面向手势识别的稀疏二值神经网络硬件加速器
本发明属于集成电路,具体为一种面向手势识别的稀疏二值神经网络硬件加速器。
背景技术:
1、自然的、无障碍的、实效性高的、无接触的新型智能人机交互系统成为信息发展中必然趋势。手势作为人机交互领域极其重要的通道之一,具有应用广泛,操作简单,使用频率高等优点。然而目前手势识别大多采用卷积神经网络进行手势识别,然而卷积神经网络模型一般具有参数密集型和计算密集型的特性,在硬件实现中具有高功耗、高延时的特性,基于卷积神经网络的手势识别对于资源要求高,相应的功耗也会过高,无法部署于移动端、iot、可穿戴设备中。二值网络作为类似于卷积神经网络模型,输入和权重均是1bit的数据,采用xnor-popcount来代替原始卷积神经网络的乘累加操作,具有低数据量、低计算量的特性,更能够适用于低功耗手势识别硬件的需要;考虑到由于是rgb的输入导致二值网络的第一层网络一般采用乘累加计算,采用稀疏的手势边缘能够保证第一层计算也是xnor-popcount;此外稀疏的手势边缘使二值网络的激活图像中存在大量相同的向量,这些向量是由所有通道的1bit的激活数据组成的,并且在二值网络每一层中都大量存在。这些向量的计算结果可以通过软件预测出来,并会带来大量的冗余计算,带来不必要的功耗和计算周期的消耗。因此,设计一种面向手势识别的高能效稀疏二值神经网络硬件加速器来实现超高能效的手势识别硬件已经成为迫切需要。
技术实现思路
1、为了克服现有技术的不足,本发明的目的在于提出一种面向手势识别的资源消耗少、功耗低、计算速度快的高能效稀疏二值神经网络硬件加速器,以加速稀疏二值网络计算,提升硬件能效。
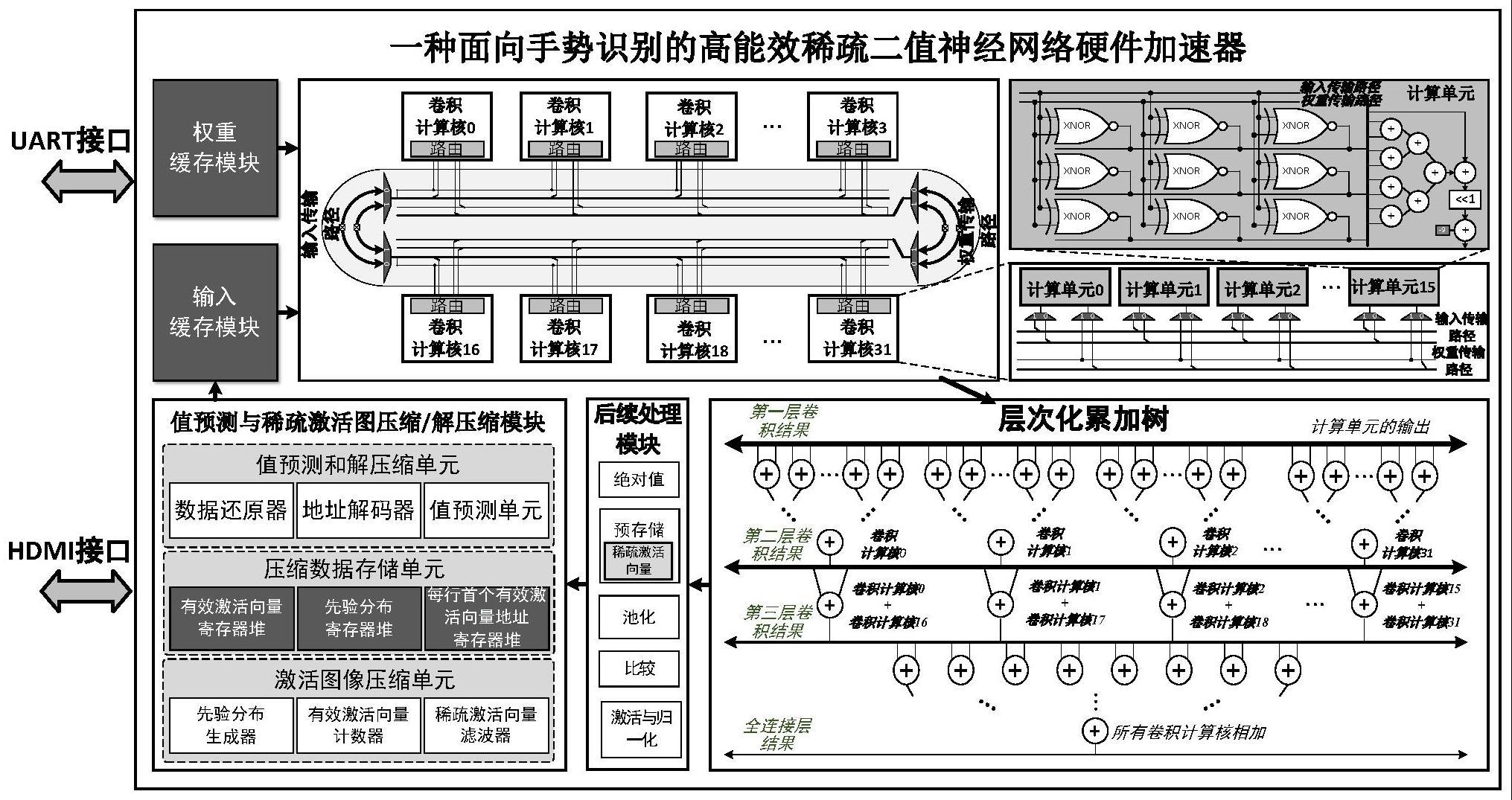
2、本发明提供的面向手势识别的高能效稀疏二值神经网络硬件加速器,其结构包括:输入缓存模块,权重缓存模块,数据传输片上网络,32个卷积计算核,层次化累加树,后续处理单元,hdmi接口,uart接口,值预测与稀疏激活图压缩/解压缩模块;其中:
3、所述uart接口,用于接收主机传输的权重数据并传输至所述权重缓存模块,权重缓存模块的大小为15.83kb,负责存储手势识别算法所需的权重数据;所述后续处理单元在完成全连接的计算后通过uart接口将识别的结果发送至主机;
4、所述hdmi接口,用于传输边缘手势图像至所述输入缓存模块进行存储;当完整的图像传输完成时,启动输入数据和权重数据传输过程;此外,所述输入缓存模块也会暂存所述值预测与系数激活图像压缩/解压缩模块的还原数据;
5、计算启动后,所述数据传输片上网络根据卷积映射算法将所述输入缓存模块的输入数据和所述权重缓存模块的权重数据传输至所述卷积计算核内的计算单元阵列;其中所述数据传输片上网络由输入传输路径和权重传输路径两个部分组成,每条路径都支持单-多播的数据传输过程;
6、所述卷积计算核接收到输入数据和权重数据后,根据其路由进行判断,将对应的数据保存;所述卷积计算核由16个计算单元组成,每一个所述计算单元可以执行3x3的二值网络卷积操作,即3x3 xnor-popcount;32个卷积计算核可以在每个周期内执行高达4608个(32×16×3×3)的xnor-popcount操作;将每一个所述计算单元计算的结果传输至所述层次化累加树,计算卷积操作的最终结果;
7、所述层次化累加树,接收到每一个所述计算单元的结果后,根据卷积映射算法对这些结果进行累加计算;第一层卷积的结果是每个所述计算单元的输出,输出的个数为32x16;第二层卷积的结果是由每个所述卷积计算核的所有所述计算单元的累加结果,输出的个数为32个;第三层卷积的结果是由每两个所述卷积计算核的累加结果的进一步累加,输出的个数为16个;最后的全连接层的结果是由所有的所述卷积计算核的累加结果的累加结果,输出的个数为1个;每一层的输出结果可以直接传输至所述后续处理模块;
8、所述后续处理单元,支持绝对值、池化、比较、激活与归一化操作;若所述后续处理单元接收到所述层次化累加树的每一层卷积计算结果,则所述后续处理单元按顺序执行绝对值、池化和比较操作,生成二值化的激活向量传输至所述值预测与系数激活图压缩/解压缩模块,所述激活向量是多个通道的输出激活图像的同一位置像素点的组合;若所述后续处理单元接收到所述层次化累加树模块的全连接层结果,执行激活与归一化操作,从而得到最终手势的分类结果,并通过所述uart接口传输至主机;
9、所述后续处理单元包含预储存单元,用于存储软件提前预测的稀疏激活向量;所述预存储单元在将二值化的激活图像传输至所述值预测与系数激活图压缩/解压缩模块的同时会将对应的所述预测结果传输至所述值预测与系数激活图压缩/解压缩模块;
10、所述值预测与稀疏激活图压缩/解压缩模块,由激活图像压缩单元、压缩数据存储单元以及值预测和解压缩单元组成;压缩数据存储单元包括有效激活向量寄存器堆、先验分布寄存器堆、每行首个有效激活向量地址寄存器堆:其中:
11、所述激活图像压缩单元由先验分布生成器、有效激活向量计数器和稀疏激活向量滤波器构成;所述稀疏激活向量滤波器接收到所述后续处理单元发送的二值化的激活向量和稀疏激活向量后,将两个向量进行比较,若是相等,则说明激活向量为稀疏激活向量,向所述先验分布生成器和所述有效激活向量计数器发送0值;若否,则说明激活向量为有效激活向量,向所述先验分布生成器和所述有效激活向量计数器发送1值,并将有效激活向量保存至所述压缩数据存储单元的有效激活向量寄存器堆;所述有效激活向量计数器累加从所述稀疏激活向量滤波器传输的数据,并在一行数据传输结束时将累加结果保存至所述压缩数据存储单元的每行首个有效激活向量地址寄存器堆;所述先验分布生成器将所述稀疏激活向量滤波器传输的数据进行拼接,并在一行数据传输结束时将拼接的数据发送至先验分布寄存器堆;
12、所述值预测和解压缩单元在当前层卷积完成后,执行值预测和解压缩过程;所述值预测和解压缩单元由值预测单元、地址解码器和数据还原器组成;所述值预测单元在进行下一层计算时,先从先验分布寄存器堆中取出4行先验分布,以4x4的卷积核大小步长为2进行滑动,每次取出4x4的先验分布块;先判断4x4的先验分布块是否全为0值,若是,则输出结果必为下一层的稀疏激活向量,跳过所有计算;若否,则分割成4个3x3的先验分布块,判断每一个3x3先验分布块是否全为0:若是,则卷积计算的结果是可以被预测的,该值也是被保存于所述后续处理模块的所述预存储单元,以备后续执行池化操作;若否,说明计算结果不可预测,将该3x3的先验分布块发送至所述地址解码器进行有效激活向量地址的计算;所述地址解码器读取所述每行首个有效激活向量地址寄存器堆中的地址数据,并根据3x3的先验分布块生成9个地址;其中3x3的先验分布块中0值代表着稀疏激活向量,该地址指向稀疏激活向量,3x3的先验分布块中1值代表着有效激活向量,该地址指向所述有效激活向量寄存器堆中的有效激活向量;所述数据还原器根据9个地址分别读取有效激活向量和稀疏激活向量,还原为参与计算的输入数据,并将还原后的输入数据保存至所述输入缓存模块。
13、与现有技术相比,本发明技术特点和优势主要有:
14、(1)本发明为二值网络的激活图像引入了新的稀疏性,通过稀疏的手势边缘作为二值网络的输入能够在二值网络每一层的激活图像中引入大量相同的向量,这些向量在每一层的计算结果是可以通过软件预测出来,因此二值网络可以进行激活图像的压缩并跳过大量冗余的卷积计算;
15、(2)激活图像编码单元能够无损压缩二值网络每一层稀疏激活图像,将原始的激活图像按照激活向量的形式传输至加速器中,加速器可以根据已知的稀疏向量将激活图像保存为有效向量、标签值和有效向量个数,从而实现较高的压缩比,减少数据存储数据量,降低数据读写次数,从而优化硬件功耗;
16、(3)值预测单元在先验分布图上预测二值网络计算过程,并且根据软件预测的结果能够实现冗余计算的跳过,从而降低二值网络计算功耗和延时,实现二值网络能效的进一步优化;
17、(4)加速器采用两条数据传输片上网络,支持单-多播数据传输,能够快速有效的将数据发送至所有的计算单元;
18、(5)层次化累加树逐层向下累加能够复用部分的计算资源,在资源上实现部分共享,降低资源消耗;
19、(6)稀疏二值神经网络硬件加速器通过值预测技术和数据压缩计算跳过了稀疏二值网络卷积计算中存在的重复计算,压缩了输出数据来减小数据存储的资源消耗,最终在计算速度上实现了提升,降低了功耗,实现了能效的优化。
- 还没有人留言评论。精彩留言会获得点赞!