基于Transformer-CNN混合架构的RGB-D跨模态交互融合机械臂抓取检测方法
本发明涉及机械臂,具体为基于transformer-cnn混合架构的rgb-d跨模态交互融合机械臂抓取检测方法。
背景技术:
1、机器人广泛应用于工业、医疗、公共服务等领域。对机器人来说,正确感知位置随机的物体并找到不同形状物体的最佳抓取姿势是一个极具挑战性的问题。不恰当的抓取位姿很容易导致错误操作,因此一种准确、快速的抓握检测方法对机器人的抓取至关重要。物体的抓取检测是在给定的抓取物品上检测出适合物体拾取的抓取位姿。早期人们大多采用手工编写抓取规则或建立物体的三维抓取模型的方法来实现物体的抓取检测。alvaro等人提出了一种使用多个图像的局部描述符来构建对象的度量3d模型的抓取检测方法。每个模型都要经过优化以拟合一组校准的训练图像,从而获得3d模型和真实对象之间的最佳对准实施抓取检测。florian等人提出了一种使机器人能够通过在公共空间中表示物体并共同抓取物体来推理、转移和优化对各种物体的抓取检测方法。该方法从各种物体的点云数据开始,利用这个由抓取和光滑表面组成的空间,连续变形各种表面/抓取配置,以合成新物体上的力闭合抓取。近年来,随着深度学习技术的兴起,越来越多的深度学习方法被应用于抓取检测领域。深度学习的方法根据不同的检测方式可大致分为2d平面抓取检测和3d六自由度抓取检测。2d平面抓取的检测目标是检测出物品的适合抓取的抓取矩形。lenz提出的两阶段抓取检测方法是早期的2d平面抓取检测之一,该方法首先运用网络模型在检测出图像中生成一系列抓取矩形,然后通过筛选网络筛选出适合物品的抓取矩形。redmon把抓取检测视为一种回归问题构建了一个单阶段的抓取检测方法,这种单阶段的检测方法实现了端到端的训练和检测,具有较快的检测速度。3d六自由度抓取检测的目标是在系统构建的三维点云系统中生成适合物品抓取的抓取位姿。arsalan等人利用pointnet++3d物体分割网络设计了一种基于三维点云的深度学习抓取检测网络,该网络能够在物体三维点云信息完整的情况下提供物品有效的抓取位姿。xinchen yan等人构建了一种两阶段的三维抓检测网络,首先根据rgb-d图像生成场景和物品的点云信息,然后根据这些点云信息生成物品的抓取预测;
2、早期的一些基于手工编写抓取规则和建立三维抓取模型的方法必须在特定的环境下实施抓取,如结构化的车间以及工厂流水线。当遇到新的产品或者更换环境就必须重新更换程序。机械臂的操作取决于预先设计的抓取规则。在不确定的抓取场景中面对不同的抓取对象,机械臂抓取规划的设计者很难设计出合理的规则和三维模型。alvaro的方法必须每次根据待抓取的物品建立三维模型才能进行抓取,对象比较单一。而florian的方法实施抓取检测的过程相对繁琐并且必须建立在点云数据完整精确的前提下才能实施抓取。目前,大多数研究都是基于深度学习展开的。3d六自由度抓取检测方法需要大量准确的点云数据的支撑,并且相对于2d的抓取检测3d的抓取检测更加复杂,目前大多数深度学习的方法是基于2d平面抓取展开的。lenz提出两阶段抓取检测的方法证明了深度学习在抓取检测领域运用的有效性,但是这种两阶段的抓取检测方法检测速度比较慢。为了提高检测速率,redmon提出了单阶段的抓取检测方法,但是该方法检测准确率有待提升,并且在多目标的检测效果比较差。许多深度学习的抓取检测方法把研究重心集中在网络架构的设计,而忽略了对网络输入数据本身的处理效率。如何提取和组合多模态信息仍然值得研究。redmon将depth信息替换rgb图像的蓝色通道作为图像输入。许多方法把三通道的rgb图像与单通道的depth图像组合成四通道的rgb-d数据作为网络的输入。这些级联处理方法有效提升了抓取准确率,但是忽略了rgb图像和depth图像的本质差异。图像的深度数据与rgb数据并不是良好对齐的,并且depth图像在拍摄时往往会丢失一些信息还同时伴随着噪声,这种简单的级联操作限制了多模态特征的潜在性能增益。kumra选择两个并行的残差网络分别提取颜色和深度特征,然后将两个特征流融合。这种并行的特征融合网络增强了特征表示,但是缺少中间过程的特征校准,细节特征仍然有待提升,因此需要对以上问题提出一种新的解决方案。
技术实现思路
1、本发明的目的在于提供基于transformer-cnn混合架构的rgb-d跨模态交互融合机械臂抓取检测方法。
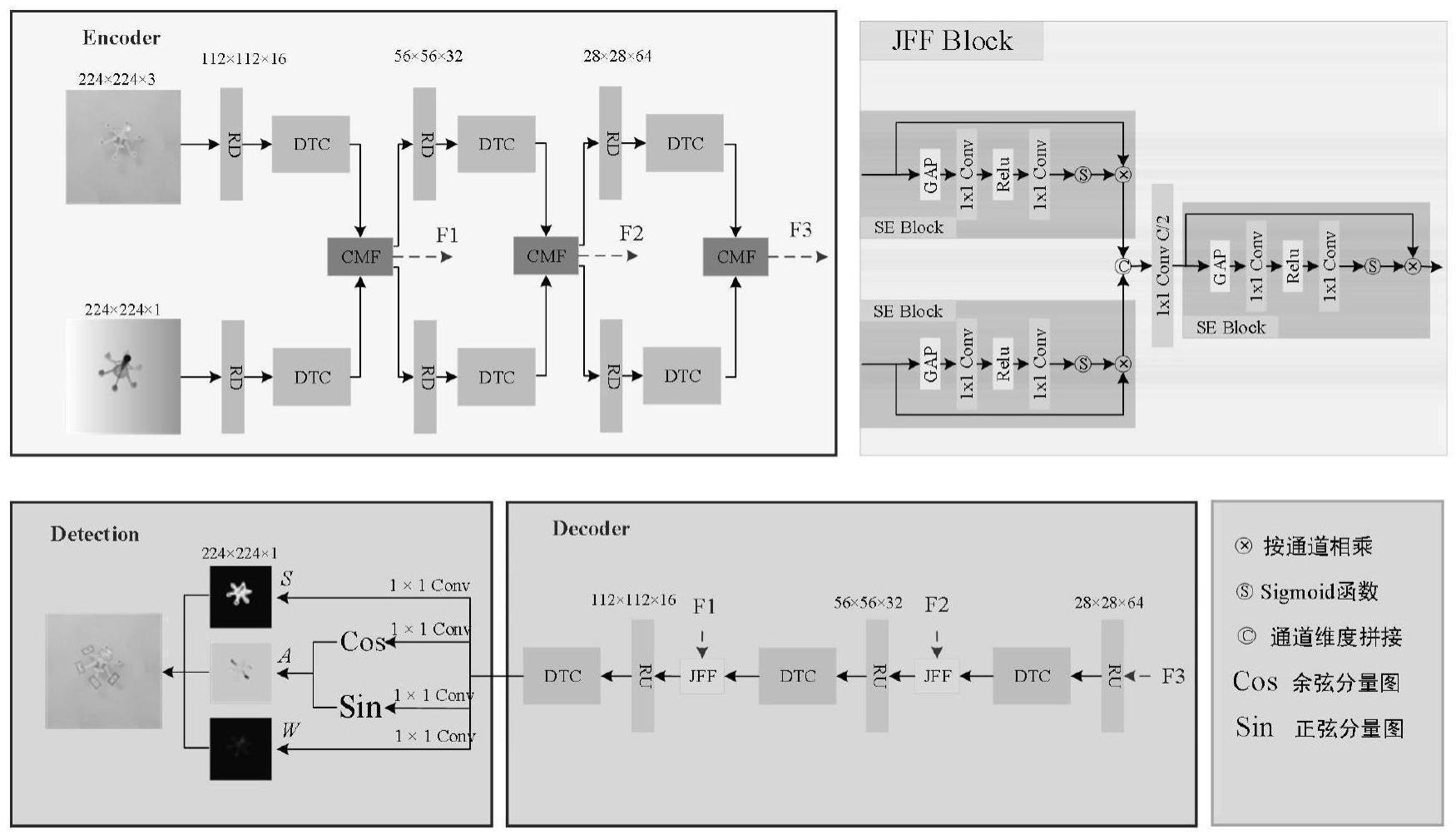
2、为实现上述目的,本发明提供如下技术方案:基于transformer-cnn混合架构的rgb-d跨模态交互融合机械臂抓取检测方法,至少包括以下步骤:
3、s1:由编码器、解码器和抓取预测模块组成网络架构,编码器用于对输入图像进行下采样编码提取抓取检测图像的特征信息,解码器对这些特征信息进行上采样解码分析,最后在抓取预测模型中实现像素级的抓取预测;
4、s2:图像特征编码,图像的特征编码是在网络的编码器模组中完成;
5、s3:图像特征解码,rgb和depth图像经过编码器编码后得到了f1、f2、f3三个不同层级的特征编码,将这三个特征编码输入到解码器进行特征解码;
6、s4:抓取位姿预测,检测图像经过编码器的编码和解码器的解码后转化成了满足抓取检测所需的特征向量,把该特征向量输入抓取预测模块实现端到端的基于关键点的像素级抓取预测,最后利用网络生成与检测图像大小相同的像素图来预测抓取位姿;
7、s5:基于关键点的像素级的抓取检测表示,对于平行夹爪式抓取器,抓取检测的目标是检测出图像中满足抓取任务的抓取矩形;
8、s6:训练数据的生成;
9、s7:损失函数,网络的损失函数l包括抓取矩形中心点损失ls抓取矩形角度和宽度损失la、lw。
10、优选的,所述解码器至少包括残差上采样模块、跳跃特征融合模块以及双流特征提取模块,所述编码器至少包括残差下采样模块、transformer-cnn双流特征提取模块以及跨模态交互融合编码器构成,所述transformer-cnn双流特征提取模块与双流特征提取模块相同。
11、优选的,所述s1至少包括以下步骤:
12、同一场景的rgb图像和depth图像被分别单独送入编码器中;
13、在编码器中两个图像分别输入两个相同结构的编码网络中,在编码过程中提取出两种模态各层级的特征信息输入跨模态交互融合编码器进行特征校准和交互融合;
14、收集到编码器各个阶段的特征信息输入到解码器各阶段进行解码获得解码特征;
15、解码特征再输入到抓取预测模块抓取预测模块获得抓取预测所需要的三种像素图:抓取分数图s、抓取角度图a和抓取宽度图w;
16、最后根据这三个像素图得到抓取矩形的中心位置、宽、高以及抓取矩形的旋转角度。
17、优选的,所述s2至少包括以下步骤:
18、残差下采样模块采用的是残差网络的设计,与原始的残差网络不同的是残差下采样模块使用泛化性更强的leaky-relu激活函数和更加稳定通用的frn归一化层替换了relu和bn层,在残差下采样模块中,第一个3x3卷积层用来使通道数翻倍,第二个3x3卷积层使分辨率减半,而残差连接流用1x1卷积和最大池化操作完成着两个操作;
19、transformer-cnn双流特征提取模块结合了cnn组成的残差网络和swin-transformer模块,以利用这两种网络架构的优势,在transformer-cnn双流特征提取模块中,输入的特征向量fin经过一个1×1卷积层(conv1×1(·))后被分别输入到swint分支(trans(·))和残差卷积网络分支(res(·))中进行特征提取获得在两个分支分别进行特征提取的时候互不干扰,这样局部和非局部特征可以独立并行处理,有助于更好地提取特征,保证网络性能的同时具有更强的网络稳定性;
20、把拼接(concat(·))后再用一个1x1的卷积层使其通道数目恢复与fin一致并与fin融合相加()得到最后的特征输出向量fout,整个过程公式化如下:
21、
22、
23、
24、跨模态交互融合编码器用于对rgb和depth图像特征流进行特征校正,减少噪声影响,并融合多模态互补特征信息形成增强的特征表示,利用rgb和depth两个模态特征的通道和空间相关性,对图像特征进行相互校准,实现更好的多模态特征提取和交互,形成更稳健的多模态特征信息;
25、跨模态交互融合编码器模块设计,使用全局平均池化来获得rgb特征图frgb和深度特征图fdepth中的全局特征向量,将两个特征向量输入一个3x3的卷积层和sigmoid激活函数中,以获得通道注意力向量和分别反映rgb特征和depth特征的重要性,按通道相乘将注意力向量应用于输入特征,通过这种方式,得到的特征图将明确地关注重要的信息,并抑制不必要的信息加强对场景理解;此过程定义为:
26、
27、
28、其中,i∈[rgb,depth],conv3×3(·)表示卷积核大小为3×3的卷积操作,avgpooling(·)表示全局平均池化操作,表示按通道相乘;
29、注意力向量和通过最大聚合函数max来获得rgb流和depth流中的权重最大特征通道注意力向量,然后对其做归一化运算(n(·)得到交互融合通道注意力向量attf,有效地抑制了两种模态低质量的特征响应,保留了信息量最大的视觉外观和几何特征;
30、利用rgb流中的高置信特征来过滤掉相同级别的异常depth特征,同时也抑制了depth流中的噪声特征;
31、attf分别与frgb和fdepth进行通道相乘获得通道上相互校准的特征向量和然后分别与和相加获得跨模态交互的通道增强特征和此过程定义为:
32、
33、
34、
35、其中,n(·)、max(·)分别表示归一化和最大聚合操作,表示逐元素相加;
36、为了克服不同模态间特征差异性,同时对局部信息的空间特征进行校正,在跨模态交互融合编码器中还利用两种模态特征的空间相关性进行了跨模态互补聚合;
37、首先,把frgb和fdepth拼接,分别用一个1x1卷积层把联合的特征图映射到两个空间权重图中,利用sigmoid激活函数得到两个互补校准的空间注意力图和将和与输入特征相乘即得到了空间互补校准的增强特征和此过程可表示为:
38、fm=concat(frgb,fdepth)
39、
40、
41、其中⊙表示在空间维度上相乘;最后交互联合和得到和作为下一个特征提取模块的输入。同时,和被进一步级联经过一个1×1卷积层生成跨模态融合特征作为解码器的解码特征输入。可表示为:
42、
43、
44、
45、优选的,所述s3至少包括以下步骤:
46、采用残差上采样模块使通道减半而分辨率变为原来的两倍,残差上采样模块中采用pixelshuffle操作来扩大分辨率,这种残差网络的设计相比于原始的残差网络模型的收敛速度会更快模型训练也更加稳定;
47、采用se-net的通道注意力的思想设计了一个跳跃特征融合模块,整个融合模块由三个se-block组成,首先用两个se-block对输入的特征信息进行初步加权,然后在通道维度上对加权后的两个特征图进行拼接,通过一个卷积层使其恢复为原来的通道,最后再次利用se block对融合后的特征进一步的加权,使用这种通道注意力机制,模型根据给定的输入来关注哪个模态的哪些特征以及抑制哪些特征,这样,在跳跃连接中只有最有用的信息被保留下来。
48、优选的,所述s4至少包括以下步骤:
49、通过四个1x1卷积将解码器输出的特征图转换为四个与检测图像分辨率一致的像素图,分别对应于分数图s、角度正弦分量图sin、角度余弦分量图cos和宽度图w;
50、最终的抓握点由s中值最大的像素点来确定,抓取矩形的宽度由w中对应的像素值决定,最后的抓取角度图a根据正弦和余弦分量图共同确定,抓取矩形的角度通过以下公式计算:
51、
52、sin(2θ)=2sin(θ)cos(θ)
53、cos(2θ)=cos2(θ)-sin2(θ)
54、其中sin(θ)和cos(θ)的值由角度分量图得到。
55、优选的,所述s5至少包括以下步骤:
56、将2d图像中的抓取矩形可以表示为g={x,y,u,v,θ},其中(x,y)、u、v、θ分别是矩形g的中心点坐标、宽度、高度以及相对于图像的水平方向的旋转角度;
57、对于检测图像img中的每一个像素点都与一个潜在的抓取矩形对应,用三个像素图来描述img中的所有潜在抓取:
58、
59、其中wi和hi是img的宽度和高度,s表示的是抓取分数图,图中每个像素点p(x,y)的值对应img中相同位置像素点潜在抓取矩形gp的抓取分数sp,其范围为[0,1];
60、spsp的值越高,则gp就越合适抓取物体,最终的抓取矩形由最大的sp对应的像素点决定;
61、a表示的是抓取角度图,图中像素点的值表示对应抓取矩形的旋转角度θ;
62、w表示的是抓取宽度图,图中像素点的值表示对应抓取矩形的宽度w,抓取矩形的高设置为w的一半。
63、优选的,所述s6至少包括以下内容:
64、实验中所用数据集的注释标签gt,由一系列的抓取矩形框组成;
65、把实验中所用数据集的注释标签gt转化为与本发明网络相适应的标签:sg、wg、ag;
66、把实验中所用数据集的注释标签gt转化为与本发明网络相适应的标签:sg、wg、ag;
67、sg:使用gt中抓取矩形的三分之一区域表示该抓取矩形的中心的可选区域,多个矩形的可选区域就组成了抓取对象的可抓取区域,即可作为抓取矩形中心的区域,把图中可抓取区域的值设置为1,其他其余设置为0,生成了一个像素级的标签sg;
68、wg:wg中的区域和sg中的一致,将在可抓取区域中的值设置为每个矩形的宽度的
69、ag:ag中的区域和sg一致,值设置为tan(2θ),其中θ为抓取矩形的旋转角度,tan(2θ)可由以下公式可得:
70、
71、优选的,所述s9中抓取矩形中心点损失ls抓取矩形角度和宽度损失la、lw的损失函数的表达式如下:
72、
73、
74、
75、l=λ1ls+λ2la+λ3lw
76、其中n指的是检测图像中像素点的数目,si、ai、wi指的是三个检测图中对应第i个像素点的值,sg、ag、wg指的是与训练数据集中抓取矩形注释标签相对应的三个像素图标签。λ1、λ2、λ3是各部分损失的权重系数。考虑到矩形中心点和角度的预测直接影响到抓取检测的准确率,λ1、λ2的值设置的比λ3更大一些,分别为1.5,1.5,1。
77、与现有技术相比,本发明的有益效果是:
78、1、本发明采用transformer和cnn的混合架构构建深度学习网络,利用一个跨模态交互融合编码器对rgb图像和depth图像不同模态的信息进行校准融合,并减少了depth图像中噪声因素的影响,整个网络架构由编码器、解码器和抓取预测模块组成,encoder用于对输入图像进行下采样编码提取抓取检测图像的特征信息,decoder对这些特征信息进行上采样解码分析,最后在detection中实现像素级的抓取预测;
79、2、本发明为了充分利用抓取检测的多模态特征信息并减少深度图像中噪音的影响,本发明提出了一种基于transformer-cnn混合架构的rgb-d跨模态交互融合机械臂抓取检测模型。该模型引入了一种新型的跨模态特征交互融合编码器,利用两个相同的特征编码器分别对rgb图像和depth图像进行特征编码,然后收集到各层级的编码在跨模态特征交互融合编码器中进行特征校准和特征融合得到增强的特征表示;
80、3、本发明为了获得抓取检测图像更加全面和细节的特征信息,提出了一种双流并行的transformer-cnn混合网络架构,它有效的结合了transformer和cnn的优点,最大限度的保留了图像的局部特征和全局表示;
81、4、本发明提出了一种针对深度学习网络中跳跃连接特征融合的跳跃特征融合模块,模型可以根据给定的输入来关注哪个模态的哪些特征以及抑制哪些特征,在跳跃连接中只有最有用的信息被保留下来,从而提高模型的性能。
- 还没有人留言评论。精彩留言会获得点赞!