基于改进Transformer模型的风力发电量预测方法
本发明提供了一种基于改进transformer模型的风力发电量预测方法,属于深度学习。
背景技术:
1、工业物联网技术大力发展,生产规模逐渐增大,以及人工智能技术的突飞猛进背景下,越来越多的神经网络模型应用于工业生产的过程中,其在安全预警、节能降耗中逐渐扮演着重要的角色,工业生产中由设备传感器采集的海量时序性数据,记录着设备的工作及健康状态,为工业设备的监测预警提供了大量的数据资源。因此,对采集到的工业时序数据,进行有效地建模和预测,可以为将来资源调度提供数据依据,从而减少资源浪费,或者为设备潜在风险提前预警,保障工业生产过程的可靠性,对整个工业过程的经济效益最大化具有重要意义。
2、当前工业生产数据的预测大部分采用单变量时序预测,仅仅收集本设备节点采集的时序性数据,或者依靠添加设备型号、运行模式、环境温度等静态变量协助预测,忽略了设备的整体结构状态,以及结构与结构之间的依赖性或变量因素与变量因素之间的依赖性,从而导致需要监视的某些指标的周期性预测受到了限制。而且随着物联网的发展,多源数据采集逐渐普及,可以在预测关键变量时充分的利用邻接设备或结构的时序性数据,提取其他时序性数据的周期性、趋势性信息,使预测变量的时序性预测更加准确。
3、风力发电是一种再生能源,其在发电过程中能够有效节省标煤并减少二氧化硫、二氧化碳和氮氧化物等气体排放量。对于风力发电量进行准确的中长期预测对于电网的发展规划具有十分重要的影响。目前对于风力发电量的预测方法包括神经网络、支持向量机、自回归滑动平均模型等,而目前采用的各种对于风力发电量的预测模型都依赖于单一预测变量时序数据以及静态变量的时序数据模型,忽略了风力发电过程中不同因素时序数据之间趋势与波动相互之间的影响因素,导致模型由于捕捉信息不全面而造成预测能力的下降。
4、因此,本发明提出了一种基于改进transformer模型的风力发电量预测方法,其对transformer中原多头自注意力机制进行改进,增加维度间的注意力机制,并在变量维度上进行卷积操作,使得模型能够有效利用其他与风力发电量相关时序变量的信息从而提升预测能力。
技术实现思路
1、本发明为了解决风力发电量预测时依赖于单一预测变量即发电量历史时序数据以及静态变量如设备型号的时序数据模型,忽略风力发电量预测变量的历史时序数据中的时间模式往往受到其他时序数据影响的客观因素,导致模型由于捕捉信息不全面而造成预测能力下降的问题,提出了一种基于改进transformer模型的风力发电量预测方法。
2、为了解决上述技术问题,本发明采用的技术方案为:一种基于改进transformer模型的风力发电量预测方法,包括如下步骤:
3、s1:获取风力发电机中的发电量历史数据,将发电量历史数据作为预测变量,将与发电量历史数据有不同程度相关性的风力发电机中设备传感器捕捉到的历史数据作为非预测变量;
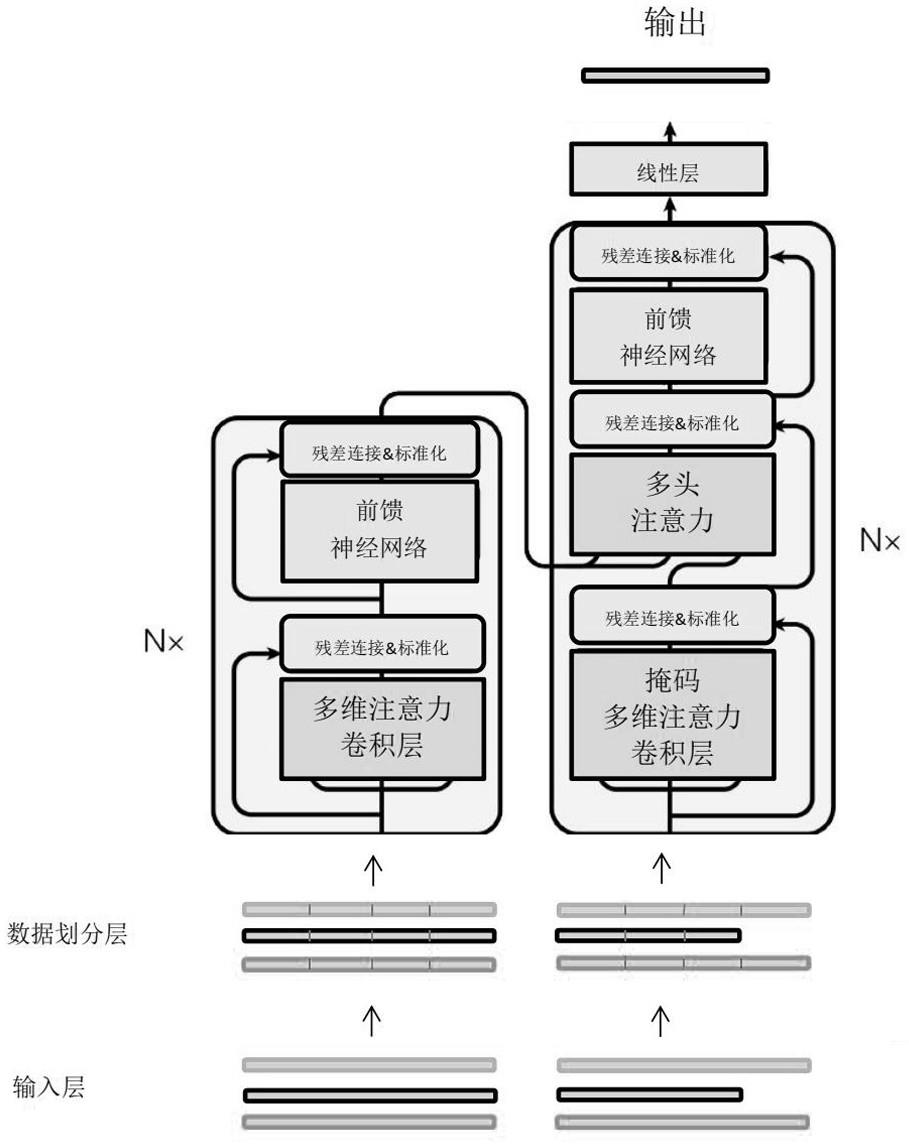
4、s2:编码阶段将预测变量和非预变量的原始时序数据分别经过数据划分层划分为序列段组成的序列,并将上述一系列序列输入至改进transformer模型的编码器中;
5、s3:经过划分的数据首先经过编码器中encoder的多维注意力卷积层,先通过自注意力提取自身特征,再通过多维注意力进行模态间的注意力操作,捕捉预测变量中的时间特征与非预测变量中的时间特征之间的依赖关系,之后再通过卷积机制将捕捉到的依赖关系作用到预测变量中;
6、s4:经过多维注意卷积力层输出含有非预测变量特征的预测变量作为encoder中前馈神经网络层的输入进行映射,在编码器经过n层encoder的编码后,将映射的信息将传输至解码器每层decoder的多头注意力机制层;
7、s5:解码阶段将经过数据划分层的非预测变量的历史序列和初始化生成的预测变量的未来序列输入至解码器中decoder的带掩码的多维注意力卷积层中,将多维注意力卷积层输出的预测变量流入到后续的多头注意力机制层,利用编码层提取的信息进行特征信息交互,接着经过decoder中的前馈神经网络层进行映射,在经过解码器n层decoder解码之后得到最终的预测值。
8、所述步骤s1中的非预测变量为风力发电机通过设备传感器捕捉的风力历史数据和湿度历史数据。
9、所述数据划分层的输入为包括预测变量和非预测变量的一系列时序数据,假设序列长度都为l,则数据划分层的输入为d×l的二维矩阵,其中d代表预测变量和非预测变量的个数,经过数据划分层的处理,每条时序变量被划分成n个序列段,其中每个序列段的长度为s,数据划分层的输出为d×n的二维矩阵。
10、所述多维注意力卷积层总共包含3个操作,首先是与传统transformer相同的自注意力机制将预测变量在时间维度上采用多头自注意力机制对自身进行特征加强;
11、第二个是在变量之间进行多维注意力操作,以预测变量的每个序列段作为query,以非预测变量的序列段作为key和value进行注意力机制,用于将非预测变量与预测变量某一序列段相关的信息重构到与预测变量某一序列段的特征相同的位置,这样得到的非预测变量与预测变量相对应位置有很高的相关性,方便后续预测变量更好的结合非预测变量的特征信息。此时多维注意力卷积层的输入是d×n二维矩阵,其中d为时序变量的个数,n为序列段个数,经过多维度间的注意力机制,输出仍为d×n二维矩阵;
12、第三个操作是卷积操作,用于将不同的非预测变量特征信息融合到预测变量中,同时也要为不同的非预测变量做不同的依赖程度融合,传统操作通过类似于lstm遗忘门通过sigmoid函数来获得不同权重的依赖,这样做会经过大量运算而降低效率,本发明提出用一个卷积核来解决上述问题,通过训练卷积核不同位置的权重,来调整不同非预测变量与预测变量之间的重要程度,且需要训练的参数量也小于传统做法,将通过多维注意力操作输出的d×n二维矩阵,利用宽度是一个d维,长度与序列段的长度相同的卷积核进行卷积操作,采用滑动窗口方式沿着序列段维度进行滑动,通过上述卷积核扫过d*n的矩阵,将非预测变量的特征融合到预测变量中,最终多维注意力卷积层得到一个1*n的输出。
13、所述解码器的输入是(d-1)×l的非预测变量二维矩阵以及初始化生成的1×h的预测变量,其中(d-1)为非预测变量的个数,l为非预测变量历史的长度,输入数据同样先经过数据划分层,之后数据流入到解码器中,解码器的每个decoder中含有三个子层,为带有掩码的多维注意力卷积层,与编码器进行信息交互的注意力层,用来增加模型能力的前馈神经网络层,其中每个子层分别续接一个残差连接并进行标准化处理。
14、解码器是由多个decoder堆叠而成,其输入是一个长度为h的初始化生成未来预测变量和多个长度为l的历史非预测变量,每个decoder里面的子层与encoder中相似,其中为了防止解码时预测生成的预测变量t时刻的信息(其中t属于任意时刻)利用未来信息对自身进行特征加强,所以decoder中的多维注意力卷积层在进行自注意力操作时,会加入掩码张量以用来屏蔽未来信息。整体做法与传统transformer类似,不同之处在于,传统transformer在预测时预测变量的未来序列时,是逐步预测的方式,先生成第一个值再将生成的第一个值投入到解码器中,这样做造成误差累积的现象,本发明采用直接多步预测,直接生成预测变量需要预测的未来序列。
15、本发明相对于现有技术具备的有益效果为:本发明分利用了transformer模型在时序数据预测过程中在时间维度具有的很好特征捕捉的能力,将这种特性迁移到对多种序列特征捕捉上。考虑到不同的时序数据对关键变量的影响程度,且卷积在特征提取上计算量小等优点,在特征融合时利用卷积的思想将其他时序数据的特征融合到关键变量的预测当中。多变量卷积transformer模型解决了以往在进行单变量时序数据时,往往忽略其他相关变量对需要预测的变量的影响的问题,使得所提模型考虑的更加全面,预测能力也会增强。
- 还没有人留言评论。精彩留言会获得点赞!