本发明属于知识图谱,具体涉及一种基于图稀疏表征的知识图谱数据分解与压缩方法。
背景技术:
1、随着信息的爆炸式增长与人工智能的快速发展,知识图谱数据作为人类知识信息的一种智能化、结构化的表示方式,引起了学术界和工业界的广泛关注。知识图谱通过描述真实世界中实体及实体之间的关系,进一步使计算机去学习人类在生活中不断积累的知识,使其具有处理真实信息的能力。基于知识图谱的信息处理技术通过知识图谱来存储信息,通过对知识图谱进行嵌入,实现信息的智能处理,如智能信息检索、信息问答、决策等。
2、知识图谱是对人类所学知识的结构化表示方式,它以<实体,关系,实体>三元组来表示实体之间的联系,以此构成一个复杂的网络结构。随着信息的爆炸式增长,知识图谱的网络数据越来越庞大,结构也越来越复杂,导致研究人员对知识图谱数据和结构的分析与理解更加困难。现有的知识图谱嵌入方法主要是将实体和关系映射到低维向量空间,通过实体与实体映射到低维向量空间之后的算术距离来表示实体之间的联系。但是将知识图谱进行嵌入后的低维向量无法表示实际的物理含义,不能直接展示知识图谱所包含的知识和特征,也无法帮助研究人员对知识图谱的结构进行抽象与理解,增加了研究人员对知识图谱的分析难度。
3、知识图谱表征的目的是从结构复杂的知识图谱数据当中识别并挖掘构成知识图谱的基础结构,并通过对这种基础结构的组合来重构出分解之前的原始知识图谱。针对大规模知识图谱数据层本身可被表示为异质图的特性,可以通过复杂网络异质图分解和压缩方法对知识图谱的分解方法进行研究,通过图分解方法将知识图谱分解为简单图结构的集合,以此展示知识图谱的基础结构特征,帮助研究人员深入理解较为复杂的知识图谱模式层中知识之间的结构和特征。
4、现有的复杂网络压缩方法通过k-svd或布尔矩阵分解来实现对网络所生成的矩阵的分解。k-svd方法从数学的角度出发对矩阵进行分解,在性能及算法时间复杂度上有较好的表现,但分解之后的字典会存在负数、小数,其物理意义是可不解释的。布尔矩阵分解方法将矩阵内的值限制为0或1,相比于k-svd方法,该方法提高了矩阵分解的可解释性,同时提高了原子的真实性。但布尔矩阵分解对知识图谱数据的兼容性较差,该方法所使用的邻接矩阵仅能包含边以及边的属性信息,这就导致对网络的分解和压缩会丢失节点的属性信息。
技术实现思路
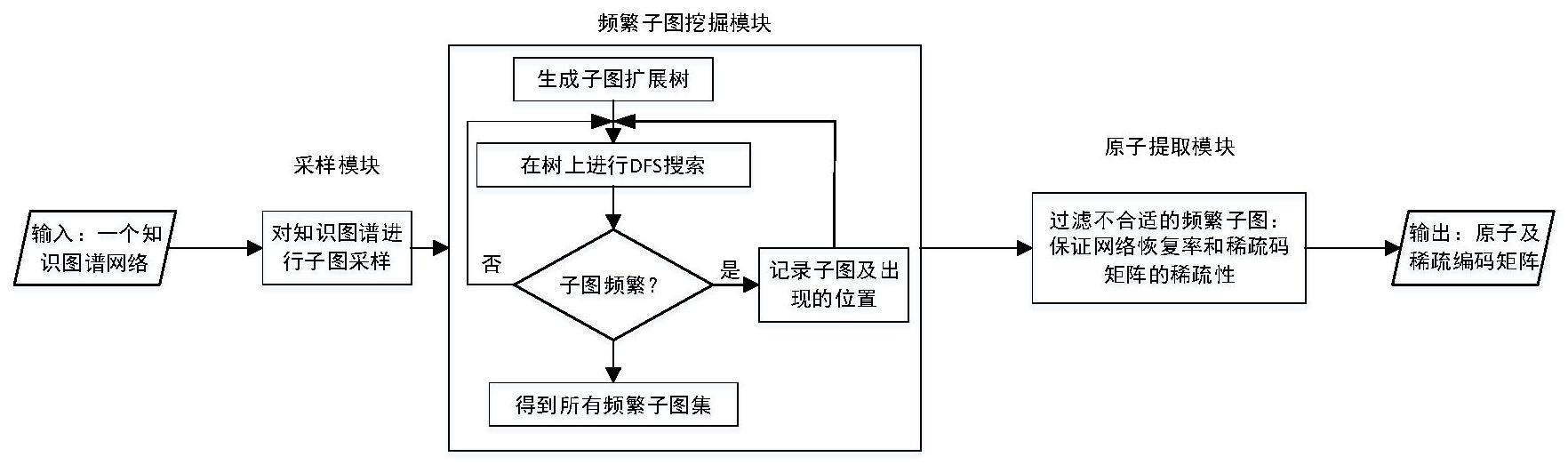
1、为解决上述技术问题,本发明提出了一种基于图稀疏表征的知识图谱数据分解与压缩方法,直接从知识图谱本身出发,将知识图谱采样为一系列同类型子图组成的事务图集,以频繁子图挖掘的图扩张思想为引导,在知识图谱事务图集中寻找真实存在的基本结构模式,更加显著地反映原始知识图谱数据的结构特征,同时提出一个原子过滤方法,在提取出知识图谱频繁子结构的基础上,将冗余的子结构去除来获得知识图谱网络的原子结构,以实现更好的知识图谱数据压缩效果。
2、本发明采用的技术方案为:一种基于图稀疏表征的知识图谱数据分解与压缩方法,具体步骤如下:
3、s1、输入一个知识图谱,对输入的知识图谱网络数据进行子图采样,将原始的知识图谱网络数据切割成一组知识图谱事务图集;
4、s2、在步骤s1得到的知识图谱事务图集上进行频繁子图挖掘,构建出以模式扩展为基础的子图扩展树,在树上进行dfs深度优先搜索,逐个寻找频繁出现在知识图谱事务图集中的基础模式,对这些基础模式进行线性组合,完成知识图谱数据分解与压缩;
5、s3、对步骤s2挖掘出的频繁子图进行过滤,删除掉冗余的子结构,过滤不合适的频繁子图,输出原子及稀疏编码矩阵。
6、进一步地,所述步骤s1具体如下:
7、首先确定采样大小,以知识图谱中的每一个节点为中心,寻找其一阶、二阶邻接节点,若邻接节点的数目比采样大小更大,则进行随机选取。
8、其中,所述一阶邻接节点即直接相邻的节点,所述二阶邻接节点即邻接节点的邻接点。
9、选取中心节点、邻接节点之间的连边以及邻接节点、邻接节点内部之间的连边,构成一个事务图,进而构成一组知识图谱事务图集。
10、进一步地,所述步骤s2具体如下:
11、首先确认频繁子图的频繁阈值:支持度,在步骤s1得到的知识图谱事务图集上进行频繁子图挖掘。
12、然后构建子图扩展树,通过支持度参数,筛选出所有边标签属性中最频繁的一类,将这个单边子图作为子图树的根节点,不断添加边进行扩张,每扩张出一个更大的子图,就把新子图作为旧子图的子节点放在子图扩展树中,直到知识图谱事务图集的所有子图都被涵盖为止。
13、最后从子图扩展树的根节点出发,以深度优先遍历dfs的方式,遍历整个树的所有子图,每遍历到一个子图,检查子图出现在多少个事务图中,若出现的频率高于支持度参数,则认为这个子图是频繁的,将这个子图添加在频繁子图集中,同时记录这个频繁子图出现在哪些事务图中,继续向更深的方向遍历;若这个子图是非频繁的,则跳过这个子图以及后续的所有分支,向上层的方向进行回溯遍历,最终得到所有的频繁子图集。
14、进一步地,所述步骤s3具体如下:
15、s31、将步骤s2得到的所有的频繁子图按照遍历的先后顺序进行排序,使得所有的频繁子图总是以同一遍历路径上由小图到大图的顺序排列;
16、s32、依次取出每一个子图,将其作为模式,然后将其他的频繁子图作为目标进行对比,如果同时满足条件(a)和(b),则认为模式可被目标覆盖,则模式是可被过滤的冗余频繁子图,删除该频繁子图,最终得到过滤后的频繁子图,输出原子及稀疏编码矩阵,提高原子对原始知识图谱的特征表示能力;
17、其中,所述条件(a)和(b)具体如下:
18、(a)模式是目标的子图;
19、采取模拟匹配的方式,以目标中的每个节点为起始点,按照节点编号增加的方向和模式进行匹配,如果有其中一个起始点能够使目标的节点标签和边标签属性与模式的属性完全相同,则认为模式是目标的子图。
20、(b)模式和目标以一定的覆盖阈值共同出现;
21、在进行dfs深度优先遍历搜索的时候,每当遍历一个子图树的节点,就会在所有的事务图集中寻找该子图是否出现过,以此记录一个频繁子图出现在哪些事务图中,把出现的事务图集编号称为索引,若模式的索引在一定的误差范围内,即,100%-覆盖阈值,能被目标的索引所覆盖,则认为模式和目标在可接受的误差范围内共同出现。
22、本发明的有益效果:本发明的方法首先通过采样模块,以知识图谱中的每一个节点为中心进行子图采样,将一个知识图谱网络数据分割成一组知识图谱事务图集,在得到的事务图集上进行频繁子图挖掘,构建出以模式扩展为基础的子图扩展树,在树上进行dfs深度优先搜索,逐个寻找频繁出现在知识图谱事务图集中的基础模式,完成知识图谱数据分解与压缩,最后对挖掘出的频繁子图进行过滤,删除掉冗余的子结构,过滤不合适的频繁子图,输出原子及稀疏编码矩阵。本发明的方法将知识图谱数据表示为基础子结构的组合,压缩知识图谱数据,降低对知识图谱数据嵌入和分析难度,删除掉冗余子结构,提高对数据的分解和压缩效率。本发明的方法从图的角度出发对知识图谱数据进行分解与压缩,能较好地利用知识图谱中每个节点、边的属性信息,更具有直观效果,改善了现有网络压缩技术原子真实性不足且无法兼容知识图谱网络数据的缺点,提出的原子过滤方法,在保证知识图谱网络分解压缩准确率的前提下,将冗余的小原子尽可能去除,进一步提高原子对原始知识图谱的表示能力,提高对知识图谱数据的压缩效率。