基于分层强化学习的雷达干扰决策与参数优化方法及装置
本发明涉及到雷达电子战,尤其涉及到一种基于分层强化学习的雷达干扰决策与参数优化方法及装置。
背景技术:
1、干扰决策是雷达对抗领域中的关键,自始至终都是研究的热点和难点。雷达干扰决策主要是干扰方对电磁环境进行态势感知,获取敌方雷达的工作模式,通过合理分配己方的干扰资源,进而选择最佳干扰样式的过程。传统的干扰决策方法主要依靠大量先验信息和专家经验,将雷达参数信息与干扰知识库进行模板匹配,得出最佳干扰策略。随着数字t/r组件、数字波束形成等技术的成熟促使了多功能雷达的发展。在与人工智能结合后,多功能雷达可以实现探测、跟踪、制导等多种功能,具有一定的智能性。与之同时,多功能雷达往往都运用了诸如脉冲多普勒、脉内参数捷变、脉冲压缩等抗干扰技术,抗干扰性能得到增强。面对趋于智能化且抗干扰能力不断增强的多功能雷达,传统干扰方法对抗能力显著下降,越来越难以发挥作用。贯序决策从本质上解释了雷达干扰决策问题,即干扰方对电磁环境进行感知后合理分配己方的干扰资源,在变化的环境中边对抗边学习,不断更新策略。因此,强化学习方法的出现为雷达干扰决策提供了新思路。强化学习是一个通过智能体与环境进行交互,不断学习不断更新模型从而找寻最优策略的学习方法。
2、目前,强化学习方法与雷达干扰决策相结合诞生了多种针对多功能雷达的强化学习干扰决策方法,能对环境进行态势感知并针对雷达的工作模式采取相应的干扰样式。然而,当前的强化学习干扰决策方法依然存在局限性:(1)在现有的基于强化学习的干扰决策方法中,并没有同时考虑多功能雷达的两种常用措施,即工作模式切换和脉冲参数敏捷性调节。只单一考虑了雷达的工作模式或者某一工作模式下的脉冲参数,容易产生主观或局部最优干扰策略;(2)针对雷达工作模式下的脉冲参数进行干扰决策时,参数考虑的维度不够,并且没有在连续的参数空间上进行选择,容易导致干扰策略陷入局部最优的困境,同时不能实时地自适应优化干扰参数。
技术实现思路
1、本发明旨在解决上述涉及问题中的至少一个问题。
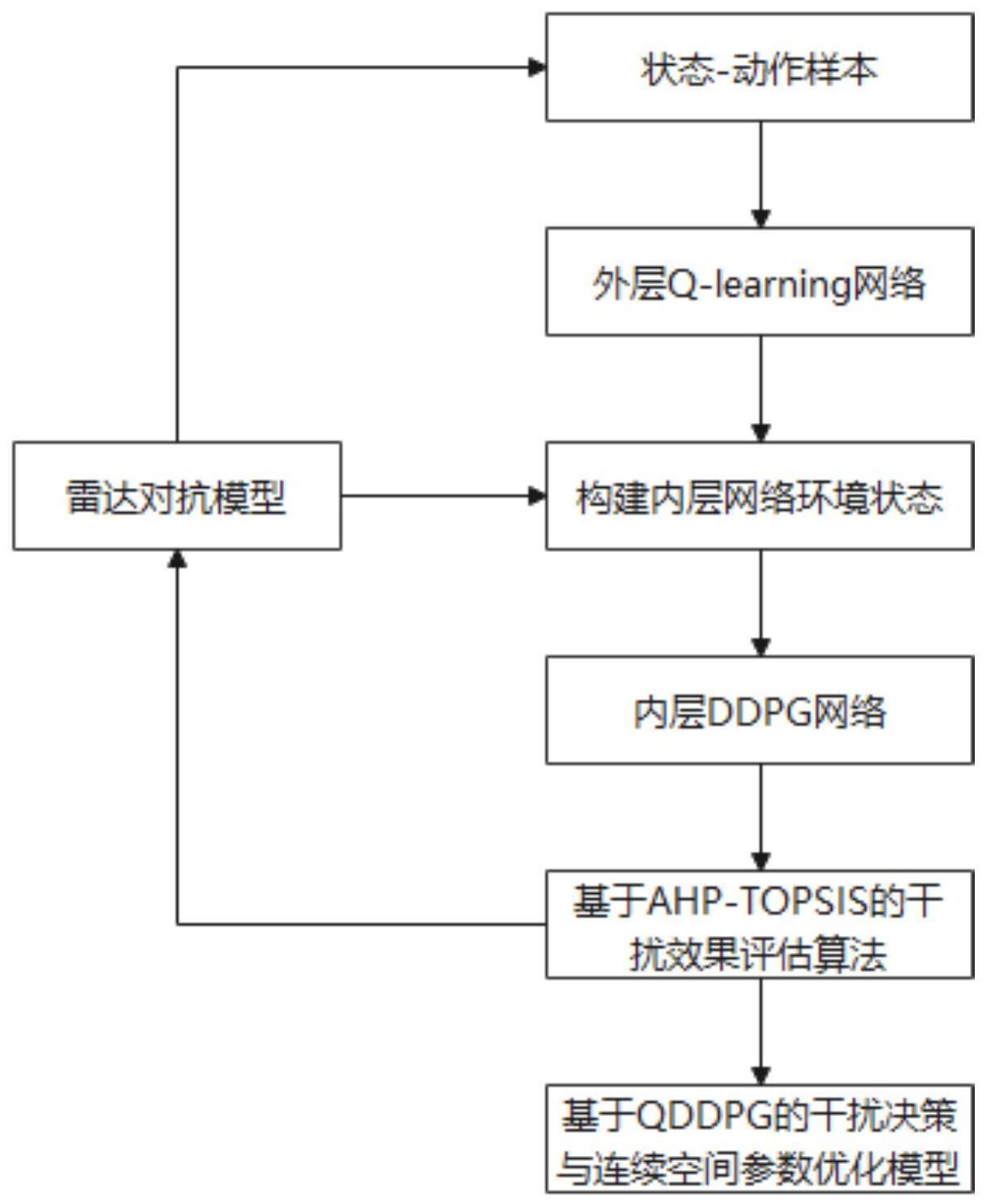
2、根据本发明的一个方面,本发明提供了一种基于分层强化学习的雷达干扰决策与参数优化方法,包括以下步骤:
3、s1:构建雷达对抗模型;
4、s2:根据雷达对抗模型,建立雷达工作模式和干扰样式的空白q值表,通过两者交互收集状态-动作样本;
5、s3:根据收集的状态-动作样本优化贝尔曼最优方程,外层q-learning网络根据动作价值函数计算选择当前环境状态下的最优干扰策略;
6、s4:将通过雷达脉冲参数估计得到雷达脉冲参数向量作为内层ddpg网络的环境,并将外层q-learning网络得到的最优干扰策略映射到内层ddpg网络上;
7、s5:构建基于连续参数空间的内层ddpg网络模型,将连续参数空间作为内层ddpg网络的动作进行选取,深层次对外层q-learning网络得到的最优干扰策略进行干扰脉冲参数优化;
8、s6:使用基于ahp-topsis的干扰效果评估算法对优化后的干扰脉冲参数进行干扰效果评估,将干扰效果评估结果作为环境反馈更新雷达对抗模型;
9、s7:重复s2至s6,直至到达目标雷达状态,得到基于分层强化学习的qddpg干扰决策与连续空间参数优化模型。
10、进一步地,步骤s1中,所述雷达对抗模型包括:多功能雷达模型和认知干扰机模型;
11、所述构建雷达对抗模型包括:
12、构造多功能雷达模型,多功能雷达的i种工作模式记为雷达的工作模式根据信号干扰无线电在两个相邻波束驻留期间自适应切换;
13、构造认知干扰机模型,认知干扰机的j种干扰样式记为认知干扰机自适应地为每一干扰样式的每个脉冲选择参数。
14、进一步地,步骤s2包括:
15、当在k时刻获得的雷达工作模式时,认知干扰机选择干扰样式
16、干扰样式的计算表达式为:
17、
18、其中,qo为外层q-learning网络的动作价值函数;mj表示动作空间;当k+1时刻获得新的雷达工作模式时,更新外q表中的的数学模型为:
19、
20、其中,α∈(0,1]为外层强化学习的学习率,表示q值的更新步长;γ∈(0,1]表示外层强化学习的折扣因子;rout(k+1)表示外层q-learning网络在k+1时刻计算的奖励,该值根据基于ahp-topsis的干扰效果评估算法求得;
21、将雷达工作模式和干扰样式分别被视为环境输入状态和智能体的干扰动作,建立雷达工作模式和干扰样式的空白q值表,然后两者交互收集状态-动作样本。
22、进一步地,步骤s3包括:
23、根据收集到的状态-动作样本,认知干扰机使用贪心算法,以概率ε随机在动作空间选择干扰样式,以概率1-ε根据动作价值函数计算选择当前环境状态下的最佳干扰样式;
24、外层q-learning网络执行干扰策略,得到环境奖励r以及下一状态s′;通过不断与环境进行交互,迭代更新动作价值函数q(s,a);达到收敛时取当前状态下最大价值函数对应的动作即为最优干扰策略;
25、动作价值函数更新迭代的表达式为:
26、
27、其中,s为当前环境状态;a为当前状态下采取的动作;s′、a′分别为下一状态和采取的动作;γ∈(0,1]表示平衡即时回报和长期回报的折扣因子;α∈(0,1]表示模型更新迭代的学习率,是一个随交互次数增大而逐渐减小的函数,目的是加快动作价值函数的迭代收敛;表示下一状态动作价值函数最大估计;表示时间差分目标;表示时间差分误差,通过学习时间差分误差迭代更新q(s,a)。
28、进一步地,步骤s4包括:
29、将外层q-learning网络选择的干扰样式映射到内层ddpg网络上;
30、从环境观测到雷达脉冲参数向量s(n)=[fr(n),br(n),prir(n),pwr(n),pr(n)];
31、其中,载波频率记为带宽记为脉冲宽度记为pri记为表示第(n-1)个和第n个雷达脉冲上升沿之间的时间;发射功率记为
32、内层ddpg网络分别取[fr(n),br(n)]和[prir(n),pwr(n)]作为内层ddpg网络的环境输入状态。
33、进一步地,步骤s5包括:
34、以actor-critic算法框架结合dqn的经验回放机制构建由actor online策略网络和target策略网络、critic online q网络和target q网络组成的ddpg算法模块,权重参数分别θμ、θμ′、θq、θq′;
35、内层ddpg的网络中的actor online策略网络权重参数θμ根据从经验池中抽样的小批量经验样本求得的损失函数进行更新;
36、损失函数更新迭代的表达式为:
37、
38、其中,si为当前的环境状态,ai为当前状态下选择的动作,θq为critic online q网络权重参数,n为批量梯度下降样本数;
39、该损失函数由critic online q网络求得;同时,critic online q网络权重参数θq也根据抽取的小批量样本经验求得的损失函数进行更新;
40、损失函数更新迭代的表达式为:
41、
42、其中,si为当前的环境状态,ai为当前状态下选择的动作,θq为critic online q网络权重参数,n为批量梯度下降样本数。由从环境观测得到的动作奖励ri与target策略网络的输入si+1以及输出ai+1,通过计算得到target q网络的td目标q值yi;
43、yi的计算公式为:
44、yi=ri+γq′(si+1,ai+1;θq′)
45、其中,γ为衰减因子,q′(si+1,ai+1;θq′)为下一步动作的价值,θq′为target q网络更新后的权重参数。
46、进一步地,步骤s6包括:
47、选取距离误差、速度误差、虚警概率和发现概率作为干扰效果的评估指标;
48、采用层次分析法将干扰效果评估过程分层简化,根据雷达任务特点主观的给出每个指标的重要性分值,从而设计各指标对于干扰效果的权重因子;
49、采用优劣解距离法对不同干扰策略的干扰效果进行量化对比;
50、将干扰效果评估结果作为环境反馈更新雷达对抗模型。
51、根据本发明的第二方面,本发明提供了一种基于分层强化学习的雷达干扰决策与参数优化装置,包括以下单元:
52、对抗模型构建单元,用于构建雷达对抗模型;
53、外层q-learning状态-动作样本生成单元,用于根据雷达对抗模型,建立雷达工作模式和干扰样式的空白q值表,通过两者交互收集状态-动作样本;
54、干扰样式选择单元,用于根据收集的状态-动作样本优化贝尔曼最优方程,外层q-learning网络根据动作价值函数计算选择当前环境状态下的最优干扰策略;
55、内层ddpg网络环境状态生成单元,用于将通过雷达脉冲参数估计得到雷达脉冲参数向量作为内层ddpg网络的环境,并将外层q-learning网络得到的最优干扰策略映射到内层ddpg网络上;
56、干扰参数优化单元,用于构建基于连续参数空间的内层ddpg网络模型,将连续参数空间作为内层ddpg网络的动作进行选取,深层次对外层q-learning网络得到的最优干扰策略进行干扰脉冲参数优化;
57、干扰效果评估单元,用于使用基于ahp-topsis的干扰效果评估算法对优化后的干扰脉冲参数进行干扰效果评估,将干扰效果评估结果作为环境反馈更新雷达对抗模型;
58、雷达干扰决策单元,用于重复上述单元的操作,直至到达目标雷达状态,得到基于分层强化学习的qddpg干扰决策与连续空间参数优化模型。
59、本发明提供的技术方案所带来的有益效果是:
60、综合考虑雷达工作模式的切换和脉冲参数的敏捷性调节,提出一种连续参数空间分层强化学习框架,以提高雷达对抗中干扰决策的性能;提供了一种基于分层强化学习的雷达干扰决策与参数优化方法,同时解决干扰样式决策、干扰脉冲参数自适应优化的问题;提供了一种基于ahp-topsis的干扰效果评估方法,对评价指标进行重要性分值加权以获得合适的干扰效能评估值,同时将干扰效果评估结果作为环境反馈更新雷达对抗模型。
- 还没有人留言评论。精彩留言会获得点赞!