医疗报告结构化识别模型训练方法、系统、设备及存储介质与流程
本发明涉及深度学习领域,具体涉及光学字符识别,提供医疗报告结构化识别模型训练方法、系统、设备及存储介质。
背景技术:
1、在医疗领域,对于纸质医疗报告的ocr(光学字符识别)信息提取是一个受到重点关注的问题。传统ocr技术通过图像预处理、版面划分(直线检测、倾斜检测)、字符定位切分、字符识别、版面恢复、后处理、校对等流程直接提取出图像中的文字,在理想环境下的印刷体识别上取得了比较准确的效果。然而,在面对复杂环境场景如光照、模糊、文字形状扭曲等情况时,传统方法往往识别精度不高。目前,随着深度学习算法特别是计算机视觉领域算法的发展,该问题得到了有效解决。相比传统ocr方法的手工提取特征,基于深度学习的ocr技术使用深度学习算法模型提取图像特征,从而自动检测出文本的内容和所处位置,在面对复杂场景和困难样本时具有更好的预测效果。
2、然而,对于医疗报告的信息提取来说,基于深度学习的常规ocr方法如crnn等方法并不足以满足用户的需求。在医疗报告的信息提取任务中,最终的目标是得到一个结构化的对象,该对象包括报告中的各种字段,比如姓名、年龄、检查项目等。常规的ocr模型只能得到图像中存在的文本内容以及该文本所在的位置,这些结果还需要经过一些后处理方法包括文本合并、模式匹配等方法才可以提取出对象的信息。由于不同医院的医疗报告格式存在的差异,后处理过程十分繁琐,对于每家医院的每种报告都需要不同匹配规则,对于新类型的报告也不具备泛化性。因此,有学者提出了layoutxlm模型,旨在解决这一问题。该模型结合图像、文本、布局多个模态对文档图像进行结构化识别,依靠强大的神经网络直接得到图像的结构化识别结果,省去了繁琐的后处理流程,实现了通用的文档结构化识别功能。
3、虽然layoutxlm模型实现了通用的文档结构化识别功能并且表现良好,但是在面对现实场景时,存在一定的缺陷。该模型只考虑了规范的文档图片的识别,即扫描生成的平整文档图片。但是在诸多现实任务场景中,需要预测的文档图片往往不太规范。在医疗报告识别的现实场景中,许多的医疗报告使用拍摄设备进行采集。而拍摄的报告图片存在几个问题。首先,拍摄的图片角度各异。通常拍摄出的文档图片做不到绝对的平整,会存在文字倾斜的情况,对文档的结构化识别造成影响。其次,拍摄的文档纸张本身会存在扭曲的情况,这一情况在医疗检查报告单上尤其普遍。这会使得ocr模型预测的文本检测框出现不同程度的偏移、不同角度的倾斜等情况。此外,与扫描图像不同,拍摄的图片可能会存在模糊、光照影响等图片质量问题,极大影响模型预测精度。模型在面对上述的情况时,泛化性较差,识别精度受到了较大影响。
技术实现思路
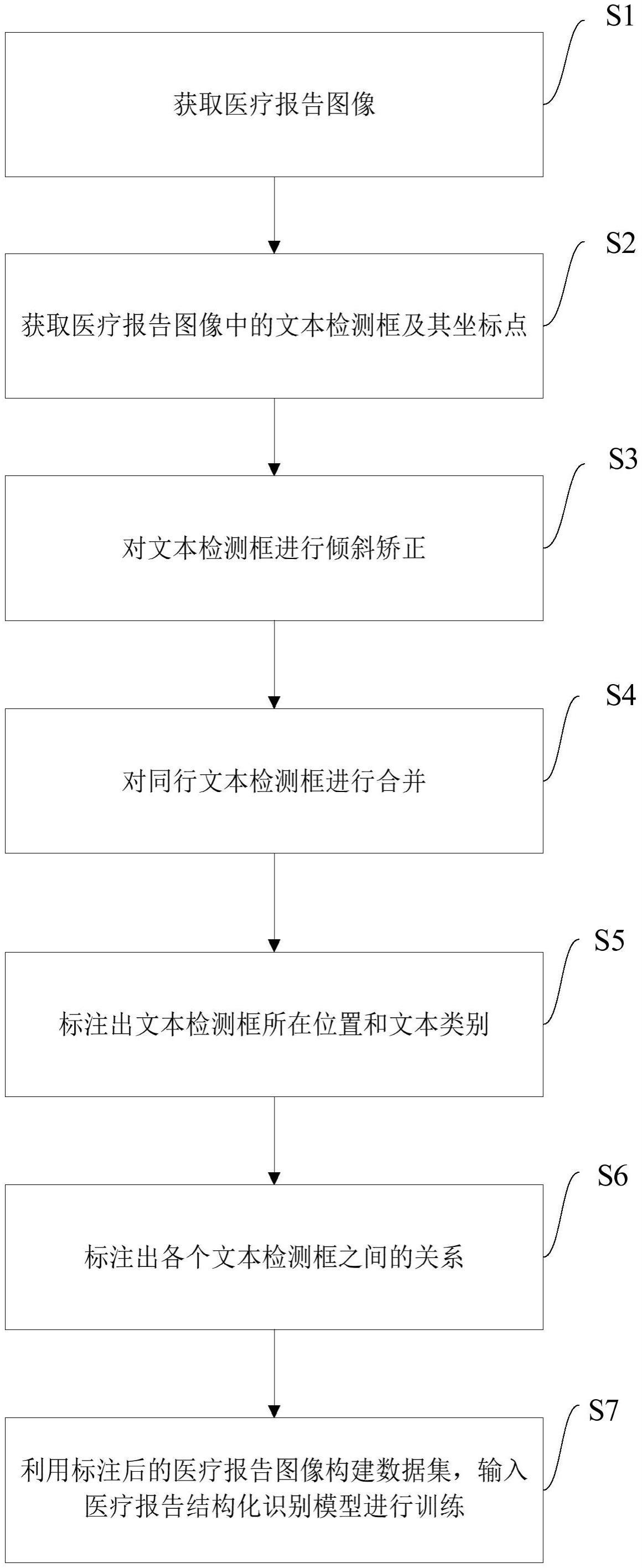
1、为了解决医疗报告光学字符识别技术领域样本处理困难、模型泛化性差的问题,本发明提供医疗报告结构化识别模型训练方法、系统、设备及存储介质,其中医疗报告结构化识别模型训练方法包括:
2、获取医疗报告图像;
3、获取医疗报告图像中的文本检测框及其坐标点;
4、对文本检测框进行倾斜矫正;
5、对同行文本检测框进行合并;
6、标注出文本检测框所在位置和文本类别;
7、标注出各个文本检测框之间的关系;
8、利用标注后的医疗报告图像构建数据集,输入医疗报告结构化识别模型进行训练;
9、所述医疗报告结构化识别模型接收图像、文本以及布局作为输入,基于transformer机制执行文本理解任务。
10、收集来自不同医院的各类医疗报告图片,包括门诊病历、入院记录、医疗影像检查报告、手术记录、检验报告、处方报告、出院报告。每类报告收集100张。报告中既有扫描图像,也有拍摄的图像,比例为1:1。
11、还可以对训练集进行数据增强操作,如小角度旋转、加高斯模糊等。
12、进一步,所述医疗报告结构化识别模型基于layoutxlm模型,使用空间自注意力机制。
13、医疗报告结构化识别模型基于layoutxlm模型,使用空间自注意力机制,接受来自三种不同模态的信息,包括文本、布局和图像,分别使用文本嵌入、布局嵌入和视觉嵌入层进行编码。输入嵌入由文本和图像嵌入拼接起来,再加上布局嵌入,输入具有自注意力机制的多模态transformer进行编码。最后,输出上下文表示可用于文本理解任务。
14、将所述ocr矫正结果加入到训练数据中,即增加一组矫正模态信息,此时layoutxlm模型的输入包含:图像、文本和布局以及矫正后的文本和布局。增加了矫正模态信息的训练数据分别使用文本嵌入、布局嵌入和视觉嵌入层进行编码。输入嵌入由文本和图像嵌入拼接起来,再加上布局嵌入,输入transformer进行编码,最后输出用于文本理解任务。
15、transformer是一个利用注意力机制来提高模型训练速度的模型,主要由encoder编码器和decoder解码器组成,encoder编码器对输入的文本数据的进行编码,随后将编码的数据输入decoder解码器进行解码。编码器和解码器又各自包括若干编码器和若干解码器,每个编码器结构是自注意力机制和前馈神经网络。
16、自注意力机制对每一个输入的向量,我们需要构建自注意力机制self-attention的输入。transformer将输入向量乘上若干矩阵,得到新的向量,这样可以增加更多的参数,提高模型效果。随后进行注意力得分的计算,将计算结果进行softmax运算,将分数标准化,随后将所述新的向量乘上softmax的结果,保持我们需要关注的值不变,过滤掉不相关的值,再根据权重将各个向量相加。
17、进一步,所述对文本检测框进行倾斜矫正包括:
18、设文本检测框的左上角、右上角、右下角以及左下角坐标点依次为a=[x0,y0],b=[x1,y1],c=[x2,y2],d=[x3,y3],计算向量ab与单位向量[1,0]的夹角θ;
19、计算所有文本检测框的夹角θ的平均值θavg;
20、根据x=xcos(θ)+y sin(θ),y=ycos(θ)–x sin(θ)纠正文本检测框坐标,纠正后的文本检测框坐标为[xi,yi]=[xicosθavg+yisinθavg,yicosθavg-xisinθavg]。
21、进一步,所述对同行文本检测框进行合并包括:
22、ai和di表示第i个文本检测框的左上角点和左下角点,计算所有文本检测框的ai和di的欧氏距离取最小值作为检测阈值;
23、[x0,y0]表示点a的坐标,[x1,y1]表示点的坐标,遍历比较x0,若x0i<x0j,且两框之间的高度差绝对值小于检测阈值,y1i-y0j<检测阈值,则在索引图中连接ai和aj对应的文本检测框;
24、遍历索引图,将连接的文本检测框汇聚成一行;
25、从左到右对每一行的索引进行排序;
26、从上到下对所有行的索引进行排序;
27、得到合并后的文本检测框以及相应的文本。
28、进一步,所述文本类别包括other和/或question和/或answer和/或name和/或result和/或unit和/或range和/或method。
29、上述文本类别表示医疗报告文本数据的具体类型,标注的文本例如”姓名”(question)->”张三”(answer),”报告时间”(question)->”2022-1-1”(answer),”血红蛋白测定”(name)->”146”(result),”血红蛋白测定”(name)->”g/l”(unit),”血红蛋白测定”(name)->”137-179”(range)等。还可以将标签数据的标注格式更改为匹配layoutxlm模型的json文件格式。
30、另一方面,基于同样的发明构思,本发明还提供一种医疗报告结构化识别模型训练系统,包括:
31、医疗报告获取模块,用于获取医疗报告图像;
32、预标注模块,用于获取医疗报告图像中的文本检测框及其坐标点;
33、倾斜矫正模块,用于对文本检测框进行倾斜矫正;
34、同行文本合并模块,用于对同行文本检测框进行合并;
35、标注模块,用于标注出文本检测框所在位置和文本类别以及标注出各个文本检测框之间的关系;
36、训练模块,用于利用标注后的医疗报告图像构建数据集,输入医疗报告结构化识别模型进行训练;
37、医疗报告结构化识别模型,接收图像、文本以及布局作为输入,基于transformer机制执行文本理解任务。
38、进一步,所述倾斜矫正模块具体包括:
39、设文本检测框的左上角、右上角、右下角以及左下角坐标点依次为a=[x0,y0],b=[x1,y1],c=[x2,y2],d=[x3,y3],计算向量ab与单位向量[1,0]的夹角θ;
40、计算所有文本检测框的夹角θ的平均值θavg;
41、根据x=xcos(θ)+y sin(θ),y=ycos(θ)–x sin(θ)纠正文本检测框坐标,纠正后的文本检测框坐标为[xi,yi]=[xicosθavg+yisinθavg,yicosθavg-xisinθavg]。
42、进一步,所述同行文本合并模块具体包括:
43、ai和di表示第i个文本检测框的左上角点和左下角点,计算所有文本检测框的ai和di的欧氏距离取最小值作为检测阈值;
44、[x0,y0]表示点a的坐标,[x1,y1]表示点的坐标,遍历比较x0,若x0i<x0j,且两框之间的高度差绝对值小于检测阈值,|y1i-y0j|<检测阈值,则在索引图中连接ai和aj对应的文本检测框;
45、遍历索引图,将连接的文本检测框汇聚成一行;
46、从左到右对每一行的索引进行排序;
47、从上到下对所有行的索引进行排序;
48、得到合并后的文本检测框以及相应的文本。
49、另一方面,基于同样的发明构思,本发明还提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现所述医疗报告结构化识别模型训练方法。
50、另一方面,基于同样的发明构思,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现所述医疗报告结构化识别模型训练方法。
51、本发明的有益效果为:
52、1.充分利用图像数据中的文本和布局信息,避免错误的ocr信息导致错误的编码信息,提高准确率。
53、2.增加纠错能力,增加了一组矫正模态信息,有效纠正错误布局和文本。
54、3.降低人工成本,缩减人工预处理和后处理,实现端到端的模型输入和输出。
- 还没有人留言评论。精彩留言会获得点赞!