基于语法感知的灰盒模糊测试方法及装置
本发明涉及软件安全,具体是涉及一种基于语法感知的灰盒模糊测试方法及装置。
背景技术:
1、模糊测试是一种自动化的软件测试技术,通过向目标程序提供大量无效或意外的输入样本来触发意想不到的程序行为(如断言失败、崩溃或挂起),从而检测安全漏洞以确保软件与系统安全。根据输入样本生成方式,模糊器可分为基于生成和基于变异的;根据对目标程序内部结构的利用程度,模糊器可分为白盒、灰盒或黑盒。近年来,由代码覆盖率指导的灰盒模糊测试已成为实践中最有效的发现安全漏洞的技术之一。
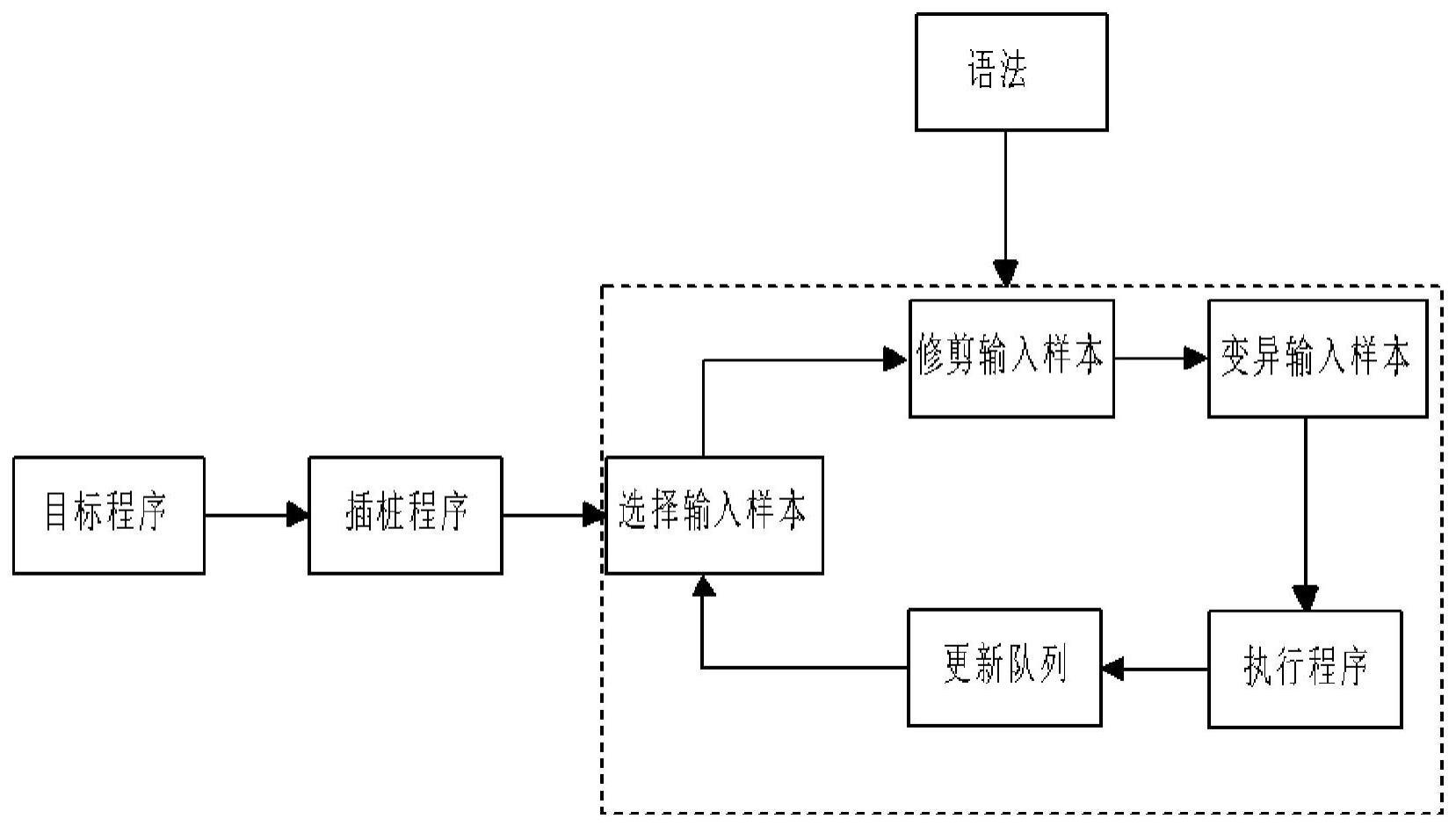
2、afl(american fuzzy lop)是一种由覆盖率指导的灰盒模糊器,其工作流程包括对目标程序进行插桩和模糊测试。插桩捕获分支(边缘)的覆盖范围和命中数,而模糊过程包括选择样本、修剪、变异、运行程序和更新队列等子步骤。在处理紧凑和非结构化的输入时,afl表现出很高的模糊效率。但是,对于处理遵循特定语法的结构化输入(如xml和javascript)的程序,此类模糊器存在问题。这类程序通常分为语法解析、语义检查和程序执行等阶段,而现有的模糊器很难针对这些阶段发现深层次的错误。afl内置的修剪策略(如删除数据块)无视样本的语法结构,易于违反语法或样本结构从而使其无效,导致目标程序只能处理一部分输入样本且最终卡在语法解析阶段。afl中的变异策略(如位翻转)也无视样本的语法结构,导致大多数变异后的输入样本不能通过语法解析并在早期被拒绝,这会浪费大量时间并仅能发现解析错误。
技术实现思路
1、(一)要解决的技术问题
2、本发明主要针对以上问题,提出了一种基于语法感知的灰盒模糊测试方法及装置,其目的是解决如何高效地挖掘处理结构化输入的程序中的漏洞。
3、(二)技术方案
4、为实现上述目的,本发明一方面提供了一种基于语法感知的灰盒模糊测试方法,包括如下步骤:
5、步骤1、从存储初始输入样本以及触发新覆盖的输入样本的队列中选择一个输入样本;
6、步骤2、将从所述队列中选择的输入样本基于语法感知的修剪策略对该队列中选择的输入样本进行修剪;
7、步骤3、对修剪后的样本进行基于语法感知的变异策略对该修剪后的样本进行变异操作,生成新输入样本;
8、步骤4、将变异后的新输入样本投入到程序中执行;
9、步骤5、如果触发新的覆盖,则将其添加到队列中以更新队列,否则,丢弃该变异样本。
10、进一步地,在步骤2中,所述基于语法感知的修剪策略的具体步骤包括:
11、步骤2.1、将要修剪的输入样本按照语法解析为抽象语法树;
12、步骤2.2、如果出现解析错误,则使用afl内置的修剪策略;否则,继续执行下一步;
13、步骤2.3、从抽象语法树中剪掉一个子树;
14、步骤2.4、如果修剪后覆盖率没有发生变化,则继续尝试修剪其他子树;否则,保留子树并尝试修剪下一个子树。
15、进一步地,在步骤2.2中,使用afl内置的修剪策略的步骤包括:
16、步骤2.2.1、将输入样本划分为字节的块,并且将每个块视为独立的数据单元;
17、步骤2.2.2、对每个块进行删除操作,如果删除后的输入样本在执行程序时覆盖率没有变化,则将该块删除,重复该步骤直到所有块都被遍历完毕;
18、步骤2.2.3、根据删除操作的顺序和结果,生成新的输入样本。
19、进一步地,在步骤3中,所述基于语法感知的变异策略包括基于字典的变异操作,所述基于字典的变异操作包括:
20、步骤3.1、确定修剪后的样本中的标记边界;
21、步骤3.2、从预定义的字典中选择一个标记;
22、步骤3.3、将选定的标记插入到修剪后的样本中的标记边界上;
23、步骤3.4、或者将选定的标记覆盖掉修剪后的样本中标记边界之间的内容;
24、步骤3.5、重复执行上述步骤3.1-步骤3.4,直到达到预设的变异次数或变异停滞。
25、进一步地,在步骤3.1中,确定修剪后的样本中的标记边界的步骤包括:
26、从修剪后的样本的开头开始,依次遍历每个字节,直到末尾;
27、对于当前的字节i,检查它是否是字母表或数字;
28、如果字节i是字母表或数字,则继续检查下一个字节i+1是否也是字母表或数字;如果字节i+1也是字母表或数字,则说明当前字节i属于标记的一部分;
29、如果字节i+1不是字母表或数字,则说明当前字节i是标记的结尾,并且下一个字节是标记的开头。
30、进一步地,在步骤3中,所述基于语法感知的变异策略包括基于树的变异操作,所述基于树的变异操作包括:
31、将要变异的样本、语法和从触发新覆盖的输入样本的队列中随机选择的样本作为输入;
32、根据语法将要变异的样本解析为第一抽象语法树,如果出现解析错误,则不进行基于树的变异;
33、遍历第一抽象语法树,并将每个子树存储在集合s中;
34、将从队列中随机选择的样本解析为第二抽象语法树,如果没有解析错误,则将第二抽象语法树的每个子树存储在集合s中;
35、对于第一抽象语法树中的每个子树n,用集合s中的每个子树s替换每个子树n,从而生成一个新的变异样本;
36、返回一组变异的样本。
37、进一步地,在步骤3中,所述基于语法感知的变异策略包括基于树的变异操作,所述基于树的变异操作包括:
38、将要变异的样本、语法和从触发新覆盖的输入样本的队列中随机选择的样本作为输入;
39、将要变异的样本和从队列中随机选择的样本的长度限制为设定字节长;如果要变异的样本的长度超过所述设定的字节长,则不进行基于树的变异;如果从队列中随机选择的样本的长度超过所述设定的字节长,则仅对要变异的样本和从队列中随机选择的样本中长度小于所述设定的字节长的部分进行基于树的变异;
40、根据语法将要变异的样本解析为第一抽象语法树,如果出现解析错误,则不进行基于树的变异;
41、遍历第一抽象语法树,并将每个子树存储在集合s中;
42、将从队列中随机选择的样本解析为第二抽象语法树,如果没有解析错误,则将第二抽象语法树的每个子树存储在集合s中;
43、对于第一抽象语法树中的每个子树n,用集合s中的每个子树s替换每个子树n,从而生成一个新的变异样本;
44、返回一组变异的样本。
45、进一步地,在步骤3中,所述基于语法感知的变异策略包括基于树的变异操作,所述基于树的变异操作包括:
46、将要变异的样本、语法和从触发新覆盖的输入样本的队列中随机选择的样本作为输入;
47、根据语法将要变异的样本解析为第一抽象语法树,如果出现解析错误,则不进行基于树的变异;
48、将要变异的样本和从队列中随机选择的样本的长度限制为设定字节数;如果第一抽象语法树中的子树数量超过设定的字节数,则将其随机缩减至设定字节数,并用所述设定字节数的子树进行基于树的变异;
49、遍历第一抽象语法树,并将每个子树存储在集合s中;
50、将从队列中随机选择的样本解析为第二抽象语法树,如果没有解析错误,则将第二抽象语法树的每个子树存储在集合s中;
51、如果集合s中的子树总数超过设定字节数,则从中随机选择该设定字节数作为变异的内容提供者;
52、对于第一抽象语法树中的每个子树n,用集合s中的每个子树s替换每个子树n,从而生成一个新的变异样本;
53、返回一组变异的样本。
54、进一步地,在步骤3中,所述基于语法感知的变异策略包括基于树的变异操作,所述基于树的变异操作包括:
55、将要变异的样本、语法和从触发新覆盖的输入样本的队列中随机选择的样本作为输入;
56、根据语法将要变异的样本解析为第一抽象语法树,如果出现解析错误,则不进行基于树的变异;
57、将要变异的样本和从队列中随机选择的样本的长度限制为设定字节长,遍历第一抽象语法树,并将每个大小小于等于设定字节长的子树存储在集合s中;
58、如果集合s中没有子树,则直接返回空列表,否则继续执行以下步骤;
59、将从队列中随机选择的样本解析为第二抽象语法树,如果没有解析错误,则将第二抽象语法树的每个大小小于等于设定字节长的子树存储在集合s中;
60、如果集合s中的任何子树的大小超过设定字节长,则将其移除;
61、对于第一抽象语法树中的每个子树n,用集合s中的每个子树s替换每个子树n,从而生成一个新的变异样本;
62、返回一组变异的样本。
63、本发明主要针对以上问题,提出了一种基于语法感知的灰盒模糊测试装置,包括:
64、获取单元,用于从存储初始输入样本以及触发新覆盖的输入样本的队列中选择一个输入样本;
65、修剪单元,用于将从所述队列中选择的输入样本基于语法感知的修剪策略对该队列中选择的输入样本进行修剪;
66、变异单元,用于对修剪后的样本进行基于语法感知的变异策略对该修剪后的样本进行变异操作,生成新输入样本;
67、运行单元,用于将变异后的新输入样本投入到程序中执行;
68、更新单元,用于在触发新的覆盖时,将其添加到队列中以更新队列,否则,丢弃该变异样本。
69、(三)有益效果
70、与现有技术相比,本发明提供的一种基于语法感知的灰盒模糊测试方法及装置,通过基于语法感知的修剪策略,将输入样本精细地修剪到最小大小,可以保留输入样本的语法结构,避免违反语法或样本结构而使其无效。同时,基于语法感知的变异策略可以根据输入样本的语法结构生成更符合预期的变异样本,从而提高变异后的新输入样本的有效性和准确性。
- 还没有人留言评论。精彩留言会获得点赞!