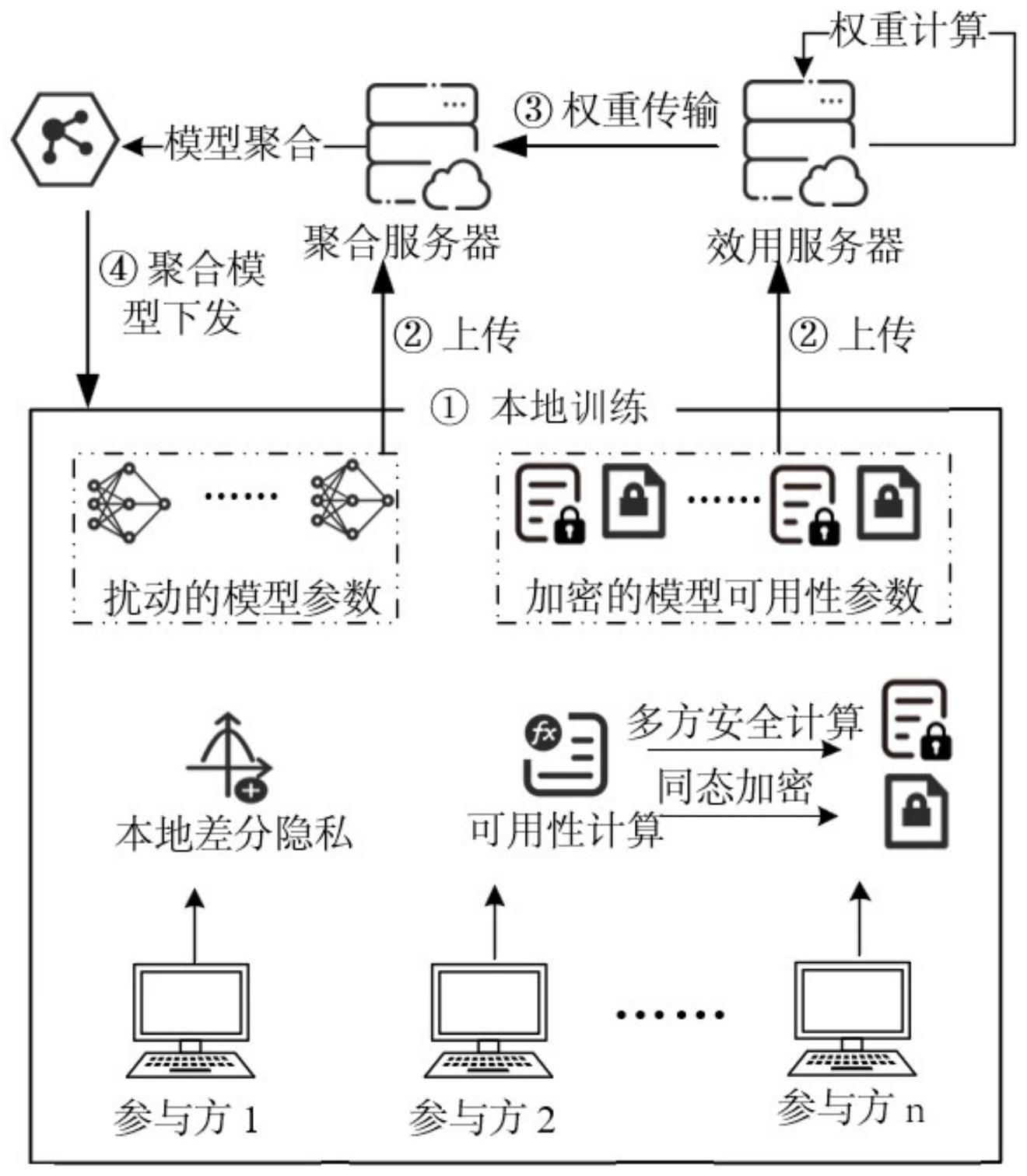
3、一种个性化差分隐私场景下高可用的联邦学习方法,各参与方使用本地数据集训练本地模型,通过本地差分隐私技术实现对参与方本地模型的隐私保护,同时,各参与方根据模型可用性理论计算本地模型可用性,并采用同态加密技术将明文下的模型可用性参数加密,采用安全多方计算技术加密明文下的模型可用性参数;然后,参与方将通过差分隐私保护的本地模型上传至聚合服务器,同时,将采用同态加密及安全多方计算方法加密的模型可用性参数全部上传至效用服务器;效用服务器利用接收到的加密模型可用性参数进行计算,得到密文下的本地模型聚合权重,之后将密文下的本地模型聚合权重发送至聚合服务器;聚合服务器解密得到密文聚合权重,并根据聚合权重进行模型聚合,最后将聚合模型下发至各参与方。
4、上述个性化差分隐私场景下高可用的联邦学习方法,建立在如下系统假设上:
5、1)系统中共有n名参与方,参与方集合记为u={u1,u2……,un},各参与方的本地数据集分别为{d1,d2……,dn},所有参与方的数据集表示为d;
6、2)各参与方的本地神经网络模型的类型和结构相同,各参与方的隐私预算可以不同,本地数据集独立同分布或非独立同分布均可;
7、3)聚合服务器和效用服务器是诚实好奇且不共谋的。
8、一种个性化差分隐私场景下高可用的联邦学习方法,具体包括以下步骤:
9、步骤1:系统初始化:包括生成用于同态加密的公私钥对,参与方两两密钥协商,产生掩码;服务器初始化全局模型,然后下发给本地参与方;
10、步骤2:各参与方对服务器下发的全局模型进行本地模型训练,基于本地隐私预算,实现本地模型信息的差分隐私保护,并将实现差分隐私保护的本地模型参数上传至聚合服务器;
11、步骤3:各参与方根据模型可用性理论计算步骤2实现差分隐私保护的本地模型可用性,并通过同态加密和掩码技术实现对本地模型可用性参数的隐私保护,并将结果上传至效用服务器;
12、步骤4:效用服务器根据步骤3得到的信息获取密文下的聚合权重,并将该密文下的聚合权重发送至聚合服务器;
13、步骤5:聚合服务器通过私钥解密收到的聚合权重,并根据解密后的聚合权重和本地模型参数进行模型聚合,最后将聚合模型下发至各参与方;
14、步骤6:重复步骤2至步骤5,进行下一轮模型训练,直到训练轮数达到预定义的训练轮数或者模型收敛。
15、所述步骤1系统初始化的具体方法为:
16、利用keygen(1λ)→(pk,sk)密钥生成函数,λ为安全参数,函数输出为各参与方共享的公钥pk与私钥sk,产生一个公私钥对(pk,sk),私钥sk由聚合服务器持有,公钥pk由各参与方和效用服务器持有;参与方ui和uj,i≠j,通过keygen(1λ),agree和掩码生成算法生成了一系列掩码服务器初始化全局模型并将模型信息下发至各参与方;各参与方选择各自的本地隐私预算。
17、所述步骤2中基于本地隐私预算,实现本地模型信息的差分隐私保护的具体方法为:
18、
19、根据dpsgd算法可以得到:给定数据采样率q和训练轮数t,且存在常数c1和c2,对于任意隐私预算ε<c1q2t,如果选择噪声标准差那么算法1满足(ε,δ)-差分隐私。
20、所述步骤3的具体方法为:
21、定义本地模型可用性其中,本地损失为t是当前模型训练轮数,dt表示第t轮训练时各参与方从本地数据集d中随机采样的数据,采样的数据集的大小为jt=|dt|,w*是最小化本地损失的最优模型参数;
22、根据模型可用性定理可以得到:对于μ光滑和λ强凸的模型损失l(wt,dt),令学习率d为模型参数的维度,c为梯度的正则化边界,σ2为添加的高斯噪声的方差,采用dpsgd算法训练t轮后的本地模型的可用性满足:
23、
24、由上述定理可知,参与方的本地模型的可用性正比于
25、基于各参与方的本地模型可用性确定参与方的本地模型参数在聚合过程中的权重,即参与方ui在第t轮的聚合权重为:
26、
27、其中,为参与方ui在第t轮的模型可用性,为所有参与方在第t轮的模型可用性之和;
28、计算参与方ui本地模型的可用性之后参与方ui将模型可用性参数与本地掩码相加得到掩码保护下的模型可用性参数同时通过同态加密得到密文形式的模型可用性参数然后将掩码保护下的模型可用性参数和经同态加密保护的模型可用性参数上传到效用服务器。
29、所述步骤4的具体方法为:
30、首先,效用服务器将其接收到的所有掩码保护下的模型可用性参数相加从而消除掩码的影响,即:
31、
32、然后,效用服务器通过加密函数使用公钥pk对明文加密,得到之后,通过密文乘法函数得到并将聚合权重发送至聚合服务器。
33、所述步骤5的具体方法为:
34、首先,聚合服务器将从效用服务器处获取的进行解密来得到每个参与方本地模型的聚合权重:即解密函数使用密钥sk对密文解密后,得到聚合权重然后,聚合服务器根据来自参与方的本地模型参数和聚合权重进行模型聚合,即:
35、
36、最后,将全局模型参数下发至各参与方。
37、基于上述个性化差分隐私场景下高可用的联邦学习方法的系统,包括:
38、系统初始化模块,用于步骤1所述系统初始化,包括生成用于同态加密的公私钥对,参与方两两密钥协商,产生掩码;服务器初始化全局模型,然后下发给本地参与方;
39、本地模型训练模块,用于步骤2中各参与方对初始化后的全局模型进行本地模型训练,基于本地隐私预算实现本地模型信息的差分隐私保护,并将实现差分隐私保护的本地模型参数上传至聚合服务器;
40、可用性计算及保护模块,用于步骤3所述计算本地模型可用性,以及利用掩码和同态加密对可用性参数实现隐私保护;
41、聚合权重计算模块,用于在不泄露可用性隐私的情况下,根据步骤4所述方法计算得到聚合权重;
42、模型聚合模块,用于步骤5所述的进行模型聚合。
43、基于上述个性化差分隐私场景下高可用的联邦学习方法的系统,包括:
44、存储器,用于存储计算机程序;
45、处理器,用于执行所述计算机程序,所述计算机程序被处理器执行时能够实现步骤1至6所述的个性化差分隐私场景下高可用的联邦学习方法。
46、一种计算机可读存储介质,所述计算机可读存储介质用来存储计算机程序,所述计算机程序被处理器执行时能够根据步骤1至6所述个性化差分隐私场景下高可用的联邦学习方法,实现对参与方本地模型的隐私保护,在保证模型可用性参数隐私的情况下提高聚合模型的可用性。
47、本发明与现有技术相比,具有如下优点:
48、1、本发明针对个性化差分隐私场景下聚合模型可用性不足的问题,基于模型可用性定理,设计了一种新的联邦聚合方法,与现有方法相比,本发明方法使得服务器能够从可用性较高的模型中提取更多的有用信息,在个性化差分隐私场景下得到高可用的聚合模型;同时在此过程中通过同态加密和安全多方计算技术实现对本地模型可用性参数的隐私保护。
49、2、本发明利用模型可用性定理,通过在模型聚合过程中引入模型可用性参数来确定各参与方的本地模型权重,能够使得服务器从可用性较高的模型中提取更多的有用信息,从而得到可用性更高的聚合模型。
50、3、本发明采用同态加密和安全多方计算技术对本地模型可用性参数进行隐私保护,能够在保证模型可用性参数隐私的情况下提高聚合模型的可用性。
51、综上,本发明具有个性化隐私保护性好,精度高的优点。
- 还没有人留言评论。精彩留言会获得点赞!