数据分类方法、装置、电子设备及存储介质
本发明涉及计算机人工智能及数据处理领域,尤其涉及一种数据分类方法、装置、电子设备及存储介质。
背景技术:
1、随着信息交互越来越发达,这将会产生大量的数据,因此,如何对大量数据进行有分类是重要的问题。现有研究对er rule(证据推理规则)分类器的特征参考值和证据权重进行优化时,通常采用的是能够直接衡量分类效果的目标函数,比如最小化激活证据组合结果与样本实际类别信度分布的均方误差、最大化分类准确率或最小化分类错误率等,每次迭代中,这些目标函数的值均需要在计算出训练集每个样本的分类结果之后才能计算,即训练集中的每个样本都要执行过证据激活与组合步骤。特别是对于数据量较大时,其存在耗时较长、计算效率低下、分类结果有效性较差及稳定性不足的缺陷。
技术实现思路
1、本发明实施例的主要目的在于提出一种数据分类方法、装置、电子设备及存储介质,提高了数据分类的效率,同时在面对大量待分类数据时,具有耗时短、分类效果高、分类准确度高及高稳定性。
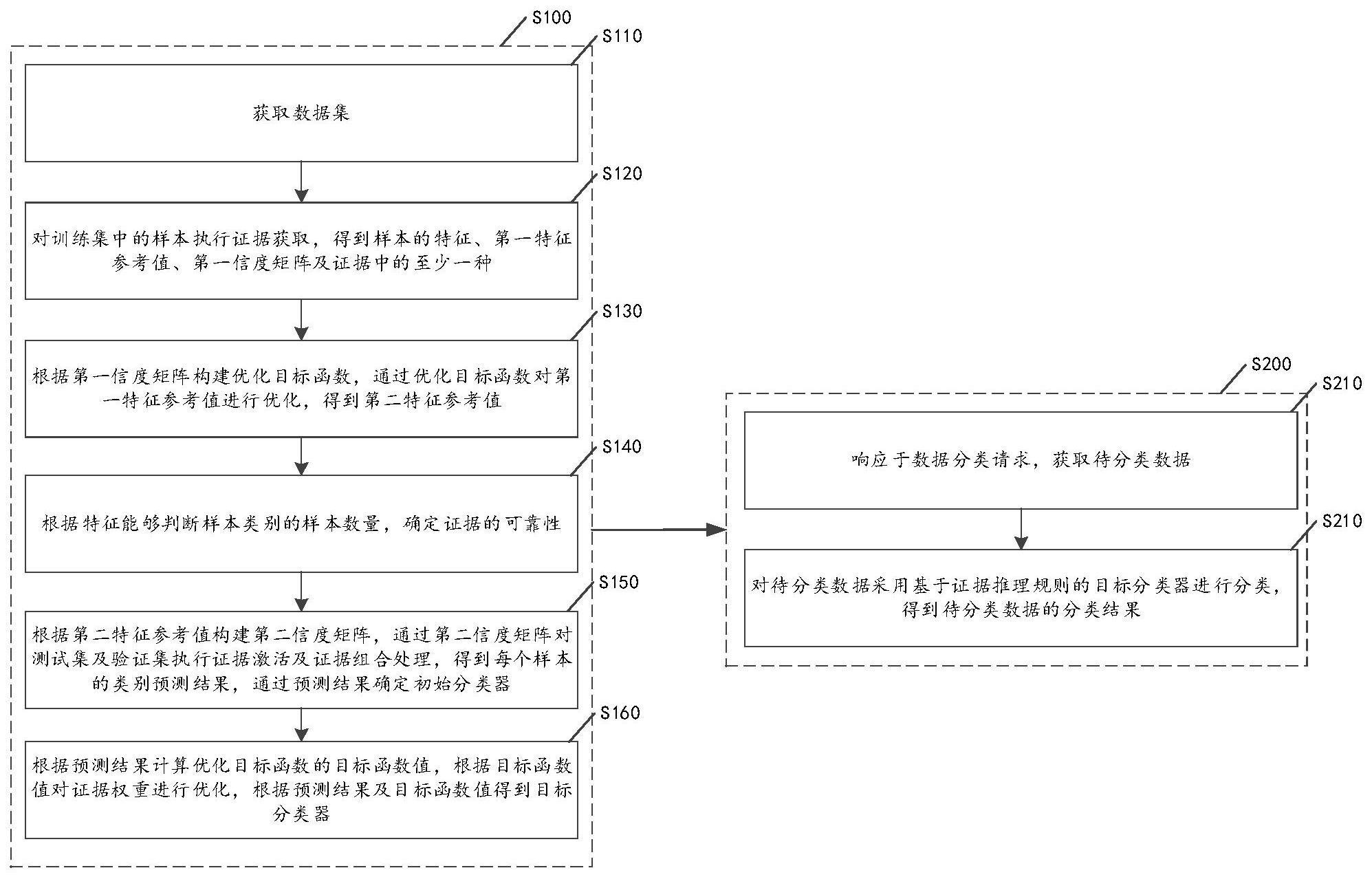
2、本发明的一方面提供了一种数据分类方法,包括:
3、响应于数据分类请求,获取待分类数据;
4、对所述待分类数据采用基于证据推理规则的目标分类器进行分类,得到所述待分类数据的分类结果;
5、所述目标分类器通过训练得到,所述训练包括:
6、获取数据集,所述数据集包括训练集、测试集及验证集中的至少一种;
7、对所述训练集中的样本执行证据获取,得到样本的特征、第一特征参考值及第一信度矩阵,通过所述特征、所述第一特征参考值及所述第一信度矩阵确定证据;
8、根据所述第一信度矩阵构建优化目标函数,通过所述优化目标函数对所述第一特征参考值进行优化,得到第二特征参考值,所述优化目标函数包括基于信度分布差异、基于证据不确定性及基于基尼指数中的一种;
9、根据所述特征能够判断样本类别的样本数量,确定所述证据的可靠性;
10、根据所述第二特征参考值构建第二信度矩阵,通过所述第二信度矩阵对所述测试集及所述验证集执行证据激活及证据组合处理,得到每个所述样本的类别预测结果,通过所述类别预测结果确定初始分类器;
11、根据所述类别预测结果计算所述优化目标函数的目标函数值,根据所述目标函数值对证据权重进行优化,根据所述类别预测结果及所述目标函数值得到所述目标分类器,所述证据权重用于表征处于所述第一信度矩阵的证据相对于不处于所述第一信度矩阵的其他证据的重要性。
12、根据所述的数据分类方法,其中对所述训练集中的样本执行证据获取,得到样本的特征、第一特征参考值、第一信度矩阵及证据中的至少一种,包括:
13、确定所述训练集中每个样本的所述特征的所述第一特征参考值,所述特征具有特征值;
14、对所述特征值执行信息转换处理,得到所述特征值与所述第一特征参考值的相似度分布,根据所述相似度分布确定参考值匹配度,参考值匹配度用于表征所述特征值与所述第一特征参考值的匹配度,所述信息转换用于将特征值与类别的关系转换成特征参考值与类别的关系;
15、根据所述训练集中所有所述样本的参考值匹配度,得到所述特征投点矩阵;
16、通过贝叶斯范式和所述特征投点矩阵,确定所述样本的类别,以及,确定所述特征值被认为是所述第一特征参考值的条件概率;
17、根据所述条件概率计算所述特征的所述第一特征参考值与类别的所述证据,得到所述第一信度矩阵。
18、根据所述的数据分类方法,其中基于信度分布差异的所述优化目标函数包括:
19、修改所述第一特征参考值,以提升所述第一信度矩阵中每条证据对每个类别的支持信度的差异;
20、采用信度矩阵列信度差异及信度矩阵行信度差异中的至少一种执行优化;
21、所述信度矩阵列信度差异的优化目标函数对第一信度矩阵的每列的信度分布差异进行处理,其公式为
22、
23、其中,diff1为信度矩阵列信度差异的优化目标函数,i为特征标号,j为特征参考值标号,p1为待优化的第一特征参考值,m为数据集中的特征数量,ji为特征xi的参考值数量,n为数据集样本的类别数量,是第一信度矩阵中证据对类别yn的信度,是第一信度矩阵中证据对数据集s的信度,n为样本类别标识,s为数据集s中的样本标识;
24、所述信度矩阵行信度差异中的优化目标函数对所述第一信度矩阵的每行的信度分布差异进行处理,其公式为
25、
26、其中,diff2为信度矩阵行信度差异的优化目标函数,i为特征标号,j为特征参考值标号,p1为待优化的第一特征参考值,m为数据集中的特征数量,ji为特征xi的参考值数量,n为数据集样本的类别数量,de表示融合结果和样本xk实际所属类别参考向量之间的欧氏距离,其中
27、
28、为特征xi得到的每条证据在不同类别上的平均信度分布差异,coeffi表示对每个特征信度矩阵的信度分布差异进行加权,其中coeffi为特征与类别之间的相关性,表示为ri,表示为
29、
30、其中xi表示数据集中所有样本在特征xi上的取值集合,y是所有样本的类别标签集合,cov(xi,y)表示xi与y的协方差,和σy分别是xi和y的标准差;
31、coeffi还包括为特征xi与类别之间的pearson相关系数,表示为
32、
33、其中,pearson相关系数的取值范围为[-1,1],pri(xi,y)取pearson相关系数的绝对值。
34、根据所述的数据分类方法,其中基于证据不确定性的优化目标函数包括:
35、通过香农信息熵对每条证据所包括的信息不确定性进行描述,其公式为
36、
37、其中,uncert为香农信息熵,p1为待优化的第一特征参考值,是证据的一个元素,用于表征当样本特征xi取值为参考值时,样本的类别被认为是yn的概率,其中
38、
39、用于计算证据的信息熵。
40、根据所述的数据分类方法,其中基于基尼指数的优化目标函数包括:
41、计算所述数据集的基尼指数,其中基尼指数用于表征数据集的纯度,所述纯度用于表征从所述数据集抽取两个样本的类别不一样的概率,基尼指数gini(θ)的计算公式为
42、
43、其中,θ={y1,y2,…,yn},为训练集样本所属的类别集合,p(yn)表示数据集s中类别为yn的样本所占的比例,ks表示数据集s中的样本总数,|yn|表示数据集s中类别为yn的样本数;
44、采用分类回归树从基尼指数中选取最优分裂特征,计算公式为
45、
46、其中,gini(θ,xi)用于计算特征xi当前的参考值取值时,数据集s的纯度;
47、其中,为特征xi取值为参考值的样本所占的比例,
48、
49、为特征xi的取值为参考值的样本中,类别为yn的样本所占的比例;
50、根据
51、
52、确定所述基于基尼指数的优化目标函数为
53、
54、其中,an,j表示类别为yn的样本的特征xi的取值对参考值的匹配度之和,
55、或者,根据当样本的特征值xi取值为参考值时,样本的类别为yn的概率,即且取值为得到所述基于基尼指数的优化目标函数为
56、
57、其中gini1和gini2为通过两种不同方式得到的所述基于基尼指数的优化目标函数。
58、根据所述的数据分类方法,其中根据所述特征能够判断样本类别的样本数量,确定所述证据的可靠性,包括:
59、通过公式
60、
61、确定特征xi的可靠性ri,ri为证据的可靠性,m为数据集中的特征数量,ji为特征xi的参考值数量,其中,qi表示根据特征xi的取值判定所属类别的样本总数,且qi满足
62、
63、其中ri=1时,xi是最可靠的特征。
64、根据所述的数据分类方法,其中根据所述第二特征参考值构建第二信度矩阵,通过所述第二信度矩阵对所述测试集及所述验证集执行证据激活及证据组合处理,得到每个所述样本的类别预测结果,通过所述类别预测结果确定初始分类器,包括:
65、将取值在区间的特征值激活与参考值和相对应的两条相邻证据和得到证据ei,其中
66、
67、其中,pn,i表示样本的特征值激活证据和时,样本特征值被认为属于类yn的信度,αi,j和αi,j+1根据参考值匹配度进行计算,证据ei的权重wi通过和的加权和计算得到,计算公式为
68、
69、得到m个特征的m条证据e1,e2,…,em及相应权重,通过分类器进行组合,得到融合结果r(xk),其中样本xk的预测类别是pn,e(m)的最大值所对应的类别yn,其中
70、r(xk)={(yn,pn,e(m)),n=1,2,…,n},
71、根据融合结果r(xk)得到所述初始分类器。
72、根据所述的数据分类方法,其中根据所述类别预测结果计算所述优化目标函数的目标函数值,根据所述目标函数值对证据权重进行优化,得到所述目标分类器,包括:
73、选取符合预设约束条件的证据权重的取值,执行证据激活及证据组合处理,得到满足证据权重的取值情况时每个样本的类别预测结果,类别预测结果包括激活证据组合结果和预测类别;
74、根据训练集所有样本的类别预测结果,计算所述优化目标函数值,计算方式为
75、
76、其中obj为目标函数,
77、
78、用于表征目标函数同时满足最小化训练集样本mse值及最大化训练集样本的分类准确率,mse为优化目标函数的目标函数值,acc_train为样本类别预测结果,rightnum_train为训练集中预测类别与实际类别相同的样本数量,totalnum_train是训练集中的样本总数;
79、根据目标函数值对具有不同证据权重的取值进行判断,得到判断结果;
80、根据所述判断结果,确定所述目标分类器。
81、本发明实施例的另一方面提供了一种数据分类装置,包括:
82、分类模块及目标分类器训练模块,所述分类模块包括数据采集子模块及数据分类子模块,所述目标分类器训练模块包括数据集子模块、证据获取子模块、特征参考值优化子模块、证据可靠性子模块、证据组合子模块及目标函数优化子模块;
83、所述数据采集子模块用于响应于数据分类请求,获取待分类数据;
84、所述数据分类子模块对所述待分类数据采用基于证据推理规则的目标分类器进行分类,得到所述待分类数据的分类结果;
85、所述目标分类器通过训练得到,所述训练包括:
86、所述数据集子模块用于获取数据集,所述数据集包括训练集、测试集及验证集中的至少一种;
87、所述证据获取子模块用于对所述训练集中的样本执行证据获取,得到样本的特征、第一特征参考值及第一信度矩阵,通过所述特征、所述第一特征参考值及所述第一信度矩阵确定证据;
88、所述特征参考值优化子模块用于根据所述第一信度矩阵构建优化目标函数,通过所述优化目标函数对所述第一特征参考值进行优化,得到第二特征参考值,所述优化目标函数包括基于信度分布差异、基于证据不确定性及基于基尼指数中的一种;
89、所述证据可靠性子模块用于根据所述特征能够判断样本类别的样本数量,确定所述证据的可靠性;
90、所述证据组合子模块用于根据所述第二特征参考值构建第二信度矩阵,通过所述第二信度矩阵对所述测试集及所述验证集执行证据激活及证据组合处理,得到每个所述样本的类别预测结果,通过所述类别预测结果确定初始分类器;
91、所述目标函数优化子模块用于根据所述类别预测结果计算所述优化目标函数的目标函数值,根据所述目标函数值对证据权重进行优化,根据所述类别预测结果及所述目标函数值得到所述目标分类器,所述证据权重用于表征处于所述第一信度矩阵的证据相对于不处于所述第一信度矩阵的其他证据的重要性。
92、本发明实施例的另一方面提供了一种电子设备,包括处理器以及存储器;
93、所述存储器用于存储程序;
94、所述处理器执行所述程序实现如前文所描述的方法。
95、本发明实施例还公开了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器可以从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行前文所描述的方法。
96、本发明的有益效果为:本发明的技术方案通过判断训练集样本激活证据的在完成特征参考值优化步骤之后和证据权重优化步骤之前开展,从而可以减少证据权重优化过程的计算量;通过构建衡量信度矩阵质量的目标函数,其值直接基于证据获取得到的信度矩阵计算,而无需计算出每个训练集样本的分类结果,即在参考值优化步骤完成之前,不需要执行证据激活与组合步骤,提高了分类器对大量数据的分类效率。因此提高了基于证据推理规则分类器的构建速度,且分类器具有消耗系统资源少,分类效率高。基于所构建的分类器,本发明能够实现耗时短、分类效果高、分类准确度高及高稳定性数据分类处理。
- 还没有人留言评论。精彩留言会获得点赞!