基于YOLOv8的行人摩托车检测方法、系统和存储介质
本发明涉及计算机,特别涉及基于yolov8的行人摩托车检测方法、系统和存储介质。
背景技术:
1、目前,计算机视觉技术在各个领域得到了广泛应用,其中行人摩托车检测是计算机视觉领域中的一个重要研究方向。随着摩托车和行人的数量不断增加,如何准确检测行人和摩托车成为了一个重要的问题。
2、现有的行人摩托车检测技术主要包括基于传统图像处理方法和基于深度学习方法两种,基于传统图像处理方法的行人摩托车检测方案通常使用计算机视觉基础知识,如图像处理、特征提取和分类等来实现行人摩托车检测。该方法的主要优点是简单易用,不需要过多的计算资源和数据集。但是,该方法的检测速度较慢,且检测准确性相对较低;基于深度学习方法的行人摩托车检测方案使用深度学习模型,如卷积神经网络(cnn)来实现行人摩托车检测。该方法的主要优点是检测速度较快,检测准确性高。但是,该方法需要大量的数据和计算资源,且不同的数据集会对检测结果产生影响。
3、目前为了提高检测的准确性,大部分采用基于深度学习方法的行人摩托车检测方案,如yolov5或faster r-cnn,来实现行人摩托车检测。其中,yolov5模型是一种基于区域提取和匹配的深度学习模型,适用于目标检测任务。faster r-cnn模型则是一种基于区域提取和分类的深度学习模型,适用于目标检测任务。使用该类模型进行行人摩托车检测时,需要对模型进行训练和优化,以提高检测准确性和速度。同时,也需要对输入的图像进行预处理,如增强图像对比度、调整图像大小等,以提高检测效果。但是这类方案依然存在一些问题和缺点,主要包括以下方面:
4、1.需要大量的数据和计算资源:深度学习模型需要大量的数据和计算资源来训练和优化模型,否则会导致模型的准确性和鲁棒性降低。
5、2.受数据集质量和数量的影响:深度学习模型的性能很大程度上取决于训练数据的质量数量和多样性。如果数据集不足或者质量不高,会导致模型的检测准确性降低。
6、3.需要大量的预处理操作:深度学习模型通常需要进行图像增强、裁剪、调整大小等预处理操作,以提高模型的检测效果。但是这些预处理操作也会增加算法的复杂度和计算资源的需求。
7、4.模型复杂度高:深度学习模型通常包含多层卷积神经网络,导致模型的结构和参数非常复杂,需要耗费大量的计算资源和时间来进行训练。
8、5.需要专业的训练和调试:深度学习模型需要进行专业的训练和调试,否则会导致模型的检测效果不理想。同时,深度学习模型的调试过程也比较复杂,需要耗费大量的时间和精力。
9、因此针对这些现存的问题,本技术提出了一种解决方案。
技术实现思路
1、发明目的:本发明的目的是提供一种基于yolov8的行人摩托车检测方法、系统和存储介质,具有较高的检测准确性、较低的计算资源和数据需求、较少的预处理操作、较低的模型复杂度、便捷的调试和训练这些优势。
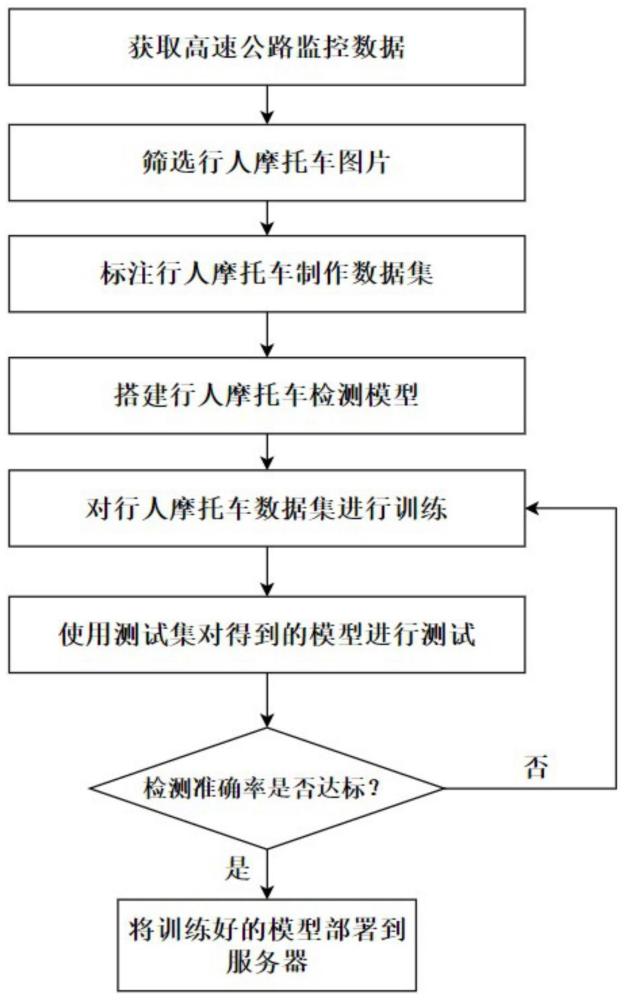
2、技术方案:本发明所述的基于yolov8的行人摩托车检测方法,包括有以下步骤:
3、s1:数据集准备,数据集中包含有不同角度、不同光照和不同姿态的行人摩托车图像;
4、s2:搭建yolov8模型,在搭建yolov8模型时,使用tensorflow或pytorch这样的深度学习框架,同时根据数据集的大小和硬件配置选择合适的模型超参数;
5、s3:图像预处理,预处理包括对图像增强、裁剪和调整大小,其中图像增强包括有随机水平翻转、随机颜色增强、随机透视变换和运动模糊增强,裁剪和调整大小为随机裁剪缩放;
6、s4:训练yolov8模型,在训练yolov8模型时将数据集分成训练集和验证集以避免模型过拟合;
7、s5:使用测试集来测试yolov8模型的检测准确性,通过将测试集中的图像输入到yolov8模型中,计算yolov8模型检测结果的检测准确率、召回率和f1值这些指标;
8、s6:将训练完毕的yolov8模型部署到实际应用中,在部署时将模型文件上传到服务器或本地计算机,并配置好模型的超参数,然后将待检测的图像上传到服务器或本地计算机,即可使用训练完毕的yolov8模型进行行人摩托车检测。
9、作为优选,所述yolov8模型中:
10、backbone部分为将yolov5的c3结构换成梯度流更丰富的csplayer_2conv结构,并且对不同尺度的模型调整了不同的通道数,同时不同缩放因子n/s/m/l/x的模型不再共用一套模型参数,m/l/x大模型缩减了最后一个stage的输出通道数,进一步减少参数量和计算量;
11、neck部分为将c3模块以及repblock替换为csplayer_2conv,同时将上采样之前的1×1卷积去除,将backbone不同阶段输出的特征直接送入上采样操作;
12、head部分将yolov5中分类定位耦合在一起的head模块解耦,将分类分支和定位分支分离;;
13、标签分配和loss部分为从anchor-based换成了anchor-free,采用了taskalignment learning动态匹配,并引入distribution focal loss结合ciou loss做回归分支的损失函数;
14、train部分在训练的数据增强部分引入了yolox中的最后10epoch关闭mosiac增强的操作。
15、作为优选,所述s3中随机水平翻转为以概率p进行水平翻转给定的图像,即将图像左右翻转,增加训练数据多样性,防止模型过拟合,具体的,在pytorch中提供了api接口:transforms.randomhorizontalflip(p=0.5)。
16、作为优选,所述s3中随机颜色增强的实现通过api:transform.colorjitter(),完成对图像的亮度、对比度、饱和度和色调的随机改变,通过api:transforms.randomposterize(),完成对图像色彩深度的随机降低。
17、作为优选,所述api:transform.colorjitter()中,colorjitter()在创建transforms对象时作为其中的一部分,包括有以下参数:
18、brightness:用于随机调整亮度的参数,默认为0,表示不随机调整亮度,如果设置为0.1,亮度将在[1-0.1,1+0.1]的范围内随机变化;
19、contrast:用于随机调整对比度的参数,默认为0,表示不随机调整对比度,如果设置为0.1,对比度将在[1-0.1,1+0.1]的范围内随机变化;
20、saturation:用于随机调整饱和度的参数,默认为0,表示不随机调整饱和度,如果设置为0.1,饱和度将在[1-0.1,1+0.1]的范围内随机变化;
21、hue:用于随机调整色调的参数,默认为0,表示不随机调整色调,如果设置为0.1,色调将在[-0.1,0.1]的范围内随机变化。
22、作为优选,所述api:transforms.randomposterize()的具体操作是,随机在0-8之间选择一个位数,并将所有颜色通道的比特数降低到该位数,这个操作的公式为:
23、out=quantize(posterize(ln))
24、其中ln表示输入图像,posterize表示posterize操作,quantize是一个将实数值映射到整数值的函数,它通过公式表现:
25、quantize(x)=□δx□□δ
26、其中δ是一个分度值,表示连续实数值的离散间隔,在transforms.randomposterize()中,δ的计算公式是:
27、δ=2^bits/255
28、其中bits是随机选择的位数。
29、作为优选,所述s3中随机透视变换的实现通过api:randomperspective()实现,包括以下参数:
30、distortion_scale:扭曲程度的控制因子,默认值为0.5,表示扭曲程度在0到0.5之间。
31、p:应用该操作的概率,默认值为0.5;
32、具体包括以下步骤:
33、s3.11:随机选择4个控制点;
34、s3.12:随机调整4个控制点的位置,增加图像的扭曲和畸变;
35、s3.13:计算透视变换矩阵,包括旋转、缩放和剪切这些几何变换;
36、s3.14:对图像进行透视变换,并将图像缩放到原始大小。
37、作为优选,所述s3中的运动模糊增强通过motion_blur函数实现,所述motion_blur函数包括有三个参数和概率p,三个参数为:原始图像image、模糊程度degree和运动方向angle,具体包括以下步骤:
38、s3.21:利用opencv库getrotationmatrix2d()函数生成一个旋转矩阵,该矩阵将对角线为1的矩阵旋转指定角度;
39、s3.22:然后利用warpaffine函数将对角线为1的矩阵进行仿射变换,得到一个任意角度的kernel矩阵,也就是运动模糊矩阵,degree越大模糊越明显
40、s3.23:将得到的kernel矩阵除以degree,以确保矩阵中每个元素的值在[0,1]之间;
41、s3.24:利用filter2d()函数对输入的图像进行运动模糊,然后对模糊后的图像进行归一化,使像素值处于[0,255]范围内。
42、有益效果:
43、(1)、本发明使用yolov8模型进行行人摩托车检测,该模型相对于其他深度学习模型,具有较低的计算资源和数据需求,可以在较低的硬件配置和数据集较小的情况下,实现较高的检测准确性;
44、(2)、本发明使用yolov8模型进行行人摩托车检测,该模型通过分层特征提取和自注意力机制,可以自适应地学习不同尺度的特征,不受数据集质量和数量的影响,可以实现较高的检测准确性;
45、(3)、本发明使用yolov8模型进行行人摩托车检测,该模型不需要进行复杂的图像增强、裁剪、调整大小等预处理操作,可以减少算法的复杂度和计算资源的需求;
46、(4)、本发明使用yolov8模型进行行人摩托车检测,该模型相对于其他深度学习模型,具有较低的模型复杂度,可以在较小的计算资源和数据集下实现较高的检测准确性;
47、(5)、本发明使用yolov8模型进行行人摩托车检测,该模型可以通过简单的调试和训练,实现较高的检测准确性。同时,本发明也提供了一些便捷的调试工具和训练策略,可以方便地调试和训练模型。
- 还没有人留言评论。精彩留言会获得点赞!