一种基于MADDPG算法的混合式云资源弹性伸缩系统及运行方法
本发明属于云计算领域,具体的涉及一种基于maddpg算法的混合式云资源弹性伸缩系统及运行方法。
背景技术:
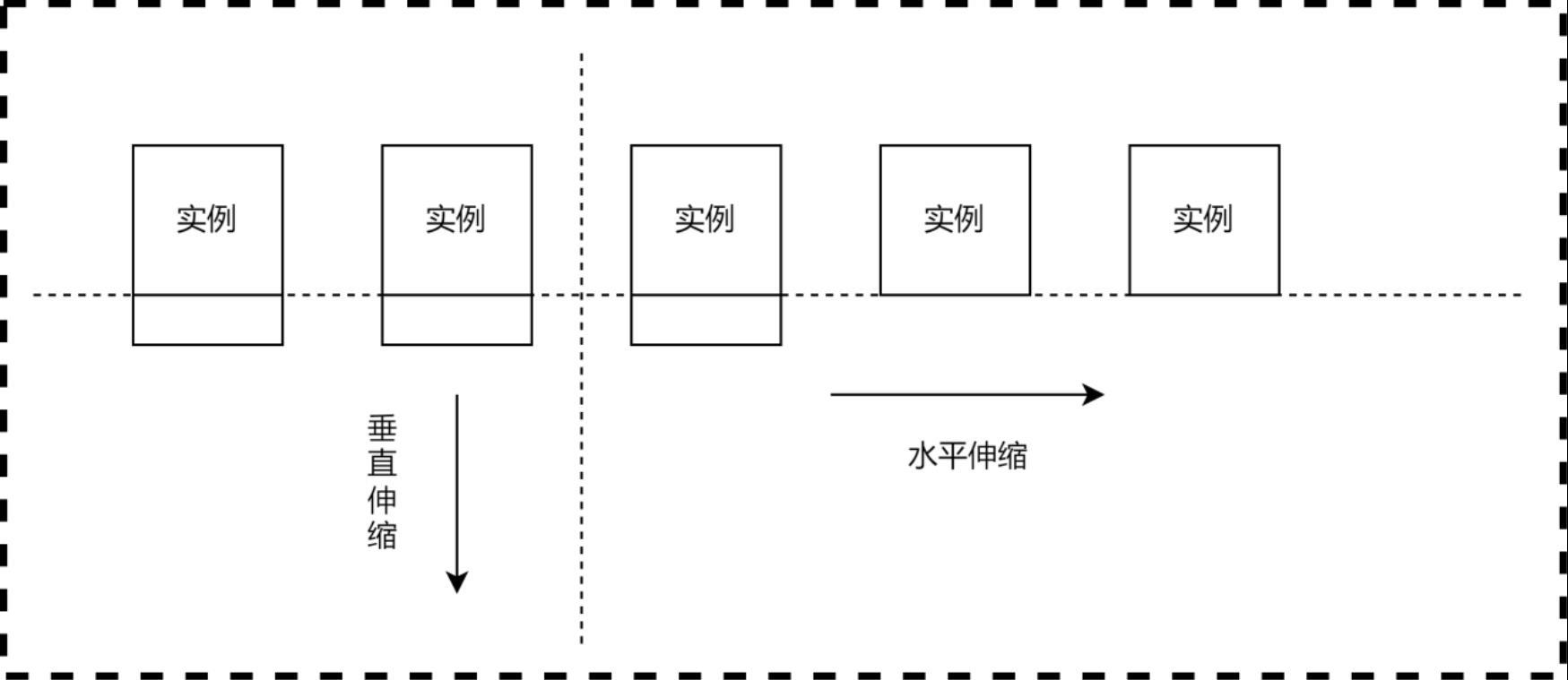
1、云资源弹性伸缩可以根据实时的负载情况自动增加或减少计算资源。当负载增加时,弹性伸缩可以自动扩展资源,以确保应用程序的性能和可用性不受影响。当负载减少时,它可以自动缩减资源,以减少资源浪费和成本。云资源弹性伸缩包括水平弹性伸缩和垂直弹性伸缩,如图1所示。
2、水平弹性伸缩是云计算中的一种资源管理策略,它允许根据应用程序的需求自动增加或减少计算资源的数量。这种弹性伸缩策略旨在应对负载的变化,确保应用程序始终具有足够的资源来满足用户需求。当负载增加时,水平弹性伸缩会自动增加计算资源的数量。例如,在虚拟化环境中,可以通过启动更多的虚拟机实例或容器来增加计算能力。在分布式系统中,可以增加更多的服务器节点来扩展资源。这样可以确保应用程序能够处理更多的请求,并提供更好的性能。负载均衡在水平弹性伸缩中起着重要的作用。负载均衡器将请求流量分发到多个实例上,确保每个实例的负载均衡,避免任何一个实例过载。通过负载均衡,可以提高应用程序的可伸缩性和可用性,同时确保用户请求得到及时的处理。弹性伸缩组是实现水平弹性伸缩的常见机制,它是一组虚拟机实例或容器的集合,它们共同提供服务。弹性伸缩组负责根据负载情况自动调整实例数量,确保集群中的实例数始终满足需求。通过弹性伸缩组,系统可以实现高可用性和弹性,即使某个实例失败,也可以自动替换它,确保应用程序的连续性。
3、垂直弹性伸缩是一种在云计算中常用的资源管理策略。它允许根据应用程序的需求动态地调整单个计算资源的配置,以适应不同的工作负载。当负载增加时,垂直弹性伸缩可以通过增加资源的配置来提高计算能力。例如,可以增加虚拟机实例的内存或cpu核心数,以满足更高的性能需求。这样可以确保应用程序能够处理更多的请求,并保持良好的响应时间。相反,当负载减少时,垂直弹性伸缩可以通过减少资源的配置来降低成本。例如,可以减少虚拟机实例的内存或cpu核心数,以避免资源的浪费。这种灵活的资源调整能够根据实际需求进行动态的配置变更。垂直弹性伸缩是一种根据应用程序的需求调整单个计算资源配置的资源管理策略。它可以提高应用程序的性能和可用性,并在负载波动时实现资源的有效利用。
4、云计算的快速发展为现代信息技术提供了强大的支持和基础设施。弹性伸缩作为云计算中关键的资源管理策略,旨在根据实时负载需求调整云资源的数量和规模,以满足用户的需求并提供最佳的性能和资源利用率。然而,传统的弹性伸缩方法在面对复杂和动态的环境时面临一些挑战,例如缺乏对不确定性和动态性的适应能力。
技术实现思路
1、针对上述技术问题,本发明提出了一种基于maddpg(multi-agent deepdeterministic policy gradient)算法的混合式云资源弹性伸缩系统及运行方法,用于云资源水平与垂直混合式弹性伸缩系统的优化,本发明云资源弹性伸缩系统可以智能地适应复杂和动态的环境,以较短的响应时间,及时提供足够的资源满足应用程序的需求。并且在满足性能需求的同时降低云服务商运营成本。
2、本发明是通过如下技术方案来实现的:
3、一种基于maddpg算法的混合式云资源弹性伸缩系统,所述系统包括集群负载监控中心模块、maddpg决策中心设计模块,云资源调控中心模块和下游接口对接模块,maddpg决策中心模块有基于maddpg算法的多智能体强化学习模型;maddpg决策中心设计模块与集群负载监控中心模块、maddpg决策中心设计模块有信号连接,云资源调控中心模块与下游接口对接模块有信号连接。
4、进一步,所述的maddpg决策中心设计模块中采用了智能体分组模式,分为水平伸缩智能体组与垂直伸缩智能体组,其中水平伸缩智能体组只负责水平弹性伸缩,垂直伸缩智能体组只负责垂直弹性伸缩。
5、进一步,所述集群负载监控中心模块能够实现cpu负载监测、gpu负载监测、内存负载监测、存储负载监测和网络负载监测。
6、进一步,所述的maddpg决策中心设计模块包括环境建模,所述环境建模包括状态空间设计、动作空间设计、奖励函数设计和多智能体设计。
7、进一步,所述云资源调控中心模块的功能包括虚拟机cpu扩容与缩容、虚拟机gpu扩容与缩容、虚拟机内存扩容与缩容、虚拟机存储扩容与缩容、虚拟网络储扩容与缩容和增加与减少虚拟机数量。
8、进一步,所述的下游接口对接模块将各云平台的包括认证与鉴权接口、api调用和数据交互接口、错误处理与异常情况处理接口、监控与同步接口在内的接口封装整合为一个通用云平台接口,实现跨平台接口调用。
9、本发明提供所述系统的运行方法,maddpg决策中心模块内基于深度神经网络进行决策的多智能体通过观察环境进行动作决策,得到一组动作,同时执行这一组动作也会使云环境发生变化,这个变化向好的方向发展智能体就会得到正反馈,反之,如果向不好的方向发展会得到一个负反馈,智能体得到反馈后会进行学习与思考,优化动作决策策略;
10、maddpg决策中心模块首先通过调用集群负载监控中心模块的接口,对集群负载监控中心模块进行观测,进而获取当前集群负载监控中心模块内虚拟机的实时负载情况,进而通过深度强化学习进行动作决策,由于这一部分是多智能体协同决策,会形成一组动作集合,然后会调用云资源调控中心模块进行云资源水平弹性伸缩与垂直弹性伸缩;
11、最后云资源调控中心模块会通过调用下游接口对接模块实现各平台api控制,在各个云平台上完成云资源的扩容与缩容。
12、进一步,深度强化学习训练过程采用了协同训练和经验回放机制,在每个时间步,每个智能体根据自己的actor网络选择动作,并与环境模型交互;智能体的经验存储在共享的经验回放缓冲区中;然后,从经验回放缓冲区中随机采样一批经验,用于更新每个actor和critic网络的参数;更新过程中,各个critic网络通过最小化与实际奖励之间的误差来学习状态值函数,而各个actor网络则通过最大化critic网络估计的状态值函数来更新策略,这种协同学习和经验回放的结合,使得智能体能够在多智能体环境中协作并优化动作选择策略,达到协同决策的目标;
13、进一步,所述的智能体分组模式:将所有虚拟机或容器分成n组,每组有m个实例,满m个实例的组为垂直伸缩智能体和不满m个实例的组为水平伸缩智能体。当水平伸缩智能体达到m个实例时,变成垂直伸缩智能体,同时添加一个空的水平伸缩智能体;反之当垂直伸缩智能体不足m个实例时,则变成水平伸缩智能体,通过限制m的大小使每个智能体的状态空间和动作空间都是确定的。
14、进一步,所述的集群负载监控中心模块的工作步骤如下:
15、第一步、初始化程序,集群负载监控中心程序开始运行后进入监听状态,等待决策中心的指令,maddpg决策中心向集群负载监控中心发送开始监听指令或结束指令;
16、第二步、集群负载监控中心模块收到开始监控指令后,注册监控线程;
17、第三步、监控线程会收集集群负载监控中心模块中各虚拟机的包括cpu利用率、gpu利用率、内存利用率、存储利用率、网络利用率在内的负载信息,
18、第四步、集群负载监控中心模块整理收集到的所有负载信息发送给maddpg决策中心,如果发送成功,回到第三步,进行循环操作;反之,发送失败结束监控线程并重新注册监控线程;
19、第五步、如果集群负载监控中心模块监听到maddpg决策中心发来的结束监听指令,会结束进程,结束集群负载监控程序。
20、进一步,所述的maddpg决策中心模块实施方法:
21、第一步、等待人工指令,人工开始运行maddpg决策中心;
22、第二步、运行多智能体深度强化学习maddpg算法的决策中心程序,并且初始化maddpg算法的多智能体强化学习模型;
23、第三步、向集群负载监控中心模块发送开始监控指令,等待集群负载监控中心模块发送过来的所有负载信息。
24、第四步、获取集群负载监控中心模块发送过来的负载信息,整理这些负载信息成为多智能体状态信息;
25、第五步、将整理好的状态信息,通过maddpg算法的多智能体强化学习模型获取所有智能体决策后得到的动作集合;
26、第六步、将maddpg算法的多智能体强化学习模型决策得到的动作集合发送给云资源调控中心模块,通过云资源调控中心模块完成混合式云资源弹性伸缩;
27、第七步、获取资源调度后集群负载信息,计算奖励反馈;
28、第八步、存储第四步至第七步获得的状态集合、动作集合、奖励集合;
29、第九步、更新maddpg算法的多智能体强化学习模型;重新运行第四步。
30、进一步,第五步的操作进行水平弹性伸缩,增加或减少虚拟机的动作;当水平伸缩组容量超过上限会自动变成垂直伸缩组,执行垂直伸缩的动作,并且重新创建一个水平伸缩组,执行水平伸缩的动作;当垂直伸缩组出现空缺,该垂直伸缩组会自动变成水平伸缩组,执行水平伸缩的动作。
31、进一步,结束maddpg决策中心程序的运行,需要进行人工干预,保存当前maddpg网络模型,并销毁程序。
32、所述的云资源调控中心的运行方法如下:
33、第一步、初始化云资源调控中心程序,云资源调控中心的所有操作都按照监听决策中心传递的指令表达式运行;
34、第二步、等待决策中心传递的指令,指令分为普通操作指令与资源调控指令,普通指令实现重启程序与结束程序的操作;资源调控指令分为对某虚拟机某资源的定量调控的操作和增减虚拟机的操作;
35、第三步、与下游云平台通过下游接口对接模块进行交互;
36、第四步、如果下游接口对接模块调用成功,会调用监控与同步接口,观测当前集群负载并且将集群负载信息发送给maddpg决策中心,供其计算奖励函数;反之,下游接口对接模块调用失败,会调用错误与异常处理接口,检测问题,并重新调用下游接口对接模块完成maddpg决策中心发来的操作指令。
37、当收到maddpg决策中心发来的结束程序的指令,会运行销毁程序,结束云资源调控中心的运行。
38、本发明与现有技术相比的有益效果:本发明通过智能体之间的学习和协作,使弹性伸缩系统能够自适应地调整云资源的配置,以适应不同的环境和负载情况。基于深度强化学习的多智能体算法利用了深度神经网络的强大表征能力和强化学习的优化能力。多智能体通过与环境的交互和奖励信号的反馈,逐渐学习到如何根据当前环境状态和负载情况来调整资源的配置,以达到系统性能的最优化。通过多智能体不断地学习和优化,本云资源弹性伸缩系统可以智能地适应复杂和动态的环境,以较短的响应时间,及时提供足够的资源满足应用程序的需求。并且在满足性能需求的同时降低云服务商运营成本。
39、maddpg(multi-agent deep deterministic policy gradient)是一种多智能体强化学习算法,用于解决多智能体之间的协同决策问题。它结合了深度强化学习和确定性策略梯度方法,通过引入对其他智能体策略的建模来实现合作与竞争。maddpg算法使用独立智能体框架,每个智能体有自己的观察状态和动作空间,以及一个独立的深度神经网络来近似策略函数。每个智能体的策略网络通过最大化期望累积回报来进行训练,采用确定性策略梯度方法进行策略优化。与单智能体的深度确定性策略梯度(ddpg)算法不同,maddpg算法考虑了其他智能体的策略。每个智能体的策略网络不仅接收自身的观察状态,还接收其他智能体的观察状态作为输入,从而实现协同决策。通过学习其他智能体的策略,智能体可以改进自己的决策,实现更好的协同效果。为了提高训练的效率和稳定性,maddpg算法使用经验回放机制和目标网络。经验回放机制将智能体的经验存储在一个共享的经验回放缓冲区中,通过随机抽取样本进行训练。目标网络是策略网络的延迟副本,用于计算目标q值,通过软更新方式逐渐调整目标网络的参数,提高训练的稳定性。maddpg算法在多智能体协同决策问题中具有广泛的应用,例如多智能体协同控制、多智能体交通管理等领域。它能够处理多智能体之间的合作与竞争,并学习出一组策略,使得整体系统达到更好的性能和效果。
40、本发明将分组思想应用于多智能体云资源弹性伸缩系统。解决了现有技术由于云资源调控中心进行水平伸缩时会导致虚拟机数量不确定,进而导致强化学习建模过程中无法确定状态空间与动作空间的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!