满意度识别方法、装置、电子设备及可读存储介质与流程
本技术涉及机器学习,尤其涉及一种满意度识别方法、装置、电子设备及可读存储介质。
背景技术:
1、随着科技的不断发展,对于运营商而言,基于模型进行用户满意度识别俨然成为了主流识别手段,所以,构建高识别精度的识别模型成为了运营商的重要研究方向之一。
2、目前,通常有以下两种方式构建识别模型:一是通过总结客观数据结合主观经验判断为模型中不同评价指标赋予权重,而后基于赋权评价指标体系为不同用户进行满意度评分,最终通过设定的阈值输出不满意用户清单;二是采用过采样或者欠采样的方式基于已有样本数据集进行处理,进而在正负样本均衡化形成建模数据集后,选用相关算法构建识别模型,并通过人工优化识别模型的样本集,即,由于样本数据量的受限,在构建识别模型的样本数据集时需要依赖于人工参与,进而导致出现识别模型输出的满意度识别结果缺乏客观性的情况,所以,当前基于模型进行用户满意度识别的识别精准性低。
技术实现思路
1、本技术的主要目的在于提供一种满意度识别方法、装置、电子设备及可读存储介质,旨在解决现有技术中基于模型进行用户满意度识别的识别精准性低的技术问题。
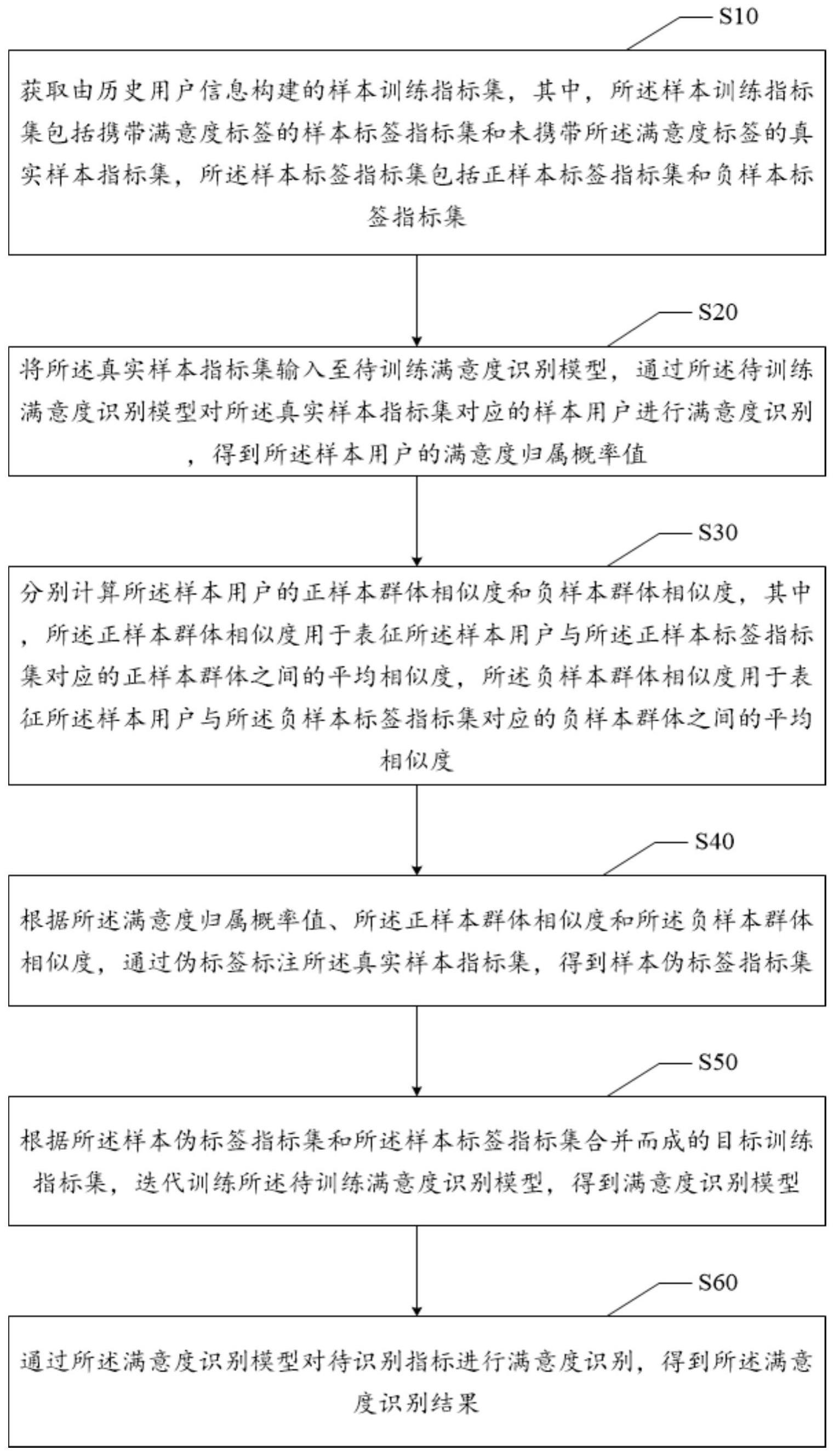
2、为实现上述目的,本技术提供一种满意度识别方法,所述满意度识别方法包括:
3、获取由历史用户信息构建的样本训练指标集,其中,所述样本训练指标集包括携带满意度标签的样本标签指标集和未携带所述满意度标签的真实样本指标集,所述样本标签指标集包括正样本标签指标集和负样本标签指标集;
4、将所述真实样本指标集输入至待训练满意度识别模型,通过所述待训练满意度识别模型对所述真实样本指标集对应的样本用户进行满意度识别,得到所述样本用户的满意度归属概率值;
5、分别计算所述样本用户的正样本群体相似度和负样本群体相似度,其中,所述正样本群体相似度用于表征所述样本用户与所述正样本标签指标集对应的正样本群体之间的平均相似度,所述负样本群体相似度用于表征所述样本用户与所述负样本标签指标集对应的负样本群体之间的平均相似度;
6、根据所述满意度归属概率值、所述正样本群体相似度和所述负样本群体相似度,通过伪标签标注所述真实样本指标集,得到样本伪标签指标集;
7、根据所述样本伪标签指标集和所述样本标签指标集合并而成的目标训练指标集,迭代训练所述待训练满意度识别模型,得到满意度识别模型;
8、通过所述满意度识别模型对待识别指标进行满意度识别,得到所述满意度识别结果。
9、为实现上述目的,本技术还提供一种满意度识别装置,所述满意度识别装置包括:
10、获取模块,用于获取由历史用户信息构建的样本训练指标集,其中,所述样本训练指标集包括携带满意度标签的样本标签指标集和未携带所述满意度标签的真实样本指标集,所述样本标签指标集包括正样本标签指标集和负样本标签指标集;
11、第一识别模块,用于将所述真实样本指标集输入至待训练满意度识别模型,通过所述待训练满意度识别模型对所述真实样本指标集对应的样本用户进行满意度识别,得到所述样本用户的满意度归属概率值;
12、计算模块,用于分别计算所述样本用户的正样本群体相似度和负样本群体相似度,其中,所述正样本群体相似度用于表征所述样本用户与所述正样本标签指标集对应的正样本群体之间的平均相似度,所述负样本群体相似度用于表征所述样本用户与所述负样本标签指标集对应的负样本群体之间的平均相似度;
13、标注模块,用于根据所述满意度归属概率值、所述正样本群体相似度和所述负样本群体相似度,通过伪标签标注所述真实样本指标集,得到样本伪标签指标集;
14、训练模块,用于根据所述样本伪标签指标集和所述样本标签指标集合并而成的目标训练指标集,迭代训练所述待训练满意度识别模型,得到满意度识别模型;
15、第二识别模块,用于通过所述满意度识别模型对待识别指标进行满意度识别,得到所述满意度识别结果。
16、本技术还提供一种电子设备,所述电子设备包括:至少一个处理器以及与所述至少一个处理器通信连接的存储器,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如上述的满意度识别方法的步骤。
17、本技术还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有实现满意度识别方法的程序,所述满意度识别方法的程序被处理器执行时实现如上述的满意度识别方法的步骤。
18、本技术还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述的满意度识别方法的步骤。
19、本技术提供了一种满意度识别方法、装置、电子设备及可读存储介质,也即,获取由历史用户信息构建的样本训练指标集,其中,所述样本训练指标集包括携带满意度标签的样本标签指标集和未携带所述满意度标签的真实样本指标集,所述样本标签指标集包括正样本标签指标集和负样本标签指标集;将所述真实样本指标集输入至待训练满意度识别模型,通过所述待训练满意度识别模型对所述真实样本指标集对应的样本用户进行满意度识别,得到所述样本用户的满意度归属概率值;分别计算所述样本用户的正样本群体相似度和负样本群体相似度,其中,所述正样本群体相似度用于表征所述样本用户与所述正样本标签指标集对应的正样本群体之间的平均相似度,所述负样本群体相似度用于表征所述样本用户与所述负样本标签指标集对应的负样本群体之间的平均相似度;根据所述满意度归属概率值、所述正样本群体相似度和所述负样本群体相似度,通过伪标签标注所述真实样本指标集,得到样本伪标签指标集;根据所述样本伪标签指标集和所述样本标签指标集合并而成的目标训练指标集,迭代训练所述待训练满意度识别模型,得到满意度识别模型;通过所述满意度识别模型对待识别指标进行满意度识别,得到所述满意度识别结果。
20、本技术在进行满意度识别时,首先获取通过历史用户信息构建的样本训练指标集,由于样本训练指标集中包含有未携带满意度标签的真实样本指标集、携带满意度标签的正样本标签指标集和携带满意度标签的负样本标签指标集,进而通过等待训练的满意度识别模型首先输出真实样本指标集对应的样本用户的满意度归属概率值,进而分别基于正样本标签指标集计算得到样本用户的正样本群体相似度和基于负样本标签指标集计算得到样本用户的负样本群体相似度,进而通过满意度归属概率值、正样本群体相似度和负样本群体相似度可伪标签标注得到样本伪标签指标集,最终通过样本伪标签指标集和样本标签指标集合并而成的目标训练指标集,迭代训练待训练满意度识别模型,得到满意度识别模型,由于样本伪标签指标集是基于未携带满意度标签的真实样本指标集得到的,进而即可实现自动扩充用于迭代训练待训练满意度识别模型的样本训练指标集的目的。
21、由于在样本训练指标集的基础上可主动扩充得到样本伪标签指标集,即,通过目标训练指标集训练待训练满意度识别模型消弭了样本数据量的限制,与此同时,由于样本伪标签指标集携带客观反馈用户满意度的真实信息,进而确保了样本数据扩充过程中的客观性,最终通过扩充后的目标训练指标集,即可实现训练得到拟合精度更高的满意度识别模型,由于满意度识别模型用于识别用户的满意度,进而通过构建得到满意度识别模型即可对用户满意度进行精准识别。
22、基于此,本技术通过样本训练指标集中的真实样本数据集进行伪标签标注得到样本伪标签指标集,由于样本伪标签指标集是基于满意度归属概率值、正样本群体相似度和负样本群体相似度共同决定的,进而样本伪标签指标集的样本指标具备客观性,进而通过样本伪标签指标集和样本训练指标集合并而成的目标训练指标集进行待训练满意度识别模型的迭代训练,即可得到训练得到满意度识别模型,从而实现了通过主动扩充具备客观性的样本训练指标集,构建得到可靠性更高的满意度识别模型的目的。而非在数据量受限的情况下依赖于人工参与样本数据的扩充。即,克服了由于样本数据量的受限,在构建识别模型的样本数据集时需要依赖于人工参与,进而导致出现识别模型输出的满意度识别结果缺乏客观性的情况的技术缺陷,所以,提升了基于模型进行用户满意度识别的识别精准性。
- 还没有人留言评论。精彩留言会获得点赞!