一种半结构化文档数据存储方法、介质和系统与流程
本发明属于数据建模,具体而言,涉及一种半结构化文档数据存储方法、系统和介质。
背景技术:
1、随着信息化建设的快速普及与推进,计算机应用技术在各个行业中得到了广泛的应用,在公司和企业内部,拥有海量的文档资产,具有非常高的价值。从海量的文档数据中获取有效的信息通常是非常耗时的,需要花费高昂的成本。当前,海量文档的有效信息检索是高价值、高成本、低利用率的,如何高效的从非结构化的数据中获取有效的信息是需要亟待解决的。
2、公开号为cn107122441a的中国发明专利(申请号:cn201710268964.8)公开了一种基于大数据的通信数据检索及呈现方法,属于通信网络运维技术领域,在不改变原有系统软件架构的情况下,通过数据整合,聚合设备行为、运维行为、用户行为以及非结构化数据,引入搜索引擎技术,实现数据的快速搜索和应用的快速到达;包含海量通信数据检索和应用快速到达两个部分,全文的数据检索包括索引创建和搜索索引两个过程,索引创建将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程;搜索索引得到用户的查询请求,搜索创建的索引,然后返回结果。本发明减少在数据检索上花费的时间,还能为数据维护、应用提供快速入口。
3、上述发明无法使文档之间自动建立联系,不能高效地从大量文档的非结构化的数据中获取有效的信息。
技术实现思路
1、有鉴于此,本发明提供一种半结构化文档数据存储方法、系统和介质,能够使文档之间自动建立联系,高效地从大量文档的非结构化的数据中获取有效的信息。
2、本发明是这样实现的:
3、本发明第一方面提供一种半结构化文档数据存储方法,其中,包括以下步骤:
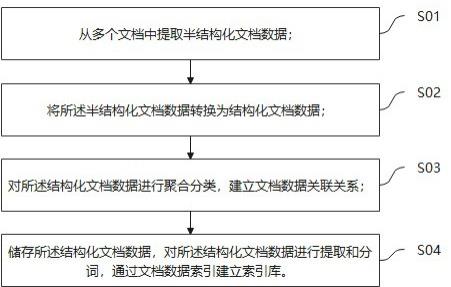
4、s01:从多个文档中提取半结构化文档数据,所述半结构化文档数据是无法直接转化为数据对象格式进行存储的文档;
5、s02:将所述半结构化文档数据转换为结构化文档数据,所述结构化文档数据为能够通过关系型数据库的二维表结构来逻辑表示数据结构,并且数据结构变化不会经常性发生;
6、s03:对所述结构化文档数据进行聚合分类,建立文档数据关联关系;
7、s04:储存所述结构化文档数据,对所述结构化文档数据进行提取和分词,通过文档数据索引建立索引库。
8、在上述技术方案的基础上,本发明的一种半结构化文档数据存储方法还可以做如下改进:
9、其中,所述对所述结构化文档数据进行聚合分类,建立文档数据关联关系的方法包括knn算法自动文档数据关联法和决策树手动文档数据关联法;
10、其中,所述knn算法自动文档数据关联法的具体步骤为:
11、s11:用所述结构化文档数据作为关联度knn算法模型的输入数据;
12、s12:采用关联度knn算法模型计算所述结构化文档数据的点与所有已知数据点之间的距离,得到距离集合;
13、s13:对所述距离集合按照从大到小的顺序进行排序;
14、s14:在排序好的所述距离集合中,选择前k个元素;
15、s15:所述前k个元素对应的数据点类别一致时,则进行s16,所述前k个元素对应的数据点类别不一致时,则进行s17;
16、s16:将所述前k个元素对应的数据点类别作为输出数据,即为该所述结构化文档数据的预测分类;
17、s17:将所述前k个元素中权重最高的所述元素对应的数据点类别作为输出数据,即为该所述结构化文档数据的预测分类;
18、所述决策树手动文档数据关联法的具体方法为:
19、s21:以数据集为决策树算法的输入数据,所述数据集为所述结构化文档数据;
20、s22:判断所述数据集是否为同一类别,如果是同一类别则进行步骤s223.1,如果不是同一类别则进行步骤s223.2;
21、s233.1:选择此类别;
22、s234:输出叶节点,所述叶节点为所述结构化文档数据的预测分类;
23、s235:结束分类;
24、s223.2:提取特征集合a,进行步骤s223.3;
25、s223.3:判断所述集合a是否为空集,如果是空集则进行s223.4.1,如果不是空集则进行s223.4.2;
26、s223.4.1:选择所述数据集中占比最多的类别,然后进行s234;
27、s223.4.2:所述特征集合的取值是否唯一,如果唯一,则进行s223.4.1,如果不唯一,则进行s223.5;
28、s223.5:人工输入最优划分特征a,进行s223.6;
29、s223.6:进行特征值遍历,如果所述特征值遍历结束进行s235,如果所述特征值遍历没有结束,则进行s223.7;
30、s223.7:生成数据子集,进行s223.8;
31、s223.8:剔除所述数据子集中的所述特征a,进行步骤s223.9;
32、s223.9:输出删除子集,以所述删除子集作为所述结构化文档数据进行s21。
33、进一步的,所述从多个文档中提取半结构化文档数据的具体步骤为:
34、第一步:输入全部文档;
35、第二步:开始文档内容提取;
36、第三步:判断所述文档类型;
37、第四步:针对不同格式的所述文档采用不同的文档信息提取方式;
38、第五步:获得半结构化文档数据。
39、其中,所述将所述半结构化文档数据转换为结构化文档数据的具体步骤为:
40、第一步:对源端所述半结构化文档数据解析,获得多叉树结构数据;
41、第二步:将所述半结构化文档作为半结构化文档数据转化规则输入数据,输出所述结构化文档数据;其中,所述半结构化文档数据转化规则为树形规则,所述结构化文档数据为外键和主键相连组成的图表;
42、第三步:手动调整第二步获取的所述结构化文档数据,根据所述结构化文档数据的名称中的节点名称和类型增加同级节点、增加子节点、删除节点;增加同级节点,即在当前节点的父节点下增加一个同级节点;增加子节点,即在当前节点下增加一个子节点;删除节点,即删除当前节点或其子节。
43、其中,所述储存所述结构化文档数据,对所述结构化文档数据进行提取和分词,通过文档数据索引建立索引库的具体步骤为:
44、第一步:对所述结构化文档数据进行提取关键字和分词;
45、第二步:根据提取出的所述关键字或分词进行数据索引;
46、第三步:建立正排索引和倒排索引;
47、第四步:根据所述正排索引和所述倒排索引建立索引库。
48、本发明第二方面提供一种计算机可读存储介质,其中,包含存储有程序代码,所述程序代码运行时用于执行上述的半结构化文档数据存储方法。
49、本发明第三方面提供一种基于半结构化文档数据存储的系统,其中,包含上述的计算机可读存储介质。
50、与现有技术相比较,本发明提供的一种半结构化文档数据存储方法、系统和介质的有益效果是:解决了海量文档的有效利用问题,将海量文档的有效利用从高成本、高耗时、低利用率,转变为低成本、极低耗时、高利用率,实现了海量文档的准确、快速利用;提供一种半结构化数据自动转换为结构化数据的步骤和方法,使得文档内容变得有层次机构,且层次关系简单明了;提供一种海量文档关系网络的自动化构建步骤和方法,通过这种步骤和方法,有效解决了如何将海量文档建立关联关系的问题;提出了文档结构化数据及文档关系数据的存储和快速检索步骤和方法,解决了难以从海量文档中精准查询用户感兴趣的数据问题。
- 还没有人留言评论。精彩留言会获得点赞!