一种考虑地形结构的深度强化学习导航方法
本发明涉及移动机器人,具体涉及一种考虑地形结构的深度强化学习导航方法。
背景技术:
1、随着移动机器人技术的快速发展,机器人在人们的日常生活中扮演着越来越重要的角色。导航作为移动机器人基本功能的关键技术之一,也需要应对新的挑战。例如,机器人在真实的3d场景中导航时,可能会遇到坡道、台阶、形状和大小各异的岩石等不同类型的地形特征。为了成功地在上述地形中导航,机器人必须依赖3d传感数据来计算导航动作。而现有的移动机器人导航算法大多基于2d激光雷达来实现,这会导致3d地形的关键信息丢失,从而直接影响机器人在崎岖地形中的导航性能。
2、自主导航的目标是机器人在面对难以预测的现实环境时,机器人能够快速安全的到达目标点。为实现安全自主导航,机器人需要利用自身传感器感知周围环境中的障碍物信息,其中常见的传感器包括激光传感器、视觉传感器和超声传感器等。在获取障碍物信息后,可进一步依据避障方法得到控制指令,从而控制机器人在环境中移动并避开周围的障碍物。
3、现有技术中,常见的自主导航技术包括:
4、基于动态窗口的的自主导航:基于动态窗口的自主导航是一种常用的避障规划方法,它可以在速度空间中搜索机器人最优控制速度,使机器人能够快速到达目标点,同时避免与障碍物发生碰撞。它可以结合全局路径规划算法,如dijkstra算法或a*算法,来生成机器人的导航轨迹。动态窗口算法通常应用于携带有2d激光雷达的移动机器人,很难适用于地面崎岖的场景。
5、基于深度学习的自主导航:基于深度学习的自主导航是一种利用深度神经网络来实现机器人感知、决策和控制的方法。它可以直接将传感器数据(如图像、雷达、激光等)映射到控制信号(如速度、转向角等),不需要进行中间层的处理。深度学习依赖于手工设计的特征,可能存在信息丢失或不一致的问题。但基于深度学习的自主导航需要高性能的传感器和计算设备,以提供高质量和高速率的数据输入和输出。这可能会增加成本和功耗,限制了机器人在实际环境中的部署和运行。
6、基于深度强化学习的自主导航:传统机器人避障方法计算量较大,且过度依赖于模型参数与实验场景,难以适应当下日益复杂多变的应用场景,因此需要研究更为强大新颖的避障方法以满足实际应用需求。基于上述原因,深度强化学习算法(deepreinforcement learning,drl)由于其独有的反馈学习特性,已经受到了越来越多的关注,并且已经在机器人相关工作中有了卓越的表现。深度强化学习算法应用于机器人领域,主要是通过在仿真模拟环境中进行大量重复的实验,进而不断的从过去的错误经验中提升算法性能。基于深度强化学习的自主导航是一种利用深度神经网络和强化学习算法来实现机器人在未知环境中的感知、决策和控制的方法。它可以克服传统的基于规则或最优视角的方法在复杂环境中的局限性,也可以提高端到端的深度学习方法的学习效率和迁移性能。但传统的深度强化学习中奖励函数只在任务完成时给予正反馈,而在任务过程中给予零或负反馈,这使得机器人很难探索有效的行为,也很难从经验中学习。
7、另外,现有的经典导航方法大多只能处理平面目标,不能处理立体目标。这可能会导致机器人在遇到高低起伏或者有遮挡物的地形结构时无法正确地识别和避开障碍物。
技术实现思路
1、为解决上述技术问题,本发明提供一种考虑地形结构的深度强化学习导航方法,通过神经网络来提取原始3d雷达数据特征,并明确考虑机器人在环境中的姿势使得机器人能够更好的感知周边地形的结构信息。此外,设计密集的奖励函数来对机器人的导航动作进行评估,从而使得训练模型具有高效灵活的导航性能。
2、为解决上述技术问题,本发明采用如下技术方案:
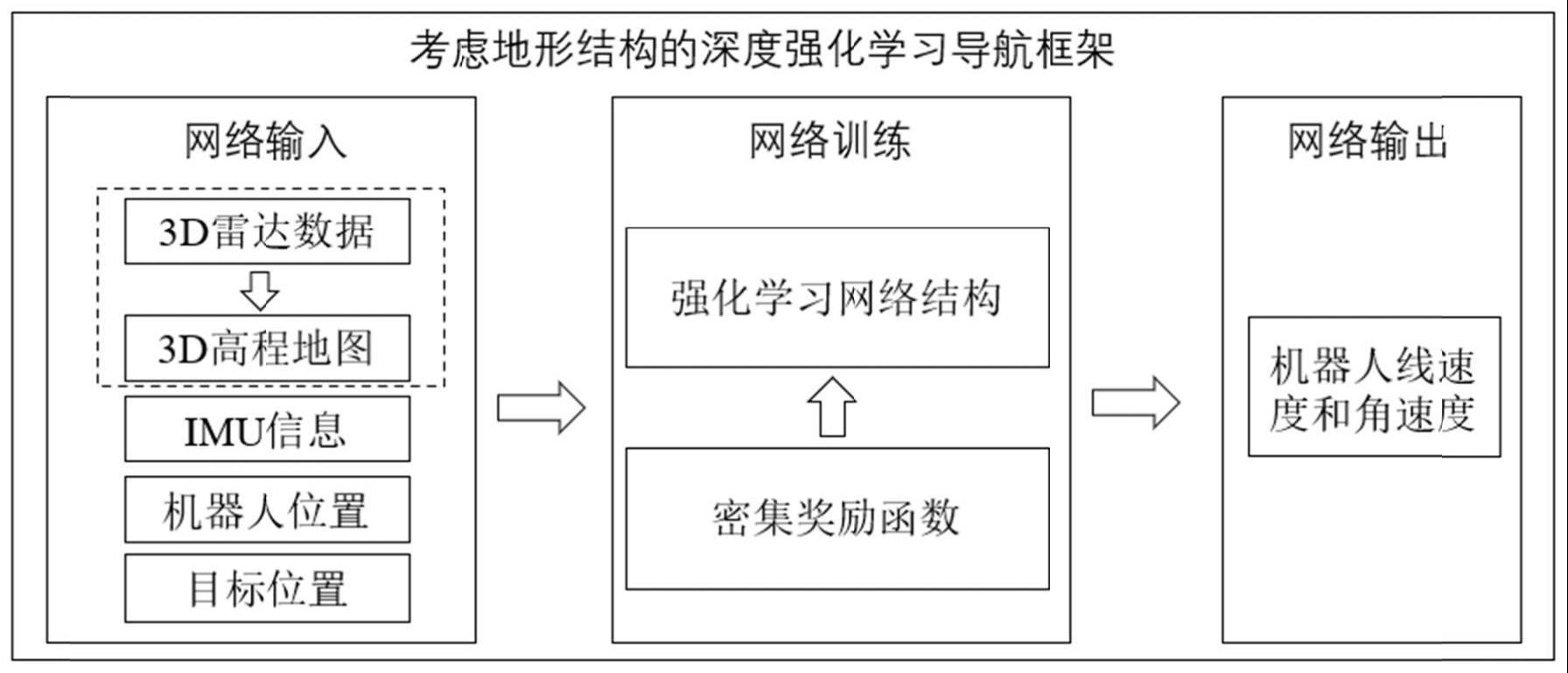
3、一种考虑地形结构的深度强化学习导航方法,通过深度强化学习导航框架输出机器人的运动命令,深度强化学习导航框架的训练过程包括以下步骤:
4、步骤一、构建深度强化学习网络的输入:
5、深度强化学习网络的输入为机器人的状态,机器人的状态包括机器人位置、目标位置、imu信息、3d雷达数据以及3d高程地图;其中,imu信息能够反映机器人运动状态;3d雷达数据是激光雷达传感器采集的三维点云数据;
6、步骤二、奖赏函数设计:
7、奖赏函数为:rt=αrg+βrc+φrs;其中,rt为机器人在仿真环境中执行动作at以后环境给予的奖励值,由目标奖励rg、碰撞奖励rc和势场奖励rs构成,α,β,φ为权重系数;目标奖励rg在机器人靠近目标位置的过程中给予正奖励,碰撞奖励rc用于评估机器人在靠近障碍物时的行为,势场奖励用于对机器人在崎岖的地形中的动作进行评估;
8、步骤三、学习策略设计:
9、使用针对连续动作空间的演员-评论家方法对深度强化学习网络进行训练;其中,演员-评论家方法中演员网络以机器人的状态为输入,输出机器人的线速度和角速度;演员-评论家方法中评论家网络以机器人的状态和演员网络的输出为输入,输出对于机器人的状态动作对的评估值;演员网络和评论家网络的更新依赖奖励函数,深度强化学习导航框架的训练目标是令机器人与环境交互产生的奖励值逐渐增大直至收敛;
10、通过完成训练的深度强化学习网络输出机器人的线速度和角速度,并发送到机器人的闭环控制器,作为机器人执行器的运动命令执行。
11、进一步地,步骤一中,使用表面重建方法将3d雷达数据的点云数据作为输入,使用泊松重建算法来生成一个三维的网格表面,得到3d高程地图。
12、进一步地,步骤一中,机器人的状态st表示为:
13、st=[pt,pg,pimu,md,mh,mq];
14、其中,pt表示机器人当前时刻的位置,pg表示目标的位置,pimu表示由机器人俯仰角、滚转角和偏航角组成的imu信息,ms表示3d雷达数据,mh表示3d高程地图的高度信息,mq表示3d高程地图的坡度信息。
15、进一步地,步骤二中,目标奖励rg表示为:
16、
17、其中,pt-1表示机器人上一时刻的位置,pt表示机器人的位置,pg表示目标的位置,wt表示机器人当前时刻的角速度。
18、进一步地,步骤二中,碰撞奖励rc表示为:
19、
20、其中,βc表示权重系数,ds表示机器人的安全距离,表示激光雷达传感器检测到的障碍物距离,pt表示机器人的位置,rcollision表示机器人的碰撞奖励。
21、进一步地,步骤二中,势场奖励rs表示为:
22、
23、其中,γ1,γ2,γ3均为正的权重系数,vt,ht,qt分别为机器人当前线速度、当前高度和当前坡度。
24、进一步地,演员网络和评论家网络的损失函数为:
25、
26、
27、其中,lactor是演员网络的损失函数,lcritic是评论家网络的损失函数,qφ是评论家网络的值函数,πθ是演员网络的策略函数,a(si,ai)是优势函数,表示在状态si下采取动作ai相对于平均水平的优劣程度,ri是在状态si下执行动作ai后获得的奖励,γ是折扣因子,n是样本数量。
28、与现有技术相比,本发明的有益技术效果是:
29、本发明使用深度强化学习通过自我学习和环境适应来优化机器人的控制策略。这可以提高机器人在复杂和动态的地形结构中的避障性能和鲁棒性,同时可以利用碰撞或者失败的经验进行改进;设计了密集奖励函数可以在任务过程中给予更多的正反馈,并在奖励函数中引入了高程地图信息,从而引导机器人能够在崎岖地形中朝着正确的方向探索和学习,提高导航效率和安全性;使用深度强化学习直接从原始的3d激光雷达数据中提取特征,不需要进行手动特征工程或者数据转换。这可以提高数据利用率和计算效率,同时避免信息损失或者噪声干扰。
- 还没有人留言评论。精彩留言会获得点赞!