一种基于深度强化学习的左心室内膜图像分割方法和系统
本发明涉及计算机医学图像处理、深度学习和强化学习,更具体地,涉及一种基于深度强化学习的左心室内膜图像分割方法和系统。
背景技术:
1、强化学习(reinforcement learning)是机器学习的一个分支,其模型能够自主学习,实现从环境中不断尝试和探索来达到最优决策的过程,而dqn(deep q-network)是一种基于深度神经网络和q-learning算法的强化学习算法。在dqn中,深度神经网络被用来逼近q函数(q-function),并将其作为价值函数,使得模型能够通过最大化q函数来实现最优决策。q函数定义了在给定状态下执行某一动作所获得的期望奖励,因此,dqn的目标是训练该网络以最大化期望奖励。dqn算法的核心是q-learning算法,它是一种基于bellman方程的强化学习算法。该算法通过从经验池(experience replay)中随机抽样来训练神经网络,并使用固定的目标网络(target network)来解决问题。这些技术有助于提高学习速度和稳定性,使模型更加准确和可靠。
2、dqn算法已经在各种领域取得了很好的效果,如计算机游戏、机器人控制、自然语言处理等。在计算机游戏方面,dqn已经在atari游戏中取得了与人类水平相当的表现。在机器人控制方面,dqn通过优化深度神经网络的参数,能够让机器人更好地学习控制策略,并实现高效率和精准性的运动。此外,在自然语言处理领域,dqn可以被用来训练智能对话系统,使其更加自然、人性化、流畅。
3、double dqn(double deep q-network)和dueling dqn都是基于dqn的改进版,用来提高dqn算法在强化学习中的稳定性和性能。
4、double dqn通过使用两个神经网络来解决dqn算法中的过度估计的问题。具体地说,在dqn中,目标q值是通过目标网络计算得到,并且由于存在最大化操作,可能导致对目标q值的过度估计。而double dqn使用另外一个神经网络来计算最大q值,以减小这种估计误差,从而提高模型的稳定性和性能。
5、dueling dqn则是通过将q函数分解为状态价值函数(state-value function)和优势函数(advantage function)两部分来解决dqn算法中的不稳定性问题。在传统的dqn中,q函数直接输出某一个动作的q值;而在dueling dqn中,q函数首先输出状态值函数和优势函数,然后将它们组合起来得到最终的q值。状态值函数评估当前状态的价值,而优势函数评估每个动作相对于其他动作的优劣。这种拆分方式可以提高q函数的表示效率,并且使模型更加稳定和可靠。
6、现有技术中公开了一种左心室图像分割方法、装置、设备及存储介质,该方法包括:接收待分割的左心室图像,将左心室图像输入训练好的图像分割网络中进行分割,获得图像分割网络处理得到的左心室分割图像并输出,其中,图像分割网络为深度学习网络,包括下采样部分和上采样部分,上采样部分包括第一卷积层和下采样网络层,上采样部分包括第二卷积层和上采样网络层,从而实现左心室图像的自动分割,提高了左心室图像分割的效率和效果;现有技术中的方法仅使用单个神经网络模型来进行左心室图像分割,不仅需要大量的训练数据,同时起始点的定位精度不高,因此分割精度也较低。
技术实现思路
1、本发明为克服上述现有技术需要大量的训练数据以及分割精度较低的缺陷,提供一种基于深度强化学习的左心室内膜图像分割方法和系统,能够提高模型的性能并提高分割精度。
2、为解决上述技术问题,本发明的技术方案如下:
3、一种基于深度强化学习的左心室内膜图像分割方法,包括以下步骤:
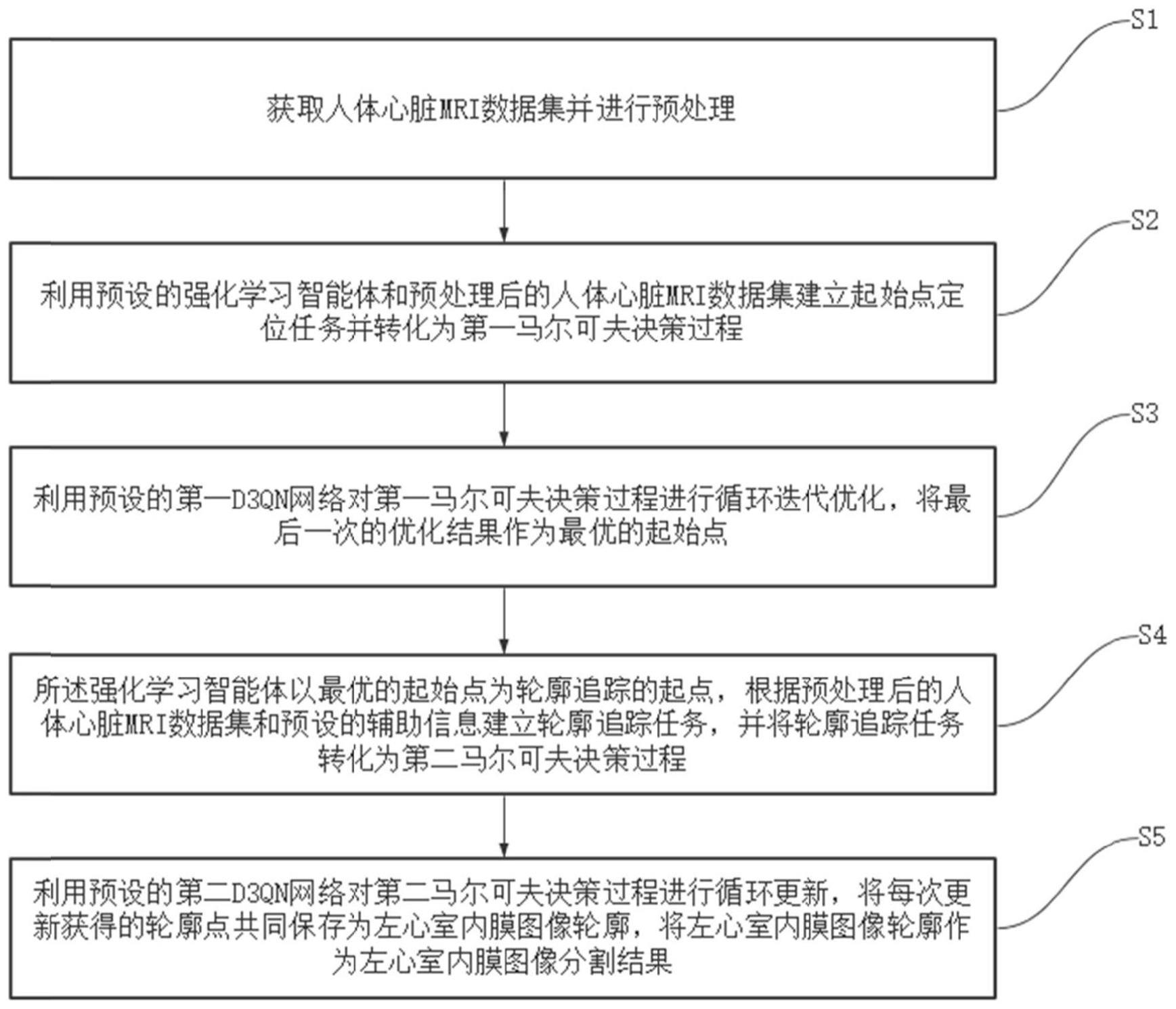
4、s1:获取人体心脏mri数据集并进行预处理;
5、s2:利用预设的强化学习智能体和预处理后的人体心脏mri数据集建立起始点定位任务并转化为第一马尔可夫决策过程;
6、s3:利用预设的第一d3qn网络对第一马尔可夫决策过程进行循环迭代优化,将最后一次的优化结果作为最优的起始点;
7、s4:所述强化学习智能体以最优的起始点为轮廓追踪的起点,根据预处理后的人体心脏mri数据集和预设的辅助信息建立轮廓追踪任务,并将轮廓追踪任务转化为第二马尔可夫决策过程;
8、s5:利用预设的第二d3qn网络对第二马尔可夫决策过程进行循环更新,将每次更新获得的轮廓点共同保存为左心室内膜图像轮廓,将左心室内膜图像轮廓作为左心室内膜图像分割结果。
9、优选地,所述步骤s1中预处理的具体方法为:
10、对人体心脏mri数据集中的每张心脏mri图像提取左心室roi及其周围若干数量的roi,将提取到的所有roi利用双线性插值的方法调整至预设大小,将调整大小后的所有roi进行归一化处理,完成预处理。
11、优选地,所述步骤s2中的起始点定位任务具体为:
12、在所述起始点定位任务中,强化学习智能体的第一状态为每个预处理后的人体心脏mri数据,并任选一点作为起始点定位任务的起点;
13、强化学习智能体的动作为:以当前点为中心,强化学习智能体从方向集合{0,1,2,3,4,5,6,7}中选择一个方向进行若干像素长度的移动;
14、所述方向集合中的0~7分别表示:根据二维笛卡尔坐标定义的左、左上、上、右上、右、右下、下和左下八个方向;
15、强化学习智能体的第一奖励r1为:设置目标点,计算当前点位置与目标点之间的最短欧氏距离dcurr,以及下一步点位置与目标点之间的最短欧氏距离dnext,则第一奖励r1为:r1=dcurr-dnext。
16、优选地,所述步骤s3中的第一d3qn网络具体为:
17、所述第一d3qn网络包括依次连接的:输入层、第一2d卷积层、第一2d最大池化层、第二2d卷积层、第二2d最大池化层、第三2d卷积层、第三2d最大池化层、第四2d卷积层、fc模块和输出层;
18、所述fc模块包括两条分支,一条分支为依次连接的第一优势函数fc层和第二优势函数fc层,另一条分支为依次连接的第一价值函数fc层和第二价值函数fc层。
19、优选地,所述步骤s4中的轮廓追踪任务具体为:
20、在所述轮廓追踪任务中,强化学习智能体的第二状态为添加了边缘检测辅助信息的、预处理后的人体心脏mri数据,并以起始点定位任务获得的最优的起始点为轮廓追踪的起点;
21、强化学习智能体的动作为:以当前点为中心,强化学习智能体从方向集合{0,1,2,3,4,5,6,7}中选择一个方向进行若干像素长度的移动;
22、所述方向集合中的0~7分别表示:根据二维笛卡尔坐标定义的左、左上、上、右上、右、右下、下和左下八个方向;
23、强化学习智能体的第二奖励r2为:
24、r2=rtrend+rdist+rclus
25、
26、
27、
28、其中,d1为当前点与下一步期待到达的目标点之间的距离,d2为下一步实际到达的点与下一步期待到达的目标点之间的距离,step_size为智能体的动作步长,davg为d1和d2的平均值,d为预设阈值;a为预设折扣;std为智能体最近走过的n个轨迹点坐标的标准差。
29、优选地,所述边缘检测辅助信息具体为sobel算子边缘检测信息。
30、优选地,所述步骤s5中的第二d3qn网络具体为:
31、所述第二d3qn网络包括依次连接的resnet18网络、2d自适应平均池化层和所述fc模块。
32、本发明还提供一种基于深度强化学习的左心室内膜图像分割系统,应用上述的一种基于深度强化学习的左心室内膜图像分割方法,包括:
33、数据预处理模块:用于获取人体心脏mri数据集并进行预处理;
34、起始点定位任务构建模块:用于利用预设的强化学习智能体和预处理后的人体心脏mri数据集建立起始点定位任务并转化为第一马尔可夫决策过程;
35、起始点定位模块:用于利用预设的第一d3qn网络对第一马尔可夫决策过程进行循环迭代优化,将最后一次的优化结果作为最优的起始点;
36、轮廓追踪任务构建模块:所述强化学习智能体以最优的起始点为轮廓追踪的起点,用于根据预处理后的人体心脏mri数据集和预设的辅助信息建立轮廓追踪任务,并将轮廓追踪任务转化为第二马尔可夫决策过程;
37、轮廓追踪模块:用于利用预设的第二d3qn网络对第二马尔可夫决策过程进行循环更新,将每次更新获得的轮廓点共同保存为左心室内膜图像轮廓,将左心室内膜图像轮廓作为左心室内膜图像分割结果。
38、本发明还提供一种计算机可读的存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述方法中的步骤。
39、本发明提供一种电子设备,包括处理器以及存储器,所述存储器存储有计算机可读取指令,当所述计算机可读取指令由所述处理器执行时,运行上述方法中的步骤。
40、与现有技术相比,本发明技术方案的有益效果是:
41、本发明提供一种基于深度强化学习的左心室内膜图像分割方法和系统,首先获取人体心脏mri数据集并进行预处理;利用预设的强化学习智能体和预处理后的人体心脏mri数据集建立起始点定位任务并转化为第一马尔可夫决策过程;利用预设的第一d3qn网络对第一马尔可夫决策过程进行循环迭代优化,将最后一次的优化结果作为最优的起始点;所述强化学习智能体以最优的起始点为轮廓追踪的起点,根据预处理后的人体心脏mri数据集和预设的辅助信息建立轮廓追踪任务,并将轮廓追踪任务转化为第二马尔可夫决策过程;最后利用预设的第二d3qn网络对第二马尔可夫决策过程进行循环更新,将每次更新获得的轮廓点共同保存为左心室内膜图像轮廓,将左心室内膜图像轮廓作为左心室内膜图像分割结果;
42、本发明提供了一种全新的方法用于定位轮廓追踪的起始点,与现有的监督学习输出轮廓特征再在特征图上选取点不同,该方法的强化学习决策过程类似于人类的思考、决策过程,从某一位置开始移动,直到到达目的地;创新地设计了奖励函数,其中趋势奖励rtrend的设计最为有效,该奖励能使智能体更贴近目标轮廓移动,同时也为类似的跟踪任务的奖励设置提供了启示;同时,本发明引入了double dqn和dueling dqn,形成d3qn,相对于传统dqn具有更好的收敛速度和更强的模型表达能力,能更好地处理状态值和动作值之间的关系,减少过度估计的问题,能够在复杂环境中提供更加准确、高效的决策策略;另外,该方法可以解决基于深度学习的方法需要大量数据的问题,因为强化学习可以通过试错的方法进行学习,也可以利用先验知识进行学习,从而提高模型的性能,并且与深度学习基线方法相比,可以达到更高的分割精度。
- 还没有人留言评论。精彩留言会获得点赞!