数据关系图谱构建方法、装置、设备、存储介质与流程
本发明涉及大数据处理,具体涉及一种数据关系图谱构建方法、装置、设备、存储介质。
背景技术:
1、结构化数据之间的关联关系是指两个数据集之间不同字段之间的关联关系以及数据集之间存在的业务联系。在关系型数据库中,数据关系大致可以分为一对多和多对多两种,细分操作包括左连接、右连接、外连接、内连接等。在数据关联分析中数据关系是反映某个事物与其他事物之间的相互依存关系,这些关系有可能是直接关联也有可能是间接关系,比如著名的美国沃尔玛连锁超市“啤酒与尿不湿”的故事。为了方便分析各种数据的关联关系数据科学家们相继提出了apriori、setm、fp-tree、fp-g、freespan、prefixspan、fp-growth等分析两个数据集之间的关联关系的算法,除此之外为了度量数据集中两个变量的相关程度和密切程度数据科学家们还提出了pearson相关系数、kendall相关系数和spearman相关系数等方法。目前数据关联分析的主流技术包括:相关性分析、回归分析、聚类分析等方法。根据数据之间的关联程度,可以将两个数据集变量分为不存在关系、存在模糊的关联、存在较强但不清晰的关联、存在清晰的可以度量的关系。
2、然而,目前存在的数据关系分析大都只关注了数据本身的内容之间的关联关系,忽略了数据仓库形成过程中的重要信息,导致对于海量数据的关联关系全量分析没有良好的开源解决方案。
技术实现思路
1、本发明实施例的目的在于提供一种数据关系图谱构建方法、装置、设备、存储介质,解决现有的数据关系分析大都只关注了数据本身的内容之间的关联关系,忽略了数据仓库形成过程中的重要信息,导致对于海量数据的关联关系全量分析没有良好的开源解决方案的问题,具体技术方案如下:
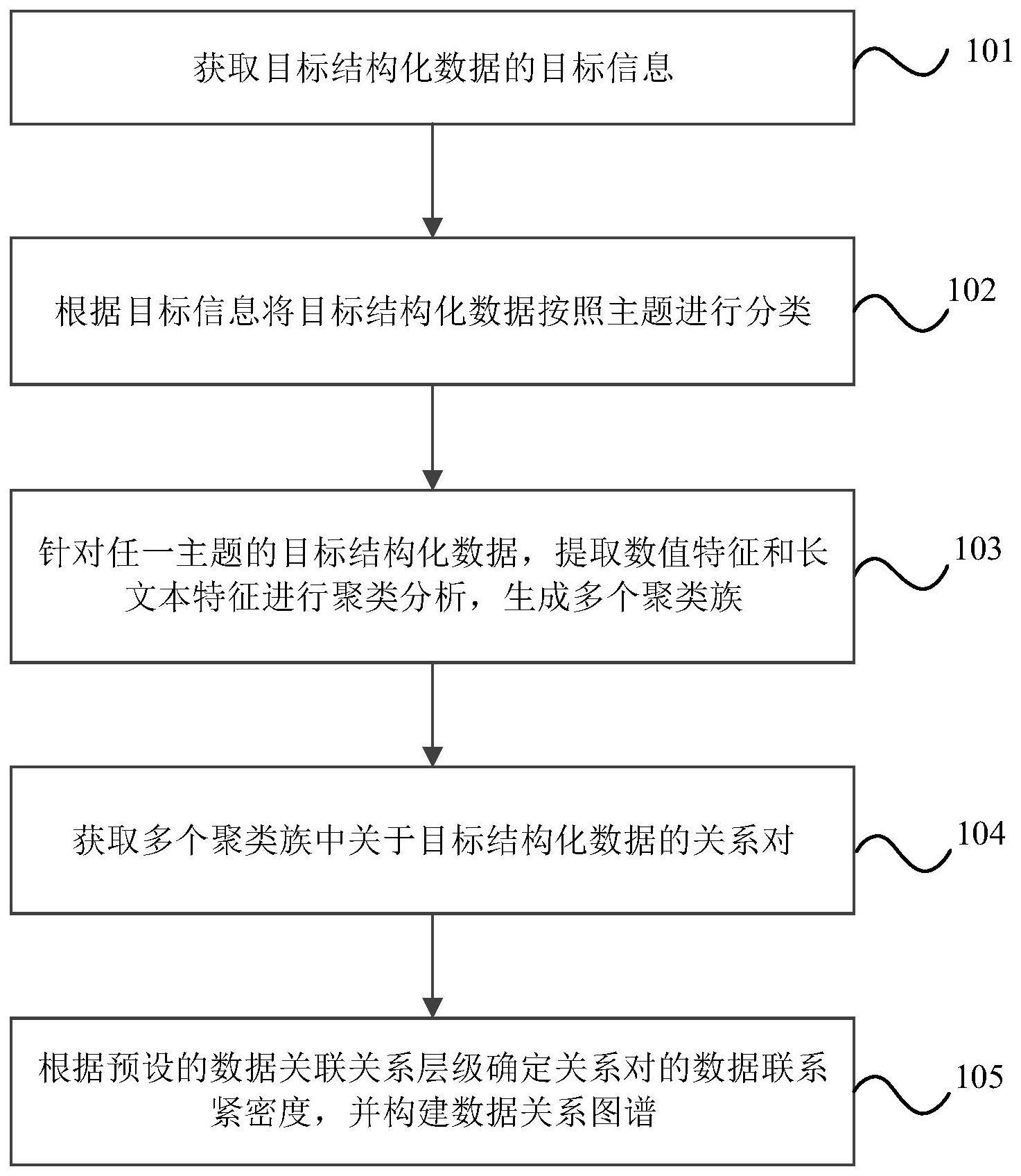
2、根据本技术实施例的第一方面,提供一种数据关系图谱构建方法,所述方法包括:
3、获取目标结构化数据的目标信息;
4、根据所述目标信息将所述目标结构化数据按照主题进行分类;
5、针对任一主题的所述目标结构化数据,提取数值特征和长文本特征进行聚类分析,生成多个聚类族;
6、获取多个所述聚类族中关于所述目标结构化数据的关系对;
7、根据预设的数据关联关系层级确定所述关系对的数据联系紧密度,并构建数据关系图谱。
8、可选的,所述目标信息包括所述目标结构化数据的名称信息和业务备注信息;
9、所述根据所述目标信息将所述目标结构化数据按照主题进行分类,包括:
10、将所述目标结构化数据的名称信息和业务备注信息进行分词、词性识别;
11、根据识别后的结果和所述目标信息确定所述目标结构化数据的主题;
12、按照所述目标结构化数据的主题将所述目标结构化数据进行分类。
13、可选的,所述获取多个所述聚类族中关于所述目标结构化数据的关系对之前,还包括:
14、针对任一所述聚类族计算任意两个所述目标结构化数据的相似度;
15、在检测到任意两个所述目标结构化数据的相似度大于相似度衡量值的情况下,确定任意两个所述目标结构化数据是关系对;
16、在检测到任意两个所述目标结构化数据的相似度小于相似度衡量值的情况下确定任意两个所述目标结构化数据不是关系对。
17、可选的,所述目标结构化数据包括:目标数据包,目标数据集,目标数据列,其中,一个目标数据包包括多个目标数据集,一个目标数据集包括多个目标数据列;
18、所述根据预设的数据关联关系层级确定所述关系对的数据联系紧密度,并构建数据关系图谱之前,还包括:
19、针对任一关系对,在确定目标数据集的名称相似度,目标数据集的业务场景相似度,目标数据包的名称相似度,目标数据包的业务场景相似度均大于相似度衡量值,且不同目标数据集的目标数据列内容具有包含关系的情况下,确定所述任一关系对存在一级关联关系;
20、针对任一关系对,在确定目标数据集的名称相似度,目标数据集的业务场景相似度,目标数据包的名称相似度,目标数据包的业务场景相似度,目标数据列的名称主题相似度,目标数据列的业务备注主题相似度均大于相似度衡量值的情况下,确定所述任一关系对存在二级关联关系;
21、针对任一关系对,在确定所述关系对对应的目标结构化数据存在血缘关系和/或衍生关系的情况下,确定所述任一关系对存在三级关联关系;
22、针对任一关系对,在确定所述关系对对应的目标结构化数据存在业务关联的情况下,确定所述任一关系对存在四级关联关系;
23、针对任一关系对,在确定所述关系对对应的目标结构化数据存在变化趋势的相关关系的情况下,确定所述任一关系对存在五级关联关系;
24、根据所述一级关联关系,所述二级关联关系,所述三级关联关系,所述四级关联关系和所述五级关联关系生成所述数据关联关系层级。
25、可选的,所述根据预设的数据关联关系层级确定所述关系对的数据联系紧密度,并构建数据关系图谱,包括:
26、获取所述关系对中目标结构化数据的目标相似度,所述目标相似度包括:目标数据集的名称相似度,目标数据集的业务场景相似度,目标数据包的名称相似度,目标数据包的业务场景相似度,目标数据列的名称主题相似度以及目标数据列的业务备注主题相似度;
27、根据所述目标相似度确定所述关系对对应的目标数据关联关系层级;
28、获取所述目标数据关联关系层级的计算规则,以及关于所述目标相似度的第一权重指数;
29、根据所述第一权重指数,所述目标相似度和所述计算规则生成所述关系对的数据紧密程度;
30、根据所述数据紧密程度构建所述数据关系图谱。
31、可选的,所述获取所述目标数据关联关系层级的计算规则,以及关于所述目标相似度的第一权重指数之后,还包括:
32、若所述目标数据关联关系层级为一级关联关系,则生成所述关系对的交并比;
33、获取所述关系对中关于所述交并比的第二权重指数;
34、根据所述第二权重指数,所述关系对的交并比,所述第一权重指数,所述目标相似度和所述计算规则生成处于一级关联关系的所述关系对的数据紧密程度。
35、根据本技术实施例的第二方面,提供一种数据关系图谱构建装置,所述装置包括:
36、第一获取模块,用于获取目标结构化数据的目标信息;
37、第一分类模块,用于根据所述目标信息将所述目标结构化数据按照主题进行分类;
38、第一生成模块,用于针对任一主题的所述目标结构化数据,提取数值特征和长文本特征进行聚类分析,生成多个聚类族;
39、第二获取模块,用于获取多个所述聚类族中关于所述目标结构化数据的关系对;
40、第一构建模块,用于根据预设的数据关联关系层级确定所述关系对的数据联系紧密度,并构建数据关系图谱。
41、根据本技术实施例的第三方面,提供一种电子设备,包括:
42、处理器;
43、用于存储所述处理器可执行指令的存储器;
44、其中,所述处理器被配置为执行所述指令,以实现如第一方面所述的数据关系图谱构建方法。
45、根据本技术实施例的第四方面,提供一种计算机可读存储介质,当所述存储介质中的指令由移动终端的处理器执行时,使得移动终端能够执行如本技术第一方面所述的数据关系图谱构建方法。
46、本技术的实施例提供的技术方案可以包括以下有益效果:
47、本发明通过获取目标结构化数据的目标信息;根据目标信息将目标结构化数据按照主题进行分类;针对任一主题的目标结构化数据,提取数值特征和长文本特征进行聚类分析,生成多个聚类族;获取多个聚类族中关于目标结构化数据的关系对;根据预设的数据关联关系层级确定关系对的数据联系紧密度,并构建数据关系图谱。本发明通过利用目标结构化数据的名称信息,业务备注信息以及数值特征和长文本特征初步确定多个目标结构化数据的关系对,而后利用设置的数据关联关系层级将关系对分级。从而构建数据关系图谱,这一构建方式不仅关注了数据本身的内容之间的关联关系,还关注了目标结构化数据形成过程中的重要信息,可以很好地适用于对海量数据的关联关系全量分析。
48、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!