基于图像重建和编辑的融合语义增强clip的扩散网络
本发明属于预成型焊片生产,具体为基于图像重建和编辑的融合语义增强clip的扩散网络。
背景技术:
1、近年来图像重建和编辑领域异常火爆,基于扩散的图像处理方法已经发展到了一个相当高的水平,并且去噪扩散网络的图像生成质量已经明显超越了生成对抗网络(gan)的生成质量。现在大多数的图像重建和编辑的工作都是基于生成对抗网络(gan)的,他们构建数据集和优化函数的复杂性和训练过程的不确定性是此方法的痛点,使用去噪扩散网络进行抽象图像的重建和全局风格图像的编辑可以很好的解决这些问题。最近几年去噪扩散模型【39】【67】和基于分数函数的去噪模型【42】【43】以及基于随机微分方程的得分匹配的去噪模型【63】【64】【65】发展迅猛。现在优秀的基于生成对抗网络(gan)的生成模型可以生成极具真实感的图像,例如tero karras等人的stylegan【66】和stylegan2【62】weihaoxia等人的tedigan【80】,这些研究是以生成对抗网络(gan)作为技术基础的图像编辑方法,很好的解决了人物细节特征的解纠缠问题。近几年去噪扩散网络展现出的优秀的图像生成性能,最新的研究song等人【68】,dhar iwal&nichol等人【69】,gwanghyun kim,jong chul等人【70】,他们的研究表现出了优于gan的方法的性能,去噪扩散网络通过多轮采样不断的优化图像的细节特征,从而产生高质量的图像。基于去噪扩散的方法生成的图像具有更好的真实感和更少的噪点,并且具有模式覆盖范围广和训练稳定的额外优势。
2、在基于去噪扩散网络的图像处理的应用中,特别令人感兴趣的是抽象图像生成真实图像和基于文本的图像编辑。例如,在重建生成中,用户只需要给定一个抽象的图像就可以生成一个具有真实感的照片。在编辑过程中,用户只需要给定一个原始的图像和文本描述就可以实现风格编辑。(a)展示了我们的抽象图像重建生成和(b)文本引导的图像编辑过程。生成的图像需要符合两个要求,首先是要保留抽象图像的纹理和轮廓特征,其次应该具有真实感,生成后的图片人眼都很难分辨真假。图像重建可以广泛应用于图像修复和图像创作领域。文本引导的图像编辑需要符合两个要求,一是编辑后的图像需要保留源图像的基本特征,二是编辑后的图像风格要和文本描述的风格相一致。可以广泛应用于影视特效制作或者艺术创作领域。
3、现有的图像重建方法,第一种是condition gan【23】【24】【25】【26】【27】【45】,这类方法通过学习从原始图像到目标图像的直接映射,它的泛化能力非常低,每一个新的图像类别都需要重新训练,因此需要花费昂贵的设备和大量的时间。第二种就是gan inversion【28】【29】【30】【31】,这种方法首先使用预先训练的gan将输入图像映射到潜在空间,它使用latentcode来表示,然后手动设计优化函数来进行训练,虽然避免了重新构建数据集,但是这种方法有时无法找到准确的latentcode,因此训练可能具有不稳定性,导致无法很好的完成任务。
4、近几年来在图像编辑领域也面临一些棘手的问题,一些针对扩散模型进行图像处理的研究【71】【72】,如属性编辑【73】和图像转换(transfor m)【74】,但是这种方法也只能处理单一风格的图像,它不具有通用性。最新的研究【47】【48】,gan与对比语言-图像预训练模型clip【75】的结合,展示出了十分卓越的性能,在无需额外构建数据集的情况下,只需要简单的文本描述即可实现图像的编辑,由于有限的模型容量和优化函数构建难度问题,这种方法很难达到我们想要的结果,很难完成完美的重建和全局的图像编辑。因此,需要设计基于图像重建和编辑的融合语义增强clip的扩散网络。
技术实现思路
0、
技术实现要素:
1、本发明的目的就在于为了解决上述问题而提供基于图像重建和编辑的融合语义增强clip的扩散网络,解决了背景技术中提到的问题。
2、为了解决上述问题,本发明提供了技术方案:
3、基于图像重建和编辑的融合语义增强clip的扩散网络,具体步骤包括:
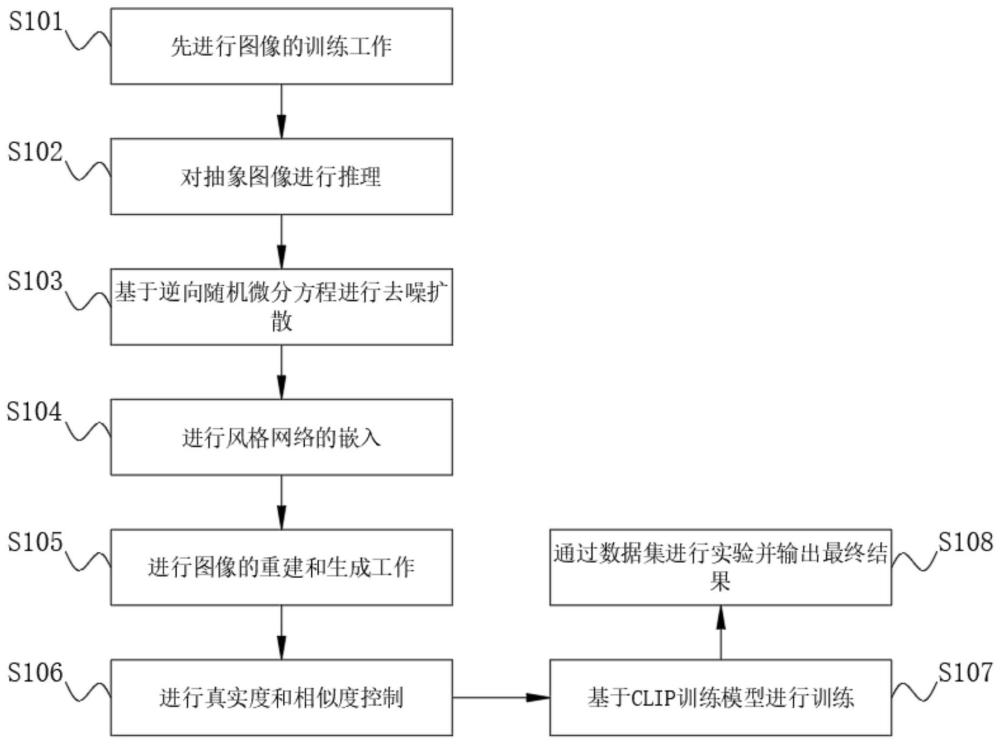
4、步骤s101:先进行图像的训练工作;
5、步骤s102:对抽象图像进行推理;
6、步骤s103:基于逆向随机微分方程进行去噪扩散;
7、步骤s104:进行风格网络的嵌入;
8、步骤s105:进行图像的重建和生成工作;
9、步骤s106:进行真实度和相似度控制;
10、步骤s107:基于clip训练模型进行训练;
11、步骤s108:通过数据集进行实验并输出最终结果。
12、作为优选,所述步骤s101中,训练阶段,输入图像首先通过一个由文本引导的风格映射网络,映射网络将输入图像映射到扩散网络的采样空间,然后在扩散网络从采样空间w中采样,采样出相应特征分布的图像,通过添加随机噪声对此图像进行扰动;其中随机噪声符合高斯分布,然后我们进行扩散过程的逆向推理,逆向推理过程我们应用随机微分方程的基本方法进行参数的更新;在损失函数的指导下对扩散模型进行参数优化。
13、作为优选,所述步骤s102中,推理阶段将抽象图像输入到扩散网络中,我们将训练过程中的映射网络移除,首先扰动图像,然后经过reverse sde生成真实的人像,这个人像具有风格图像的纹理特征,我们的推理时间在rtx3090gpu上为40秒;为了推理过程的高效性,我们将风格图像输入到reverse sde中,通过提前训练好的采样参数对图像进行采样,将图片空间中符合ske tch的特征分布的图像转化为符合photo特征分布的图像。
14、作为优选,所述步骤s103中,逆向随机微分方程是一种生成模型,我们的方法基于此模型,它采用(条件)得分匹配作为优化函数来进行去噪扩散,最终可以从简单的高斯噪声扩散成为一个具有真实度的图像,即随机噪声分布到目标分布的映射;整个扩散过程被划分为固定的t步,就是“正向”和“逆向”过程都被分为t步,这个过程有着相当大的人为性,事实上,真实的“正向”、“逆向”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(stochastic differentialequation,sde)来描述;
15、dx=ft(x)dt+gtdw
16、其中w是一个wiener过程,t表示时间步骤;
17、我们只需要将它看成是下述离散形式在δt→0时的极限:
18、
19、逆向过程,用条件概率表示为:
20、
21、取的极限,那么对应的逆向sde为(详细证明过程参见附录):
22、
23、得分匹配【8】是通过一系列数学公式推导出数据的概率分布情况,要完成扩散还需要
24、我们可以得到a的采样结果为:
25、条件得分匹配【9】的损失函数,最终的损失优化函数如下(证明过程见附录):
26、
27、此时sθ(xt,t)
28、是我们需要训练更新的得分匹配函数,我们从结果倒推可以算得
29、最终的损失函数表达式为(证明过程详见附录):
30、
31、(采样公式a)
32、其中是边界系数,满足并且
33、通常认为随机微分方程包括两个类型:
34、(1)方差爆炸的ve-sde,对于所有的t都有p1无限接近于高斯分布n(0,σ2(1)i);
35、方差保留的vp-sde满足α2(t)+β2(t)=1,当t→1,α(t)→0时σ2(1)=1
36、,则在时间步骤t1满足高斯分布n(0,1),ve-sde和vp-sde都在时间步骤从0到1时将数据分布转换为随机高斯噪声;
37、clip【11】可以将数据集中的文本和图片匹配起来嵌入到相同的语义空间中;在我们的方法中,我们使用了一个预训练的clip模型作为我们的风格指导图像的嵌入模型;为了有效的从clip中提取有用的信息,(patashnik et al.,2021;【13】gal et al.,2021【12】)提出了两种不同的损失:全局目标损失和局部方向损失;损失函数如下:
38、lclip(x0,ttar)=dclip(x0,ttar)
39、其中ttar是某个目标图像对应的文本描述,x0表示reversesde生成的图像,dclip返回它们之间在clip潜空间中的余弦距离;另一方面,局部方向损失(gal etal.,2021)【12】的设计是为了缓解全局clip损失的问题,如低多样性的影响;
40、局部方向clip损失导致reference和生成图像的编码向量之间的方向与clip空间中的reference和目标文本的编码向量之间的方向对齐,如下所示:
41、
42、where
43、δt=et(ttar)-et(tref),δi=ei(xtar)-ei(xref)
44、其中ei是图像编码器,et是文本编码器,tref、xref分别是源图像文本描述和源图像;已知由定向clip引导的图像损失对模式崩溃问题具有鲁棒性,因为通过将操作图像和目标图像之间的变化方向与参考文本和目标文本之间的变化方向对齐,会生成不同的图像。
45、作为优选,所述步骤s104中,为了避免构建新的数据集,我们使用一个在vgg上预训练的风格映射网络,传统方法潜在代码通过正则化之后直接提供给生成器,这个网络可以将我们现有的数据图像映射到相应的风格空间;为了更方便的训练,我们的映射网络采用预先训练的vgg编码器-解码器【2】网络。我们只需要相应的文本描述就可以将原始图像嵌入到采样空间中。
46、作为优选,所述步骤s105中,重建图像是采样空间w中采样出来的,我们将在song等人【10】预训练的sde模型上进行训练;我们生成的重建图像要具备两个基本的目标:1.保留风格图像的纹理特征;2.生成的重建图像要和要有很高的真实度;我们的方法可以很容易的训练一个我们想要的模型,只需要文本描述,非专业人士也可以很容易的提供这样的文本;
47、受chenlin meng等人【6】的启发,我们的方法可以求解指定的时刻t0∈(0,1),我们从采样空间种采样的图像作为初始化的开始时间t0,这样我们可以生成理想的图像并且保留更多源图像的纹理特征,并且能在损失函数的限制下能更接近真实的图像;我们的采样过程表示如下:
48、
49、我们使用sde-rae(xsty;t0,θ)
50、来表示上述逆向过程,将采样空间种的风格图像作为sde-rae采样的起始点,这里用t0表示,将标准差为的高斯噪声添加到风格图像中,然后进行采样;最终得到目标图像x0。
51、作为优选,所述步骤s106中,在现实中,用户提供的风格图像通常与真实图像不一致,有些图像甚至完全不属于自然界,必须控制输出的真实程度;我们注意到,对于进过适当训练的reverse sde模型,用户的输入过于抽象时就会出现重建生成的图像有很严重的失真,为了实现高保真重建,我们采用content loss损失函数来尽量解决这个问题,受tengfei wang等人【15】的启发,我们使用自适应失真对齐弥合了生成图像和源训练输入图像之间的差距,改善了生成质量;
52、lcon=|ada(x-xsty)-ada(xrec-xsty)|+γ
53、其中ada是自适应失真对齐,x是原始数据集输入图像,xsty是风格图像,xrec是重建图像,γ是常数偏执项避免损失值过小或过大;
54、我们使用lpips距离【16】来判定输出图像与网络输入图像之间的偏差,它是图像深层特征的加权l2距离,已经被证实和人类感知有着极大的相似性,换句话说lpips的感知基本可以取代人类的感知;在训练过程中,我们使用基于vgg特征的lpips距离,这样做的目的是减少基于alexnet特征的lpi ps距离评估中的偏差,我们使用lpips距离来控制去噪扩散生成的图像和输入之间的差异性;损失函数如下:
55、lsim=dlpips(sde-rae(xsty;t0,θ)-x)
56、受deng et al【81】等人的启发,身份鉴别损失用于防止不必要的偏差,并保持对象的身份标识;我们在人脸图像处理的情况下我们使用身份鉴别损失,损失函数如下:
57、lid(xsrc,x0)=λidl(xsrc,sde-rae(xsty;t,θ),xsrc)
58、其中xsrc是数据集原始输入图像,xsty是采样空间中的风格图像,x0是reverse sde生成的图像,我们将原始图像xsrc和自身的向量表示进行点积运算,然后将reverse sde生成的图像x0和原始输入图像xsrc进行点积运算,然后计算它们的差值,运算公式如下:
59、
60、其中
61、表示向量的点积运算,计算它们之间的身份损失,避免不必要的偏差;
62、总的重建损失为:
63、lrec=λl2l2+λsimlsim+λidlid+λconlcon
64、其中λ是超参数,决定了损失函数在参数训练中的权重。
65、作为优选,所述步骤s107中,clip【11】是一个强大的跨模态预训练模型,他可以学习自然语言和视觉概念的联合嵌入,预训练clip中的文本编码器和视觉编码器可以将数据集中的文本和图片匹配起来嵌入到相同的语义空间中;在我们的方法中,我们使用了一个预训练的clip模型作为我们的风格指导图像的嵌入模型;受(patashnik et al.【82】;galet al.【83】)等人的启发,我们使用一种风格图像引导的全局clip损失,将引导reversesde朝着风格图像的方向采样和扰动;全局损失如下
66、lglobal(x0,tsty)=dclip(x0,tsty)
67、其中x0是生成图像,tsty是风格图像的文本描述,dclip计算去噪扩散网络生成的图像和文本描述在clip嵌入空间中的余弦距离,然而,当使用这种全局clip损失时,输出质量往往会受到破坏,并且在优化过程中稳定性较低,为了解决这个问题,stylegan-nada[14]提出了一种定向clip损失,它将源和输出的文本图像对之间的clip空间方向对齐;因此,我们还采用了定向clip损失,即
68、δt=etext(token(tsty))-etext(token(tsrc))
69、δi=eimg(token(sde-rae(xsrc;t,θ)))-eimg(token(xsrc))
70、
71、其中ei和et分别是clip的图像编码器和文本编码器,tsty是编辑目标图像的文本描述,、tsrc是源图像的文本描述;已知方向clip引导的图像编辑对模式折叠问题具有鲁棒性.通过将图像之间的方向与文本之间的方向对齐会生成和文本相关的图像。
72、作为优选,所述步骤s108中,celeba-hq【20】包含了超过30,000张分辨率为1024x1024的人像图片,在我们将其resize为256x256,图片都包含了40个属性标注,例如年龄、性别、头发颜色、面部表情等;这些标注可以用于训练机器学习模型,进行面部识别、属性分类等任务;
73、与celeba数据集不同的是,celeba-hq中的图片是通过对celeba数据集中的图片进行逐步上采样得到的;因此,celeba-hq中的每张图片都有与celeba相同的属性标注,可以更好地用于训练和测试面部识别算法;
74、大规模场景理解the large-scale scene understanding(lsun)挑战旨在为大规模场景分类和理解提供不同的基准;lsun分类数据集包含餐厅、卧室、教堂等10个场景类别;其中,lsunbedroom【21】数据集是lsun中最受欢迎的一个子数据集,包含了超过300万张真实卧室场景的图像;验证数据包括300张图像,测试数据每个类别有1000张图像;
75、这些图像来自于各种房地产网站和在线酒店预订平台的真实照片;这些照片经过了分类和裁剪,并被缩放为256x256像素大小,以方便进行图像处理和机器学习算法的训练和评估;我们的方法在3块nvidia rtx3090 gpu和一块nvidia rtx a6000gpu进行实验,我们使用pytorch深度学习框架,在重建过程中我们设置patc h size为4我们的λid为0.1,λl2为1.0,λsim为0.7,λcon为0.1,我们设置的最大采样步数t为500;我们使用的学习率为5e-4,总的迭代次数为10000,每50次迭代进行一次学习率衰减;在风格编辑过程中,我们使用单张图像和单个文本进行编辑,我们选用迭代采样次数为400,我们采用λs_enh=1;只需要我们的crop size为32.值得注意的是,当λs_enh=0时,图像将不会有任何改变,即编辑操作退化为图像inversion。
76、本发明的有益效果是:本发明涉及基于图像重建和编辑的融合语义增强clip的扩散网络,具有在不增加编码器的情况下有优秀重建能力和独特的风格编辑能力,在具体的使用中,与传统的基于图像重建和编辑的融合语义增强clip的扩散网络相比较而言,本基于图像重建和编辑的融合语义增强clip的扩散网络具有以下有益效果:
77、提出了一个基于reverse sde的基于得分匹配函数的图像重建和编辑生成框架,该框架有着卓越的图像重建能力和图像的风格编辑能力,我们的语义增强方法可以实现高质量的编辑。我们的工作有助于研究人员更好的理解现有的方法,并且极大的推动了现在去噪扩散网络图像处理相关的研究,我们的方法可以很容易的训练,只需要相应的文本描述就能实现相应的图像操作。我们的方法能生成具有真实感的图像,可以保留图像的纹理特征,在全局风格编辑的情况下也能保留源图像的轮廓信息,这都是之前的方法很少能达到的。和基于生成对抗网络的图像处理技术不同,我们在面对不同放个的图像时不需要额外的算法辅助或者数据集辅助。特别适用于重建损失难以设计和风格数据集难以获得的任务。这就使得相关工作可以很方便实现。
- 还没有人留言评论。精彩留言会获得点赞!