网络安全威胁知识抽取模型的训练方法和装置与流程
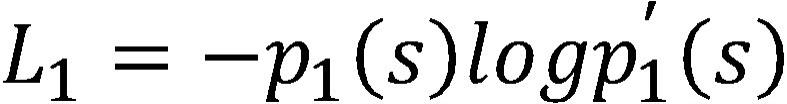
本公开总体说来涉及网络安全威胁领域,更具体地讲,涉及一种网络安全威胁知识抽取模型的训练方法和装置。
背景技术:
1、随着网络技术和通信技术的快速发展,网络安全问题快速演进,网络攻击事件层出不穷,对个人、组织乃至政府造成了极大的危害与损失。日益复杂化、多样化、组织化的网络攻击,使得计算机网络面临着严峻的信息安全形势。传统的网络安全威胁情报分析技术无法全面、及时、准确地检测攻击技术及其内在关联,难以满足日趋复杂的网络安全防范需求。
2、近年来,国内外研究人员针对网络安全威胁情报的信息共享与建模分析等问题,展开了相关标准与规范的建立等工作。目前比较主流且得到广泛支持和应用的是由mitre和oasis(organization for the advancement of structured information standards,结构化信息标准促进组织)网络威胁情报(cyber threat intelligence,cti)技术委员会发布的结构化威胁信息表达式(structured threat information expression,stix)、指标信息的可信自动化交换(trusted automated exchange of indicator information,taxii)、以及网络可观察表达式(cyber observable expression,cybox),通过以上标准从多角度对网络威胁要素进行统一描述,建立网络威胁要素之间的各种关联关系。
3、尽管学术界和工业界当前已经在网络威胁情报理论和实践方面开展了大量工作,但网络安全威胁情报因异源共享集成,具有异构性、海量性、分散性、实时性等特点,导致对威胁情报的获取、分析、利用能力不足,难以充分发挥网络安全威胁情报的价值,威胁情报数据亟待深入挖掘。因此,如何从海量的原始数据中,有效提取有用的网络安全威胁信息,并针对不同网络攻击场景产生关联分析,仍需要进一步研究。
技术实现思路
1、本公开基于构建的网络安全威胁领域本体模型,提供一种网络安全威胁知识抽取模型的训练方法和装置,在对网络安全威胁知识进行统一规范描述的基础上,提高了网络安全威胁知识抽取模型的知识挖掘效率,从而能够更有效地从海量数据中提取网络安全威胁信息。
2、在一个总的方面,提供一种网络安全威胁知识抽取模型的训练方法,所述训练方法包括:通过网络安全威胁领域本体模型对预定数量的文本中的三元组进行标注,得到多个标注文本,其中,从预先获取的网络安全威胁领域的文本数据集确定网络安全威胁领域术语,并且基于确定的网络安全威胁领域术语,构建所述网络安全威胁领域本体模型;将每个标注文本作为训练样本输入网络安全威胁知识抽取模型,并利用所述网络安全威胁知识抽取模型预测所述训练样本中的三元组;基于预测结果计算损失函数的值,并根据所述损失函数的值调整所述网络安全威胁知识抽取模型的参数,从而对所述网络安全威胁知识抽取模型进行训练。
3、可选地,所述文本数据集为非结构化数据,其中,所述从预先获取的网络安全威胁领域的文本数据集确定网络安全威胁领域术语包括:对所述文本数据集进行预处理,以去除所述文本数据集中不具有实际语义的字符;对预处理后的文本数据集进行分词处理,得到多个分词;对所述多个分词进行词频统计,并根据所述词频统计的结果,从所述多个分词中确定网络安全威胁领域术语。
4、可选地,所述对所述多个分词进行词频统计,并根据所述词频统计的结果,从所述多个分词中确定网络安全威胁领域术语包括:对所述多个分词进行词频统计,得到每个分词的词频;按照所述词频,对所述多个分词进行降序排序,得到排序后的分词;将所述排序后的分词中排序靠前的预设比例的分词确定为网络安全威胁术语。
5、可选地,所述基于确定的网络安全威胁领域术语,构建所述网络安全威胁领域本体模型包括:基于确定的网络安全威胁领域术语,确定网络安全威胁领域的类和类层次结构,其中,所述类层次结构表示类与子类的分层结构;基于确定的类和类层次结构,确定类的数据属性和类与类之间的关系;基于确定的类、类层次结构、类的数据属性和类与类之间的关系,得到网络安全威胁领域本体模型。
6、可选地,所述基于确定的网络安全威胁领域术语,构建所述网络安全威胁领域本体模型还包括:确定得到的网络安全威胁领域本体模型是否符合预设要求;在所述得到的网络安全威胁领域本体模型不符合预设要求的情况下,重新获取文本数据集,并基于重新获取的文本数据集构建网络安全威胁领域本体模型,直至重新构建的网络安全威胁领域本体模型符合预设要求。
7、可选地,所述网络安全威胁知识抽取模型包括编码器、第一分类器和第二分类器,所述三元组包括主体、客体和关系,其中,所述利用所述网络安全威胁知识抽取模型预测所述训练样本中的三元组的步骤包括:利用所述编码器,将所述训练样本转换为编码序列,其中,所述编码序列包括多个编码向量;利用所述第一分类器,基于所述编码序列预测所述训练样本中的主体;确定预测的所述训练样本中的主体的首字和尾字所对应的编码向量,并且根据所述首字和尾字所对应的编码向量,对所述编码序列进行归一化处理;利用所述第二分类器,基于归一化处理后的编码序列预测所述训练样本中的主体所对应的客体和关系。
8、可选地,所述将所述训练样本转换为编码序列的步骤包括:根据预设字典,将所述训练样本中的文字转换为对应的数字,得到数字序列,其中,所述预设字典中的每个文字各自对应一个数字;将所述数字序列中的每个数字分别转换为编码向量,得到所述编码序列。
9、可选地,所述损失函数包括所述第一分类器对应的第一损失函数和所述第二分类器对应的第二损失函数,所述基于预测结果计算损失函数的值的步骤包括:基于所述第一分类器针对所述训练样本中的主体的预测结果,计算所述第一损失函数的值;基于所述第二分类器针对所述训练样本中的主体所对应的客体和关系的预测结果,计算所述第二损失函数的值;将所述第一损失函数的值和所述第二损失函数的值进行相加,得到所述损失函数的值。
10、可选地,所述第一损失函数表示如下:
11、
12、其中,表示所述第一损失函数, s表示预测的主体,表示预测的主体对应的标注值,表示预测的主体对应的预测概率值;
13、所述第二损失函数表示如下:
14、
15、其中,表示所述第二损失函数, r表示标注出的关系的总类别数, r表示关系的当前类别, o表示预测的客体,表示预测的客体在当前类别的关系下对应的标注值,表示预测的客体在当前类别的关系下对应的预测概率值;
16、所述损失函数表示如下:
17、
18、其中,表示所述损失函数,表示所述第一损失函数的权重,表示所述第二损失函数的权重。
19、在另一总的方面,提供一种网络安全威胁知识抽取方法,所述方法包括:获取网络安全威胁领域的待抽取文本;将所述待抽取文本作为输入,利用如上所述的网络安全威胁知识抽取模型的训练方法得到的网络安全威胁知识抽取模型抽取所述待抽取文本中的三元组,将抽取的三元组作为所述待抽取文本中的网络安全威胁知识。
20、在另一总的方面,提供一种网络安全威胁知识抽取模型的训练装置,所述训练装置包括:标注单元,被配置为通过网络安全威胁领域本体模型对预定数量的文本中的三元组进行标注,得到多个标注文本,其中,从预先获取的网络安全威胁领域的文本数据集确定网络安全威胁领域术语,并且基于确定的网络安全威胁领域术语,构建所述网络安全威胁领域本体模型;预测单元,被配置为将每个标注文本作为训练样本输入网络安全威胁知识抽取模型,并利用所述网络安全威胁知识抽取模型预测所述训练样本中的三元组;调参单元,被配置为基于预测结果计算损失函数的值,并根据所述损失函数的值调整所述网络安全威胁知识抽取模型的参数,从而对所述网络安全威胁知识抽取模型进行训练。
21、可选地,所述文本数据集为非结构化数据,其中,所述从预先获取的网络安全威胁领域的文本数据集确定网络安全威胁领域术语包括:对所述文本数据集进行预处理,以去除所述文本数据集中不具有实际语义的字符;对预处理后的文本数据集进行分词处理,得到多个分词;对所述多个分词进行词频统计,并根据所述词频统计的结果,从所述多个分词中确定网络安全威胁领域术语。
22、可选地,所述对所述多个分词进行词频统计,并根据所述词频统计的结果,从所述多个分词中确定网络安全威胁领域术语包括:对所述多个分词进行词频统计,得到每个分词的词频;按照所述词频,对所述多个分词进行降序排序,得到排序后的分词;将所述排序后的分词中排序靠前的预设比例的分词确定为网络安全威胁术语。
23、可选地,所述基于确定的网络安全威胁领域术语,构建所述网络安全威胁领域本体模型包括:基于确定的网络安全威胁领域术语,确定网络安全威胁领域的类和类层次结构,其中,所述类层次结构表示类与子类的分层结构;基于确定的类和类层次结构,确定类的数据属性和类与类之间的关系;基于确定的类、类层次结构、类的数据属性和类与类之间的关系,得到网络安全威胁领域本体模型。
24、可选地,所述基于确定的网络安全威胁领域术语,构建所述网络安全威胁领域本体模型还包括:确定得到的网络安全威胁领域本体模型是否符合预设要求;在所述得到的网络安全威胁领域本体模型不符合预设要求的情况下,重新获取文本数据集,并基于重新获取的文本数据集构建网络安全威胁领域本体模型,直至重新构建的网络安全威胁领域本体模型符合预设要求。
25、可选地,所述网络安全威胁知识抽取模型包括编码器、第一分类器和第二分类器,所述三元组包括主体、客体和关系,其中,所述预测单元被配置为:利用所述编码器,将所述训练样本转换为编码序列,其中,所述编码序列包括多个编码向量;利用所述第一分类器,基于所述编码序列预测所述训练样本中的主体;确定预测的所述训练样本中的主体的首字和尾字所对应的编码向量,并且根据所述首字和尾字所对应的编码向量,对所述编码序列进行归一化处理;利用所述第二分类器,基于归一化处理后的编码序列预测所述训练样本中的主体所对应的客体和关系。
26、可选地,所述预测单元还被配置为:根据预设字典,将所述训练样本中的文字转换为对应的数字,得到数字序列,其中,所述预设字典中的每个文字各自对应一个数字;将所述数字序列中的每个数字分别转换为编码向量,得到所述编码序列。
27、可选地,所述损失函数包括所述第一分类器对应的第一损失函数和所述第二分类器对应的第二损失函数,所述调参单元被配置为:基于所述第一分类器针对所述训练样本中的主体的预测结果,计算所述第一损失函数的值;基于所述第二分类器针对所述训练样本中的主体所对应的客体和关系的预测结果,计算所述第二损失函数的值;将所述第一损失函数的值和所述第二损失函数的值进行相加,得到所述损失函数的值。
28、可选地,所述第一损失函数表示如下:
29、
30、其中,表示所述第一损失函数, s表示预测的主体,表示预测的主体对应的标注值,表示预测的主体对应的预测概率值;
31、所述第二损失函数表示如下:
32、
33、其中,表示所述第二损失函数, r表示标注出的关系的总类别数, r表示关系的当前类别, o表示预测的客体,表示预测的客体在当前类别的关系下对应的标注值,表示预测的客体在当前类别的关系下对应的预测概率值;
34、所述损失函数表示如下:
35、
36、其中,表示所述损失函数,表示所述第一损失函数的权重,表示所述第二损失函数的权重。
37、在另一总的方面,提供一种网络安全威胁知识抽取装置,所述装置包括:文本获取单元,被配置为获取网络安全威胁领域的待抽取文本;知识抽取单元,被配置为将所述待抽取文本作为输入,利用如上所述的训练方法得到的网络安全威胁知识抽取模型抽取所述待抽取文本中的三元组,将抽取的三元组作为所述待抽取文本中的网络安全威胁知识。
38、在另一总的方面,提供一种存储有计算机程序的计算机可读存储介质,其特征在于,当所述计算机程序被处理器执行时,实现如上所述的网络安全威胁知识抽取模型的训练方法或者网络安全威胁知识抽取方法。
39、在另一总的方面,提供一种计算装置,所述计算装置包括:处理器;和存储器,存储有计算机程序,当所述计算机程序被处理器执行时,实现如上所述的网络安全威胁知识抽取模型的训练方法或者网络安全威胁知识抽取方法。
40、根据本公开的实施例的网络安全威胁知识抽取模型的训练方法和装置能够通过构建的网络安全威胁领域本体模型实现网络安全威胁知识的统一规范描述,从而能够对文本中的网络安全威胁领域的三元组知识进行规范性标注,并利用标注后的文本来训练网络安全威胁知识抽取模型,使训练好的网络安全威胁知识抽取模型具有更高的知识挖掘效率,从而能够更有效地从海量数据中提取网络安全威胁信息。
41、将在接下来的描述中部分阐述本公开总体构思另外的方面和/或优点,还有一部分通过描述将是清楚的,或者可以经过本公开总体构思的实施而得知。
- 还没有人留言评论。精彩留言会获得点赞!