一种基于多模态数据的课堂认知投入识别方法和系统
本发明属于图像识别、图像分类、文本分类、文本识别,具体涉及一种基于多模态数据的课堂认知投入识别方法,以期通过融合多模态数据中隐含的内隐与心理信息推断课堂认知投入,为自然状态下的学生学习和教师课堂干预等教育应用提供技术支撑,助力教育向精准化、个性化和智能化方向发展。
背景技术:
1、人工智能、大数据等新兴信息技术与教育教学的深度融合,助推了智慧教育的蓬勃发展,课堂是教育教学的主阵地,既能支持开展多样化教学活动,又可包容差异较大的学生个体,是学生获取知识和掌握技能的重要场所。学生在课堂中常出现心不在焉、缺乏专注、投入不均等投入不足的现象,但是教师无法实时关注到每位学生的投入状态并实施干预,该问题对于新手教师来说更为突出。因此,监测学生的学习投入,为课堂情境中教师精准施策提供依据至关重要。认知投入是学习投入的基础性维度,因其内隐性极强而难以被直接建模和测量,现有研究多采用自我报告等传统方式对其评测,但这并不能契合认知投入的动态发展特性和体现出认知状态的全息内隐机制。在课堂教学过程中,创新课堂认知投入的评测方式,构建科学的评测框架来指导非侵入式采集多模态学习数据和全面评测学生认知投入状态是突破现阶段课堂认知投入评测研究内容片面浅层、评测方法侵扰性强等问题的关键。
2、目前,常见的认知投入测量方法包括人工观察、视频录像、自我报告、访谈、教师打分、经验抽样、生理测量、文本编码等。由于课堂观察和访谈法均存在费时耗力的缺陷,现有研究通常将其作为辅助方法来评测认知状态。考虑到认知投入的心理特质,研究者通常采用自我报告法对其进行评测,常见的量表有jes量表、sccei量表等。这类方法对情境的要求相对较低,能广泛适用于不同的课堂情境,也常与经验抽样、教师打分等其他方法协同使用。生理测量的方法常见于实验室情境,但其侵入性强、设备成本高等局限难以满足课堂情境下的认知投入评测需求。视频录像为面向课堂情境的认知投入数据采集提供了便利,基于视觉线索的表征方法广受欢迎,该方法常采用教室角落里的摄像机来直接录制学生的脸部、上半身画面以及课堂声音。这类方法与在线情境中采集的数据不同,它的外显形式比文本、点击流、时间戳等信息更丰富,能捕捉到学生的认知时序变化特征,也对包含个体、师生、生生等复杂交互编码提出了更高的要求,需要从更广泛的洞察角度捕捉更多认知信息。
3、综上所述,课堂认知投入自动感知是智慧教育发展的重要方向。虽然,目前已有相关研究利用表情、体态等视觉线索初步探索了课堂认知投入感知,但是在认知投入的多维细粒度表征、内隐动态投入特征提取,以及多粒度投入识别等方面还存在困难。
4、因此,本发明立足于研究内容,设计一种基于多模态数据的课堂认知投入识别方法实现课堂认知投入的自动感知,为精准识别与感知在课堂认知投入提供技术支撑。
技术实现思路
1、本发明针对当前课堂认知投入的多维细粒度表征、内隐动态投入特征提取以及多粒度投入识别等问题,从多模态数据入手,设计基于多模态数据的课堂认知投入智能识别方法评估学习者的认知投入状态。本发明提供了一种基于多模态数据的课堂认知投入识别方法,为非接触、非侵扰式课堂认知投入自动感知提供支撑。
2、本发明提供了一种基于多模态数据的课堂认知投入识别方法,包括如下步骤:
3、步骤1,从多模态数据角度出发,构建基于多模态数据的课堂认知投入感知数据库;
4、步骤2,提取自然课堂中的多模态数据,进行课堂认知投入感知的多模态数据分析,基于多模态数据构建多维度的课堂认知投入表征概要模型;
5、步骤3,基于学习者的多模态数据和课堂认知投入的多维度表征,采用深度学习的方法进行基于多模态数据的多维认知投入识别,最后输出不同模态数据的认知投入识别结果;
6、步骤4,融合步骤3得到的每个模态的认知投入结果,然后自适应地调整不同模态数据识别结果的权重,根据学习者的认知投入问卷反馈进行课堂认知投入权重参数训练,感知学习者的整体课堂认知投入水平。
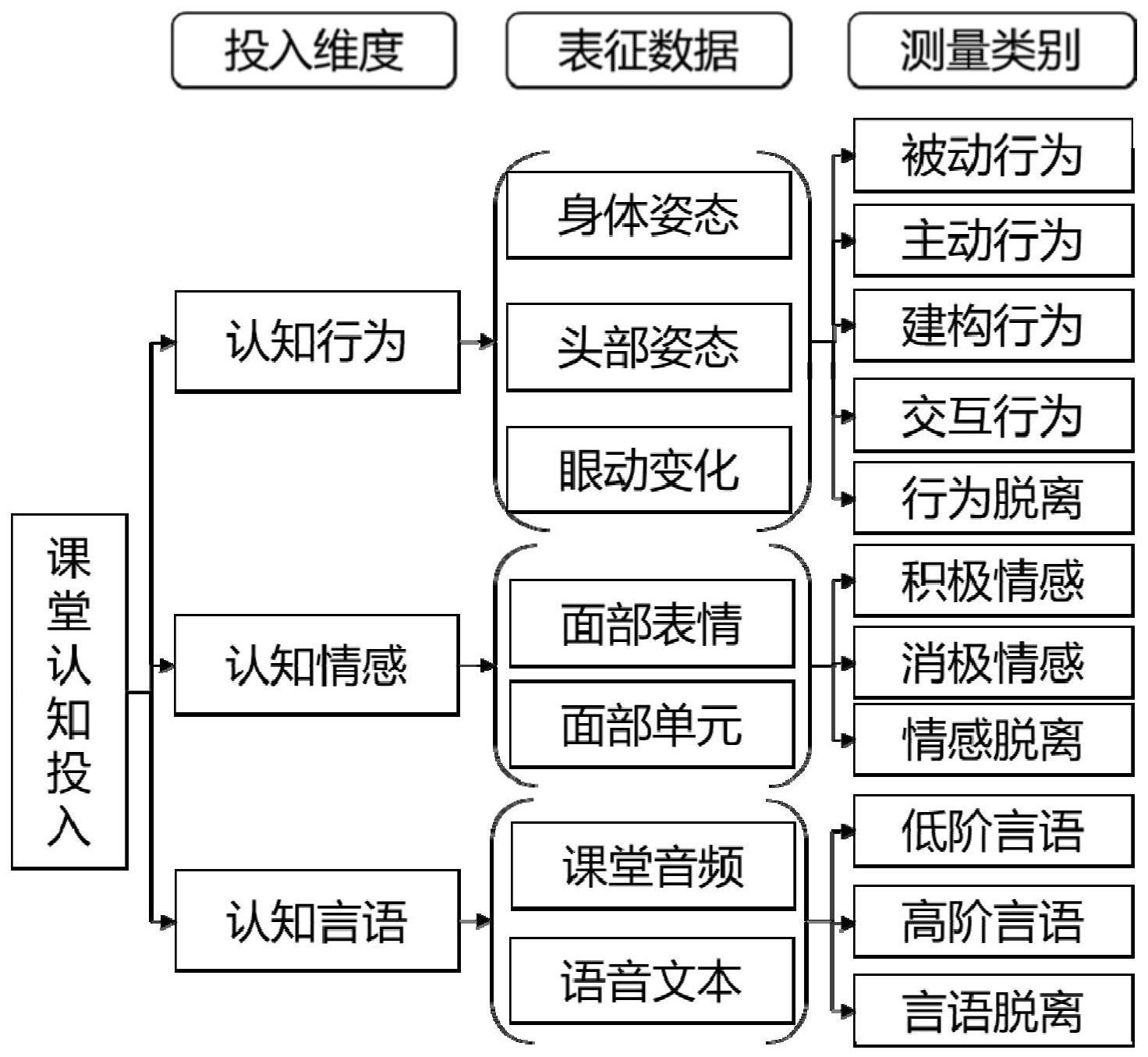
7、进一步的,多模态数据包括身体姿态、头部姿态、眼动变化、面部表情、面部单元、课堂音频和语音文本。
8、进一步的,步骤2中以多模态数据为基础,挖掘各模态数据的特征,从而将多模态数据与多维度课堂认知投入表征关联起来,进而确定课堂认知投入在某一模态下的表现情况;
9、进一步的,针对身体姿态、头部姿态、眼动变化模态数据及步骤3中的认知行为维度的表征,采用yolov8模型,挖掘学习者身体姿态、头部姿态、眼动变化中的变化特征,确定学习者的身体姿态等所映射出的认知行为信息。
10、(1)数据预处理
11、将输入身体姿态、头部姿态、眼动变化模态图像尺寸对齐为640*640、设置rgb图像、通道设置为chw排列格式等。
12、(2)backbone层
13、对身体姿态、头部姿态、眼动变化模态数据进行特征提取,首先,连续使用两个3×3卷积降低4倍分辨率,形成的特征图通道数分别为64、128。然后,采用c2f模块,通过分支夸层链接,丰富模型的梯度流。
14、(3)neck层和head层
15、将backbone层不同阶段输出的特征直接送入了上采样操作,采用解耦头和anchor-free的机制进行特征图组合,并对标注框进行卷积计算。
16、(4)目标检测损失计算
17、针对身体姿态、头部姿态、眼动变化模态数据的目标检测任务,损失计算过程包括正负样本分配策略和loss计算。考虑到动态分配策略的优异性,采用任务对其策略,根据分类与回归的分数加权选择正样本t,计算如下:
18、t=sα×uβ (1)
19、sα是标注类别对应的带α参数的预测值,uβ的计算方式如下:
20、
21、其中y表示所有学生的行为信息实际标注框,表示所有学生的行为信息预测框。loss计算包括分类损失和回归损失,分类损失采用bce loss计算方式,回归损失采用distribution focal loss计算方式和ciou loss计算方式,最后将上述三种损失计算采用一定权重比例加权得到最后的损失函数。
22、1)分类损失cls值计算如下:
23、
24、其中,m表示该课堂中的学生人数,yi是第i个学生的行为信息实际框,是第i个学生的行为信息预测框。
25、2)回归损失dfl值和cil值计算如下:
26、dfl(si,si+1)=-((yi+1-y)log(si)+(y-yi)log(si+1)) (4)
27、cil=1-(uβ-(loss(length)+loss(width))) (5)
28、其中,si表示对第i个学生的肢体动作特征进行softmax激活函数计算,将新的肢体动作特征值转换为范围在[0,1]和为1的概率分布。loss(length)表示所有学生的行为信息预测框与实际框y在长度length上的损失值,loss(width)表示所有学生的行为信息预测框与实际框y在宽度width上的损失值。
29、3)定义最终损失值为l,三类损失cls、dfl、cil值的融合方式如下:
30、l=λ1·cls+λ2·dfl+λ3·cil (6)
31、其中,λ1、λ2和λ3分别为融合权重参数,其取值范围为[0,1]。
32、进一步的,针对面部表情和面部单元模态数据,采用efficientnet模型,挖掘面部表情和面部单元中的变化特征,确定学习者的面部所映射出的认知情感信息。共分为9个计算阶段,如下所示;
33、(1)第1阶段:通过卷积核大小为3×3,步长为2的普通卷积计算,得到学习者面部表情浅层特征值。
34、(2)第2至第8阶段:通过重复堆叠的mbconv结构来输出学习者面部表情深层特征信息。其中,mbconv结构主要是通过1个1×1的普通卷积来提升面部表情模态数据的维度,卷积核个数是输入特征矩阵通道的p倍,p∈{1,6},再通过1个q×q的depthwise conv卷积(其中q=3或5)和1个se模块继续提取面部关键特征,然后采用1个1×1的普通卷积将具备面部关键特征的数据集合进行降维,最后通过一个droupout层防止过拟合,生成新的深层特征信息的表情特征图。
35、(3)第9阶段:通过1个普通卷积层、1个最大池化层、1个全连接层组成,最后输出学习者面部表情所映射出的认知情感信息。
36、进一步的,针对课堂音频和语音文本模态数据,采用textcnn模型,挖掘学习者课堂音频和语音文本的变化特征,确定学习者的话语所映射出的认知言语信息。
37、(1)第一层为输入层。输入层是一个n×k的矩阵input,其中n为一个句子中的单词数,k是每个词对应的词向量维度。也就是说,输入层的每一行是一个单词所对应的k维词向量。
38、(2)第二层为卷积层。在输入矩阵input上,设置卷积核为卷积层的输出结果为c,计算公式如下:
39、
40、其中,表示卷积操作,c=[c1,c2,…,cn-h+1]表示卷积层所提取的新的词特征向量,c1,c2,…,cn-h+1表示学生发言的第1个句子s1、第2个句子s2……直到本节课堂中最后一个发言句子的特征向量,每一个句子的特征向量ci计算方式如下:
41、ci=f(w·xi:i+h-1+b) (8)
42、其中,xi:i+h-1表示输入矩阵input的第i行到第i+h-1行所组成的一个大小为h×k的窗口,由xi、xi+1、……、xi+h-1拼接而成,b为偏置参数,f为非线性激活函数。
43、(3)第三层是池化层。可以选择最大池化、k-max池化、或者平均池化操作,进一步筛选卷积层输出的新的文本特征向量。最大池化是从每个滑动窗口产生的特征向量中筛选出一个最大的特征,然后将这些特征拼接起来构成向量表示。k-max池化是选出每个特征向量中最大的k个特征,平均池化是将特征向量中的每一维取平均,达到的效果都是将不同长度的句子通过池化得到一个定长的向量表示。
44、(4)第四层为全连接层和文本分类输出。textcnn模型目标是对学习者言语数据进行分类,因此拼接全连接层,使用softmax激活函数输出每一类言语数据的概率大小。
45、进一步的,从学习者的认知行为、认知情感和认知言语三个维度构建课堂认知投入表征概要模型。具体构建步骤如下;
46、(1)课堂认知投入中的认知行为维度通过身体姿态、头部姿态、眼动变化模态数据进行综合表征,针对时刻f的课堂视频帧,对该时刻对应的图像进行向量化,将图像中的每一个像素点用[0,9]的数字表示,作为身体姿态、头部姿态、眼动变化模态数据的表征结果a。
47、(2)课堂认知投入中的认知情感维度通过面部表情和面部单元模态数据进行表征,针对时刻f的课堂视频帧,首先通过opencv库进行人脸自动提取,将提取出来的人脸图像作为该时刻下认知情感表征依据,然后将彩色图像中的每一个像素点用[0,9]的数字表示,形成最终的表征结果b。
48、(3)课堂认知投入中的认知言语维度通过课堂音频和语音文本模态数据进行量化表征,通过预训练好的词向量和含参数的词向量两种表示方法共同表征认知言语维度,表征结果为c。
49、进一步的,步骤1中构建基于多模态数据的课堂认知投入感知数据库,具体实现方式如下;
50、(1)在课堂环境下,教师开展自然状态下的课堂教学,其中涵盖课堂学习者若干名,他们均在教师的指导下参与课堂活动和知识建构,并允许教师融合先进的技术工具和不同教学模式开展丰富的课堂活动,以满足不同学习阶段的需求;
51、(2)采用非侵入、无感知的方式捕捉学习者的认知状态。在教室前方和后方安装高清摄像头若干个,课前将其打开用于实时录制学生的课堂学习情况,课后将其关闭并从终端系统中导出课堂视频数据,作为课堂认知投入感知数据源。
52、(3)在数据标注过程中,通过课后问卷的方式获取学习者的真实认知投入感受,采用李克特五点计分法作为学习者整体投入状态的标注标准,通过视频图像数据作为学习者认知行为的标注来源,将视频图像数据进行自动人脸提取,通过面部图像数据标注学习者的认知情感,通过课堂音频数据作为学习者的认知言语标注来源。
53、(4)针对每一个数据标注标签,先选取一部分课堂视频数据,采用多名编码员同时标注,不一致的地方进行协商后再开展大规模课堂认知投入数据标注。
54、(5)为了获取不同粒度下的学习者认知投入状态,可以根据需要提取课堂视频帧,若课堂视频帧率为25fps,则抽帧率可选择为每25帧/次、每50帧/次、……、每25*f帧/次等(f为整数),用于训练课堂认知投入表征概要模型。
55、进一步的,步骤4中通过如下方法实现认知行为、认知情感以及认知言语这三个维度下的认知投入识别;
56、(1)假设在时刻j感知得到的第i名学习者的三种投入向量分别为和其中为认知行为投入,为认知情感投入,表示认知言语投入,n1,n2,n3分别表示三种投入特征向量的维数;
57、(2)给定学习活动,假设在整个学习活动进行中共有f次实时投入识别,分别训练三种认知投入状态识别网络,通过深度学习模型计算、推理出认知行为投入结果认知情感投入结果和认知言语投入结果
58、(3)根据自动识别的三个认知投入结果,依据学习者反馈的联合感知认知投入整体水平,则感知学习者j在时刻i的整体认知投入水平engagementj,计算如下所示:
59、
60、其中,β1、β2和β3是待学习的网络参数。
61、本发明还提供一种基于多模态数据的课堂认知投入识别系统,包括如下模块:
62、数据库构建模块,用于从多模态数据角度出发,构建基于多模态数据的课堂认知投入感知数据库;
63、多维度表征模块,用于提取自然课堂中的多模态数据,进行课堂认知投入感知的多模态数据分析,基于多模态数据构建多维度的课堂认知投入表征概要模型,获得课堂认知投入的多维度表征;
64、多维度识别模块,用于基于学习者的多模态数据和课堂认知投入的多维度表征,采用深度学习的方法进行基于多模态数据的多维认知投入识别,最后输出不同模态数据的认知投入识别结果;
65、结果融合模块,用于融合多维度识别模块得到的每个模态的认知投入结果,然后自适应地调整不同模态数据识别结果的权重,根据学习者的认知投入问卷反馈进行课堂认知投入权重参数训练,感知学习者的整体课堂认知投入水平。
66、本发明与现有研究和技术相比,具有有益效果:
67、1.本发明结合教育学、心理学理论和深度学习方法,建立多模态数据驱动的多维细粒度课堂认知投入表征计算模型,从认知行为、认知情感和认知言语三方面来解析课堂认知投入的内在机制,满足课堂学习过程中认知投入的实时精准感知需求,为多粒度课堂认知投入感知奠定基础。
68、2.本发明将不同模态的认知投入识别问题分别通过三类深度学习模型自动识别的方法来解决,提出基于身体姿态等的yolov8模型、基于面部表情等的efficientnet模型、基于语音文本等的textcnn模型,提高识别模型对内隐动态投入特征的学习能力,方便实际课堂开展应用。
69、3.本发明构建融合多模态数据的细粒度课堂认知投入识别方法,并在此基础上融合学习者的自我报告反馈来设计基于真实感知数据的认知投入识别方法,自适应调整不同模态数据对最终课堂认知投入的贡献度,满足实际课堂应用中多层次、多阶段的认知投入感知需求。
- 还没有人留言评论。精彩留言会获得点赞!