基于双层记忆网络的多领域的端到端任务型对话系统的制作方法
本发明涉及计算机,特别是涉及一种基于双层记忆网络的多领域的端到端任务型对话系统。
背景技术:
1、记忆网络结合到端到端任务型对话系统虽然取得了比较好的效果,但是在外部知识融入方面和推理能力方面仍然表现不够优秀,并且目前训练的端到端的任务型对话系统中,要么都是针对特定领域的,并且依赖大量标签数据去学习特定的特征,要么就是混合所有领域的数据去学习共有的特征,虽然这两种方法已经取得了相当不错的成绩,但是这限制了模型的通用性,无法很好移植到新的领域,并且针对每一个领域都难以收集到大量的标签数据。如果将多个特定领域的数据都混合在一起用同一个模型训练,得到同一组模型参数,可以很好地捕获所有领域的共有的特性,但是就难以捕获特定域的特征。如果将多个特定领域的数据分开训练,每个特定领域的模型都只训练本领域的数据,可以很好地捕获特定领域的特征,但是难以捕获所有领域共享的特征。因此,针对端到端任务型对话系统,需要一种方法在提升系统准确率的同时,兼顾通用性,易于将拥有海量数据的领域训练出来的模型移植到一个全新的或者数据较少的领域之中。
2、此外,在传统的记忆网络中通常使用三元组的形式表示知识库信息,这样虽然能够很清晰地表示知识信息,但是在对话回答定位知识三元组的过程中,容易出现错误。
3、综上所述,目前的记忆网络的端到端任务型对话系统依然存在以下挑战:
4、①目前主流的记忆网络的端到端任务型对话系统均采用三元组的形式表示外部知识库,这种方法存在对话推理困难和知识库信息定位困难,难以有效地将正确的知识信息融合到对话当中。
5、②对话历史信息和知识库信息都存储于同一个记忆网络之中,并使用共享的记忆网络对实体和对话历史进行编码,这种编码方式虽然能够轻松的将知识融入对话之中,但是不同的数据格式所包含的信息是有差异化的,在同一个网络上进行推理是十分困难的和低效率的。
6、③现有的端到端任务型对话系统在无法将特定领域训练的模型移植到数据量较少或者没有数据的领域,模型的泛化性较差,并且在解码阶段选择词元不够精准。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于双层记忆网络的多领域的端到端任务型对话系统。
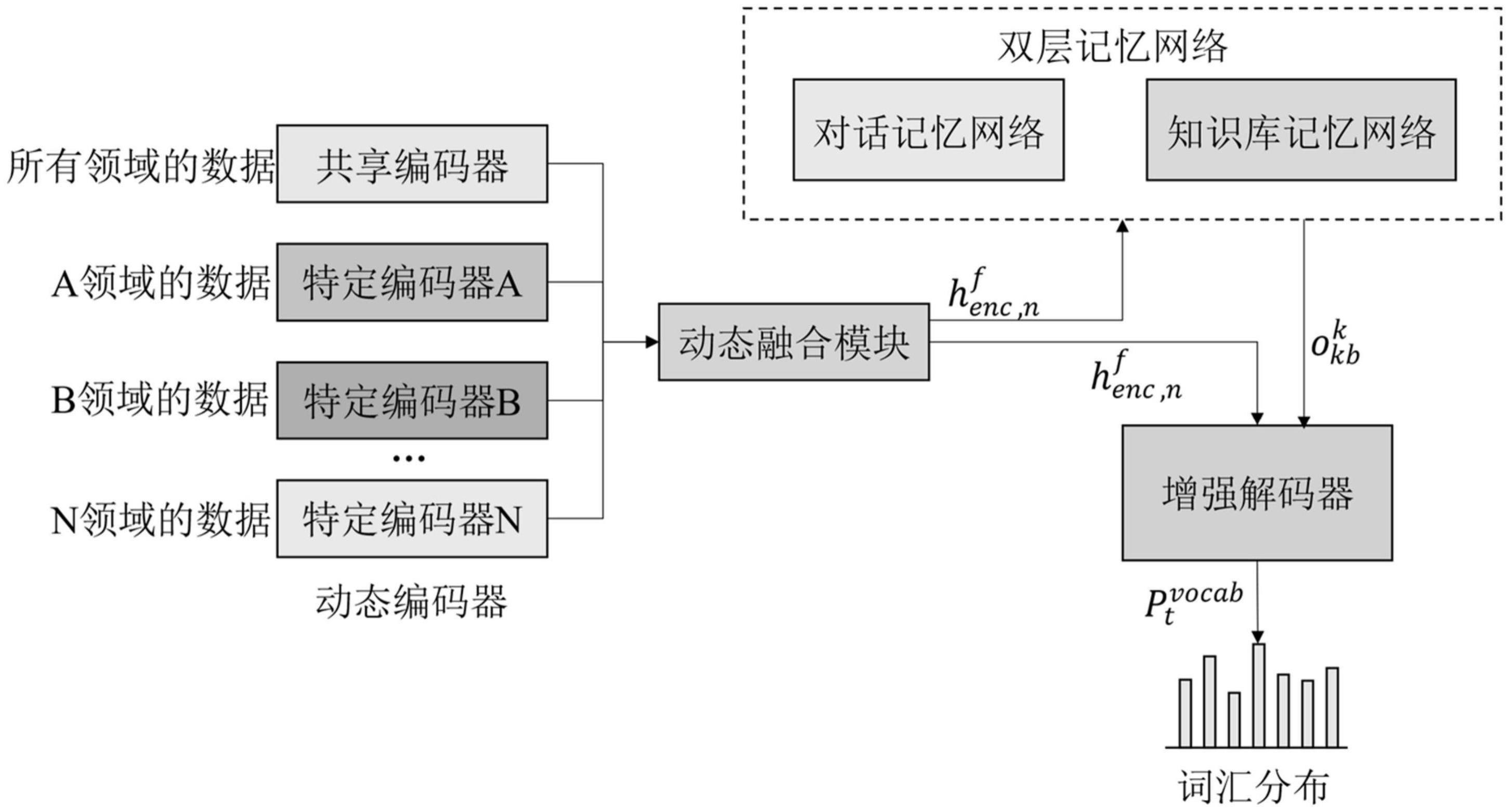
2、为了实现本发明的上述目的,本发明提供了一种基于双层记忆网络的多领域的端到端任务型对话系统,包括:
3、动态编码器:将输入的对话数据进行编码;
4、双层记忆网络:对话历史信息和知识库信息进行建模和推理;
5、增强解码器:得到输出的单词;
6、所述双层记忆网络包括对话记忆网络和知识库记忆网络;
7、把对话数据输入到动态编码器进行编码,然后对编码数据进行融合,得到的隐藏状态作为双层记忆网络的输入,获得双层记忆网络的输出然后和作为增强解码器的输入,得到输出的单词概率所述动态编码器编码包括一个共享编码器和n个特定编码器,所述共享编码器的输入是所有领域的对话数据,第i个特定编码器的输入是第i个领域的对话数据,i=[1,n]。
8、进一步地,所述知识库信息用知识行的形式表示,所述知识行包括:兴趣点、兴趣点类型、距离信息、地址信息和交通信息。采用知识行表示知识库信息,可以大幅度降低记忆网络在推理的过程中的复杂性,提高推理能力。
9、进一步地,动态编码器包括:先用特定领域的数据训练特定编码器(私有模型),然后采用混合专家机制进行动态融合,获取私有特征,然后对动态融合后的私有特征与共享特征进行全融合,得到输出的编码向量。
10、进一步地,所述采用混合专家机制进行动态融合,获取特定领域的特征包括:
11、所有领域的特征表示在第k跳编码的时候表示为表示不同领域的数量,专家门把作为输入,并且输出softmax值αk,i作为每个领域与当前输入单词之间的相关度,αk,i具体计算过程如公式(3)所示:
12、
13、αk,i表示每个领域与当前输入单词之间的相关度系数;
14、表示第k跳编码时第i个领域的特征表示;
15、w为矩阵参数;
16、b为偏置项;
17、专家门权重值为最终的特征向量是所有领域输出的混合
18、
19、表示第k跳编码时所有领域的特征表示;
20、最终编码器输出的一组隐藏向量为
21、进一步地,所述对动态融合后的私有特征与共享特征进行全融合,得到输出的编码向量包括:
22、
23、其中表示混合特征向量;
24、[ ]为拼接操作;
25、表示共享领域的特征向量;
26、表示私有领域的特征向量;
27、最后共享私有混合编码向量表示由经过leakyrelu非线性变换得到,具体计算过程由公式(6)计算可得:
28、
29、其中,w1和w2为参数矩阵;
30、leakyrelu表示激活函数。
31、进一步地,所述共享特征的获得包括以下步骤:
32、一个对话历史信息的输入序列表示为x=(x1,x2,...,xn),n表示对话序列的长度,首先根据公式(1)获得每个单词的词向量表示ei:
33、ei=φemb(xi)#(1)
34、xi表示对话序列的长度为i的对话;
35、φemb( )表示嵌入函数;
36、然后,采用gru来构建编码器,将对话历史信息编码成隐藏状态向量得到一组编码器的隐藏向量为如公式(2)所示;
37、
38、表示编码器的第i个隐藏向量;
39、gru为门控循环单元。
40、进一步地,所述双层记忆网络模块包括:
41、双层记忆网络的嵌入矩阵分别包含了一系列可训练的对话记忆网络的嵌入矩阵和知识库记忆网络的嵌入矩阵其中,k表示这是一个可以进行k次查询和推理的k跳的记忆网络,|v|是词汇大小,demb是嵌入向量的维度;
42、分别使用对话记忆网络嵌入矩阵和知识库记忆网络嵌入矩阵进行词嵌入,得到词嵌入向量其中对话记忆网络嵌入矩阵进行词嵌入与知识库记忆网络嵌入矩阵进行词嵌入的过程相同,具体步骤如下:
43、
44、其中,表示第i行第j列的单词第k跳时进行词嵌入后的向量表示;
45、embk表示进行词嵌入操作;
46、vi,j表示在双层记忆网络中第i行第j列的单词;
47、然后使用词袋模型b(·)获得包含所有列的特征的记忆行的向量表示,如公式(9)所示:
48、
49、其中,|c|表示总列数;
50、表示第k个嵌入矩阵编码后的第i行所有列的词嵌入向量表示的求和运算得到的向量表示,包含了第i个记忆行的所有特征信息;
51、并且,动态编码器编码得到的上下文表示也会被写入到双层记忆网络中,如公式(10)所示:
52、
53、其中,表示编码器第i行记忆行的上下文表示,将其写入到当前记忆行的上下文表示;所有的对话记忆行组成和知识库网络记忆行|rd|和|rkb|分别表示对话记忆网络和知识库记忆网络的总行数;那么,一个k跳的双层记忆网络的对话信息矩阵为和知识信息矩阵为最终,对于一个k跳的记忆网络,通过公式(11)分别对对话记忆网络和知识库记忆网络的内容进行计算第k跳的注意力权重:
54、
55、其中,qk表示第k跳的查询向量;
56、(qk)t表示qk的转置;
57、softmax表示激活函数;
58、表示第k个嵌入矩阵编码后的第i行所有列的词嵌入向量;
59、通过公式(11)可以获得第k跳记忆行的注意力权重然后通过第k跳记忆行注意力权重便可以读取第k跳的记忆网络的具体内容ok,为对话记忆网络时得到为知识库记忆网络得到如公式(12)所示:
60、
61、通过当前查询向量qk和具体内容ok可以更新下一跳的查询向量qk+1,具体计算过程如公式(13)所示:
62、qk+1=qk+ok#(13)
63、最终实现双层记忆网络的k跳读取和推理能力就是通过循环公式(8)至(13)的过程完成。
64、进一步地,还包括双层记忆网络模块在模型训练中使用的双层记忆网络指针:
65、对话记忆网络指针为知识库记忆网络指针为当指针有相关性的行为表示为1,不相关的行为表示为0,|rd|和|rkb|分别表示为对话记忆的行数和知识库记忆的行数,|rd|+1和|rkb|+1分别表示为对话记忆和知识库记忆结束标记所在行;
66、对于知识库记忆行而言,认为若这个知识记忆行包含最多数量的单词出现在真实回复y中就认为这个知识记忆行与其相关,否则不相关;对于对话记忆行,如果单词存在生成的回复y中,那么就认为这个对话记忆行与其相关,否则不相关;
67、在解码器生成回复之前,双层记忆网络指针可以根据对话历史信息和知识库信息获得与当前对话相关的记忆行信息;
68、双层记忆网络指针模块将动态编码器的最后一个隐藏状态向量作为初始查询向量q1:
69、
70、然后再进行了k次查询和推理后,可以分别获得对话记忆行和知识库记忆行的记忆网络指针,其计算过程如公式(15):
71、
72、gi表示记忆网络指针;
73、qk表示第k次的查询向量;
74、(qk)t表示qk的转置;
75、表示第k个嵌入矩阵编码后的第i行所有列的词嵌入向量。
76、进一步地,所述增强解码器模块包括:
77、将和拼接成一个解码器输入的初始的向量表示
78、
79、是一个可学习的参数矩阵;
80、[ ]为拼接操作;
81、表示动态编码器的最后一个隐藏状态向量;
82、为相关的外部知识信息;
83、
84、gru( )表示输入门控循环单元;
85、表示解码器上一时刻的输出的粗略的单词;
86、表示上一时刻的解码器的向量表示;
87、然后根据公式(21)获得输出单词的概率分布:
88、
89、是一个可学习的参数矩阵;
90、表示词汇表大小的向量分布概率;
91、对于对话记忆网络实体分布标签如公式(24)所示:
92、
93、表示知识库记忆网络的实体选中概率分布;
94、表示计算得到的知识库概率分布;
95、表示获得知识库的概率矩阵;
96、对于知识库记忆网络实体分布标签如公式(25)所示:
97、
98、其中,i表示知识库记忆网络的第i行,j表示知识库记忆网络的第j列;
99、vi,j表示第i行第j列的单词;
100、表示知识库记忆指针的第i个标签;
101、|rkb|表示知识库记忆网络的总行数;
102、|ckb|表示知识库记忆网络的总列数;
103、|rkb|×|ckb|+1表示指向结束标记的位置,如果第i行j列的词语等当当前时刻的回复yt,并且其知识库记忆网络指针具有相关性,要么该实体被选中,要么定义为结束标记。
104、进一步地,还包括模型的损失函数:
105、loss=αlosse+βlossv+γlossg+δlossenc#(29)
106、其中,α、β、γ、δ是超参数;
107、losse表示实体解码的损失函数;
108、lossv表示词汇表分布概率向量的损失函数;
109、lossg表示双层记忆网络指针的损失函数;
110、lossenc表示单词领域的损失函数;
111、
112、
113、
114、表示知识库记忆网络的标签;
115、表示对话记忆网络的标签;
116、表示知识库记忆网络的实体选中概率分布;
117、表示对话记忆网络的实体选中概率分布;
118、m表示记忆网络的标签个数;
119、
120、表示解码器生成的词汇表分布概率向量;
121、ys表示gru生成的真实粗略响应;
122、lossg=lossd+losskb#(18)
123、
124、
125、lossd表示对话记忆指针的损失函数;
126、losskb表示知识库记忆指针的损失函数;
127、表示对话记忆网络指针的第i个标签;
128、表示知识库记忆指针的第i个标签;
129、
130、其中,n表示编码的长度;
131、表示不同领域的数量;
132、表示计算相关度系数和编码器模型参数;
133、αt,i表示第t个领域与当前输入单词之间的相关度系数;
134、θs表示编码器模型的参数;
135、表示moe模块的参数;
136、ui∈{0,1}表示这个这个词元是否属于这个领域di,0表示不属于这个领域,1表示属于这个领域。
137、lossenc损失函数用于训练不同领域和目标领域之间的相关性,那么每一个领域都能够学习到特定领域的特征。如果将模型移植到其他数据量较少或者没有数据的领域,依然能够表现出优异的性能。
138、综上所述,由于采用了上述技术方案,对于端到端任务型对话系统,本发明能够在提升系统准确率的同时,兼顾通用性,易于将拥有海量数据的领域训练出来的模型移植到一个全新的或者数据较少的领域之中。
139、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!