一种多源异构POI数据快速去重方法与流程
本发明涉及lbs位置服务,具体涉及一种多源异构poi数据快速去重方法。
背景技术:
1、随着信息技术的不断发展,位置信息的来源更加广泛,数据更新更加频繁,合理使用位置信息对相关分析和决策具有重要意义,poi数据作为位置信息的重要载体,直接关系着位置信息的质量,是进行位置信息研究的重要参考依据,针对多源异构的poi数据,如何对其进行高效融合已然业界亟须解决的问题之一:
2、目前,poi数据融合的方法,主要包括基于空间位置、非空间属性、本体以及空间位置和非空间属性相结合的方法,其中,比较经典的poi融合算法主要有四种:基于片面最近邻连接算法的poi融合技术、基于加权的多属性相似度的poi融合方法、基于距离类别的poi融合技术和基于聚类和索引的poi融合技术;
3、基于片面最近邻连接算法的poi融合技术通过对象的空间位置来寻找正确的融合集,这种算法虽然操作简单,但由于只考虑了空间位置而没有考虑非空间属性,导致出现不准确的融合结果;
4、基于加权的多属性相似度的poi融合方法,该方法将名称相似度、距离相似度和地址相似度分别赋予不同的权重,通过计算总体相似度,并判断总体相似度是否大于某个阈值来判别两个poi是否为同一个,此方法理论简单,便于操作,但它面临着一个重要难题:如何确定不同属性的权重?人为确定权重,主观因素较强,会导致融合之后的数据结果准确性不高;
5、基于距离类别的poi融合方法,此方法主要分成三个阶段:初步筛选阶段、排除阶段和补充阶段,初步筛选阶段使用相互最邻近算法,排除阶段和补充阶段使用jaro-winkler算法,这些算法操作困难,时间复杂度比较大,适用性低,
6、基于聚类和索引的poi融合技术,通过聚类的方式进行poi聚合,此类方法适合做离线计算,很难对原有的poi簇进行实时修改,实时维护库的成本很高,此外,更新新的数据,必须灌入所有的数据、全部计算完成后,才能返回新的聚类结果,新poi的实体链接关系不能实时计算,通过建立索引的方式缩小比较候选集,但这种方式存在“索引粒度”的问题,即如果设定的搜索粒度太小,本应该实体链接的两个poi不能链接到一起,这会降低召回率,反之,返回的疑似候选集太大,每个poi计算与之实体链接的poi的时间会变得很长,工程实现的压力会增大,通过字符索引很难控制索引的粒度;
7、因此本发明提供一种多源异构poi数据快速去重方法。
技术实现思路
1、鉴于上述现有存在的问题,提出了本发明。
2、因此,本发明目的是提供一种多源异构poi数据快速去重方法,解决了lbs位置服务的问题。
3、为了实现上述目的,本发明提供如下技术方案:
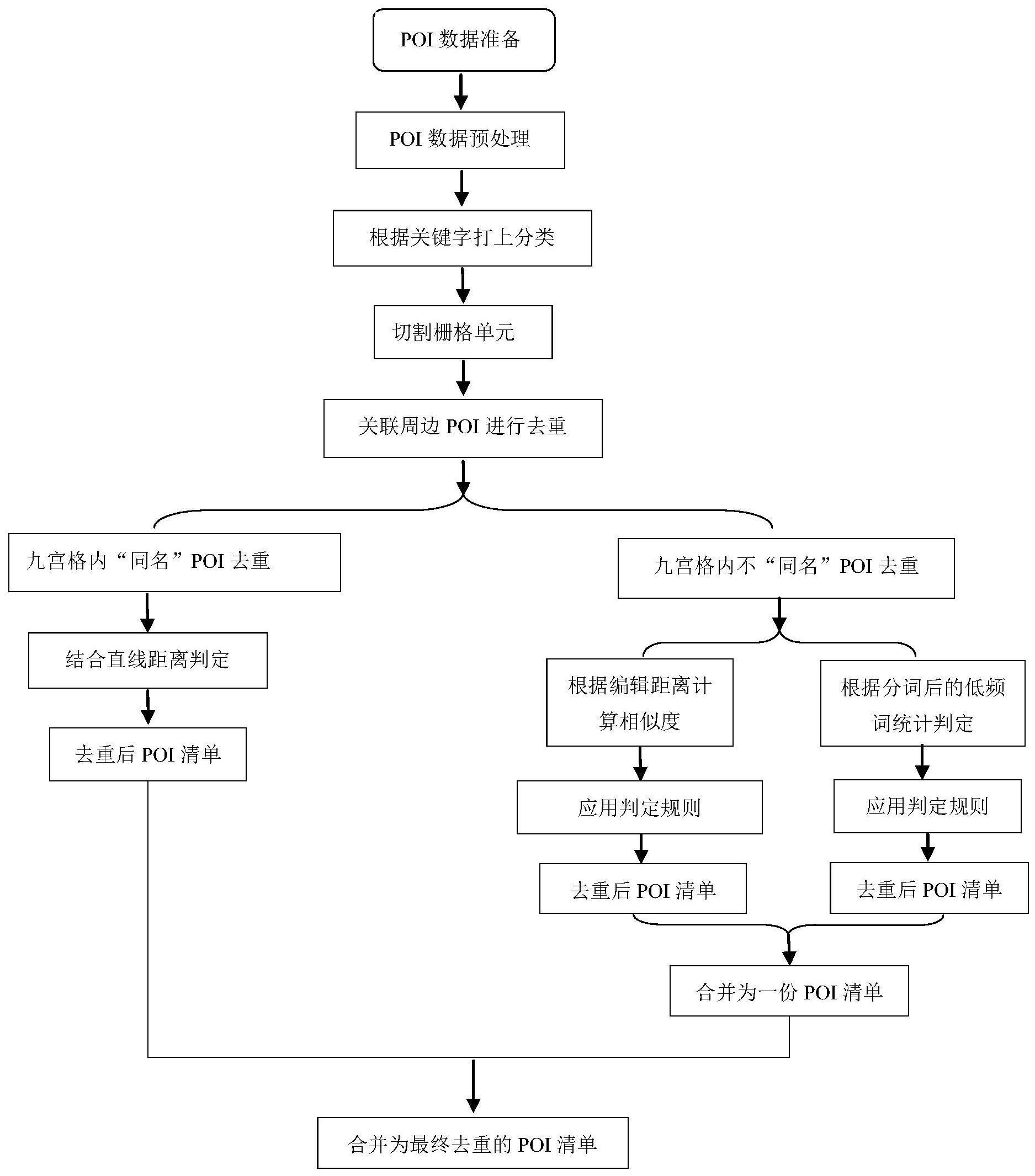
4、一种多源异构poi数据快速去重方法,包括数据预处理、栅格索引以及九宫格三大模块:其中数据预处理包括以下步骤:
5、针对poi名称,对其进行分词、去除停用词,统计词频,得到词频向量,进而计算整个数据库中的词频;
6、针对poi坐标,常用来源的poi坐标系有:gcj02、wgs84、bd09,将其统一转换至gcj02坐标系。
7、进一步的,所述栅格索引主要包括以下内容:
8、栅格索引,为降低计算量,将地理坐标系分割为矩形栅格,建立栅格与poi坐标之间的反向索引,
9、栅格索引为计算公式为
10、
11、
12、其中,lgi为poi中i的经度,lti为poi中i的维度,px,py分别为东西方向和南北方向上的栅格线密度,最终,xni,yni为poi中i的栅格索引坐标,以及为向下取整函数。
13、进一步的,所述九宫格模块包括有两个小模块,分别为九宫格内“同名”poi数据的去重、九宫格内“不同名”poi数据的去重以及poi数据合并三大操作步骤,其中的九宫格模块,包括以下内容:
14、九宫格,也即选定中心栅格i(xni,yni),对于任意其他栅格j(xnj,ynj),若栅格i,j间的绝对值距离小于等于2,由中心栅格i和所有满足条件的所有栅格j,被称为一个“九宫格”,
15、{i,j||xni-xnj|+|yni-ynj|≤2}
16、一个“九宫格”包含以任意一格为中心,与其相邻的上、下、左、右、左上、左下、右上、右下的3×3九个栅格,
17、若poi存在至少一个镜像poi,则该镜像poi的地理坐标与原始poi坐标距离一定小于栅格线密度,也即一定落在以原始poi为中心的“九宫格”内,故而一个九宫格是一个基本去重单元。
18、进一步的,所述的九宫格内“同名”poi数据的去重主要包括以下内容:
19、对于九宫格内“同名”且直线距离小于300m的poi,判定为同一个poi,并进行合并,即当两个poi数据的名称完全相同且距离足够近的时候,就能够认为这两个poi为同一个,名称完全相同的情况主要分为三种:
20、第一种:两个poi名称均为中英文组合时,中文部分和英文部分分别对应相同;
21、第二种:两个poi名称一个只有中文名,一个是中英文组合时,中文部分对应相同;
22、第三种:两个poi名称中一个只有英文名,一个是中英文组合时,英文部分对应相同。
23、进一步的,所述九宫格内“不同名”poi数据的去重则是对于不同名数据,主要采用编辑距离和分词后的低频词词频统计两种方法,主要包括以下内容:
24、s1、编辑距离
25、编辑距离是针对两个字符串之间差异程度的量化测量,测量方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串,记两个字符串分别为i和j他们的字符串长度分别为ni和nj,它们之间的编辑距离为ei,j,相似度为simi,j根据编辑距离的含义,可以定义文本相似度公式如下:
26、
27、其中,n=max{ni,nj},在此基础上,再将名称分为有包含关系和其他情况两类;
28、s2、当名称有包含关系时,名称有包含关系又可分为“顺序包含”与“乱序包含”,记两个poi之间的名称相似度为simi,j,直线距离为di,j,相同汉字个数为ni,j,判定规则如下:
29、当两个poi的名称为“顺序包含”时,若名称相似度大于等于0.8并且直线距离小于等于250米时;或者两个poi之间的直线距离小于30米、相同汉字个数大于等于2个;或者两个poi之间的直线距离小于50米、相同汉字个数大于等于3个时,即可认为是同一个poi;
30、当两个poi的名称为“乱序包含”时,若名称相似度大于等于0.8并且直线距离小于等于150米;或名称相似度大于等于0.7并且直线距离小于等于100米;或两个poi之间的直线距离小于10米、相同汉字个数大于等于4个时,即可认为是同一个poi;
31、s3、当为其他情况,则考虑到收集的poi数据复杂性,两个poi的名称除了“同名”、“包含”关系外还存在其他各种情况可以判定两个poi为同一个,最常见的主要有三类:
32、第一类,开头有超过3个连续数字相同并且直线距离小于等于100米;
33、第二类,开头超过4个连续的英文相同,并且直线距离小于等于150米;
34、第三类,考虑到谐音字的情况,当两个poi名称的中文拼音完全相同时,也可认为是同一个poi;
35、s4、在进行低频词统计,利用预处理过程中的分词数据,当频数低于75时,认为其为“低频词”,当两个poi有一个相同的“低频词”并且直线距离小于500米时对其进一步进行考察,主要有以下四种情况:
36、相同“低频词”个数大于等于2个,直线距离小于等于100米前2个字相同,直线距离小于等于100米;
37、存在包含关系,直线距离小于等于100米;
38、地址中除“街”、“路”、“号”后的关键词高度相似,直线距离小于等于500米;
39、当满足其一时,即可判定两个poi为同一个。
40、进一步的,所述poi数据合并步骤主要包括以下内容:
41、采取最小匹配的原则进行融合:若一个poi被两种方法同时判定为重复poi,则该poi为重复poi,予以剔除;若一个poi被至多一个方法识别为重复poi,则该poi不为重复poi,予以保留,然后将同名与不同名两部分去重后得到的数据集取并集,得到最终的去重后的结果。
42、在上述技术方案中,本发明提供的技术效果和优点:
43、1、本发明采用了编辑距离和“低频词”统计两种方法处理非同名poi。在以往的专利、文献中,关于poi去重的方法几乎不涉及“低频词”统计的方法。两个不同poi同时拥有相同“低频词”的概率很低,当它们拥有的“低频词”个数不止一个,并且直线距离很近时,能够在较大的程度上认为这两个poi是同一个。并且“低频词”统计的方法原理简单,便于操作。
44、2、本发明采用了名称相似度、直线距离、地址相似度三个指标综合判断,将三个指标与一定的标准进行比较,并根据三个指标之间的约束制定规则,而不是像以往的方案中人为设定权重来指定规则,一定程度上减小主观因素的影响,提高了去重的结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!